溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了Pycharm安裝scrapy及初始化爬蟲項目的方法的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇Pycharm安裝scrapy及初始化爬蟲項目的方法文章都會有所收獲,下面我們一起來看看吧。
1、打開cmd命令窗口,輸入:pip install Scrapy。
2、安裝成功之后會顯示下面字符,表示未將scrapy設置到環境變量。

3、配置環境變量:右鍵我的電腦-->屬性-->高級設置--->環境變量---->系統變量中的Path--->編輯--->添加--->將上文中黃色的路徑添加到環境變量即可。
4、scrapy安裝完畢。
1、創建一個普通的Pycharm項目,然后找到下面的terminal

2、輸入命令scrapy startproject 模塊名稱(可以自己隨便起,我以名為mine為例),成功之后你會發現自己的項目中多了一個mine的包文件。
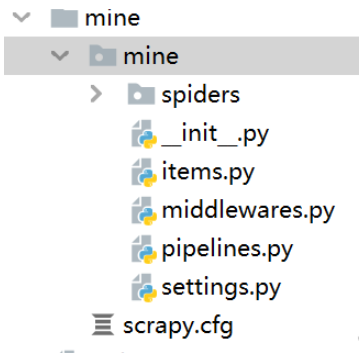
3、上述操作成功后終端會顯示下圖文字:此時我們輸入cd那條命令。進入目標文件。

4、這時就可以創建爬蟲目標文件啦,
輸入scrapy genspider 爬取名 網站域名
1、爬取名是自己隨便起的,比如我要爬百度那么我就可以起名為baidu
2、網站域名就是去掉 https:www. 剩下的部分
2和3操作截圖:

5、此時我們會在目錄里看見一個新的py文件:里自動生成如下代碼:

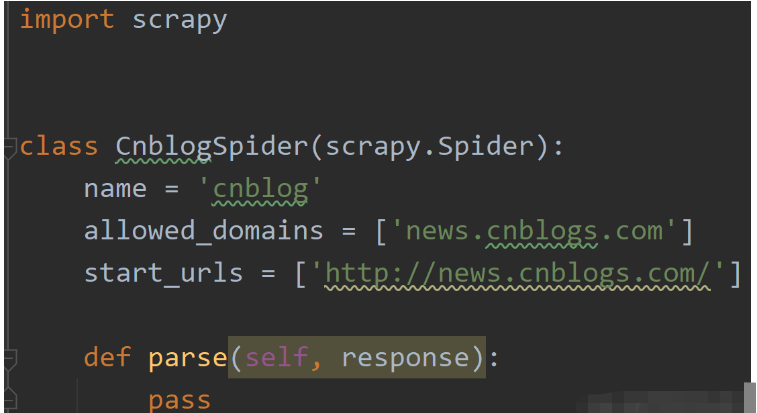
由于pycharm沒有創建scrapy框架的模塊,所以我們想調試scrapy程序時要自己寫一個小腳本來開啟pycharm對scrapy的調試功能。
1、在與mine包同級條件下創建一個main.py文件:

2、mine文件將一下代碼賦值進去:
import os import sys from scrapy.cmdline import execute sys.path.append(os.path.dirname(os.path.abspath(__file__))) execute(["scrapy", "crawl", "cnblog"]) # 第三個參數為自己創建的那個爬取的名稱
關于“Pycharm安裝scrapy及初始化爬蟲項目的方法”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“Pycharm安裝scrapy及初始化爬蟲項目的方法”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





