溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“MySQL表數據操作實例分析”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“MySQL表數據操作實例分析”文章能幫助大家解決問題。
正式開始操作之前,我們先來聊一聊它們的關鍵字:
INSERT
SELECT
UPDATE
DELETE
大家可以先通過help命令來查看一下相關的語法,提前預習一下,方便更深的理解
先來看看之前的表結構:
create table if not exists tb_user( id bigint primary key auto_increment comment '主鍵', login_name varchar(48) comment '登錄賬戶', login_pwd char(36) comment '登錄密碼', account decimal(20, 8) comment '賬戶余額', login_ip int comment '登錄IP' ) charset=utf8mb4 engine=InnoDB comment '用戶表';
在插入之前,我們先來看看平常怎么使用的
insert into table_name[(column_name[,column_name] ...)] value|values (value_list) [, (value_list)]
其實最常用的就這么多,下面我們來舉個例子就明白了
insert into tb_user value(1, 'admiun', 'abc123456', 2000, inet_aton('127.0.0.1'));這樣就插入了一條數據:
auto_increment:自增鍵,在插入數據的時候可以不給當前列指定數據,而且默認情況下我們推薦給主鍵設置自增
inet_aton:ip轉換函數,相對應的還有inet_ntoa()
而且還需要注意一點,如果存在相同的主鍵,那么在插入的時候會出現錯誤
# 主鍵已重復 Duplicate entry '4' for key 'tb_user.PRIMARY'
insert into tb_user(login_name, login_pwd) values('admin1', 'abc123456'),('admin2', 'abc123456')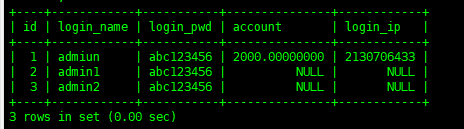
可以看到數據已經插入進來,沒有填充數據的列已NULL填充,關于這一點,我們可以在創建表的時候通過DEFAULT來指定默認值,就是在這個時候使用的
alter table tb_user add column email varchar(50) default 'test@sina.com' comment '郵箱'
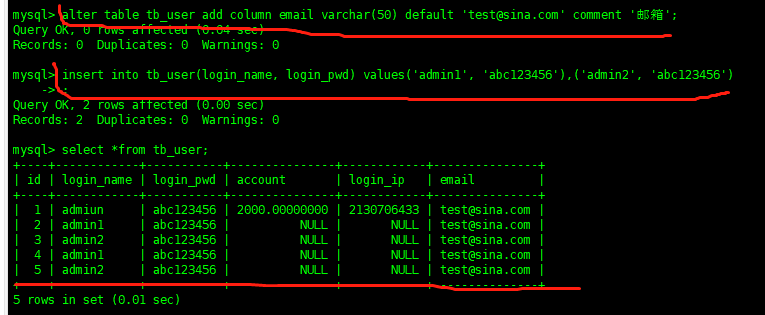
沒有什么比實際動手有說服力的了
這里還有一個點,用到的不是很多,但是相當實用:ON DUPLICATE KEY UPDATE
也就是說如果數據表中存在重復的主鍵,那么就進行更新操作,來看:
insert into tb_user(id, login_name, email) value(4, 'test', 'super@sina.com') on duplicate key update login_name = values(login_name), email = values(email);

對比上面的數據,很容易就會發現數據不一樣了
values(列名): 會取出前面插入的字段的數據
insert into tb_user(id, login_name, email) values(4, 'test', 'super@sina.com'),(5, 'test5', 'test5@sinacom') on duplicate key update login_name = values(login_name), email = values(email);
插入多條數據也是一樣的,就不貼圖了,大家自己動手試一下
插入數據相對而言比較簡單,下面我們來看看修改數據
首先從update語法上來講,這個更簡單:
update table_name set column_name=value_list (,column_name=value_list) where condition
舉個栗子:
update tb_user set login_name = 'super@sina.com' where id = 1
這樣就修改了tb_user下編號為1的loign_name的數據
where后條件也可以多個,按照,分割
當然,如果沒有設置查詢條件的話,那么默認是會修改整張表的數據
update tb_user set login_name = 'super@sina.com',account = 2000
好了,修改數據到這里就結束了,很簡單
刪除數據分為:
刪除指定數據
清空整張表
如果只是想刪除某些數據,可以通過delete來刪除,還是來舉個栗子:
delete from tb_user where login_ip is null;
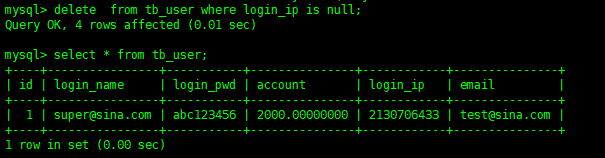
這樣就刪除了指定條件的數據
那么,如果我們執行刪除條件,但是不設置條件呢?下面我們來看一看
先執行
insert操作插入幾條數據
delete from tb_user ;

可以看到,刪除了全部的數據
但其實還有一種方式可以清空整張表,就是通過truncate的方式,這種方式的效率更高
truncate tb_user;
最后就不貼圖了,肯定沒問題的
查詢數據分為多種情況,組合使用可以有N中存在,所以說這是最復雜的一種方式,下面我們一一來介紹
其實如果從語法上來看:查詢語法關鍵點只會包含如下幾點:
SELECT [DISTINCT] select_expr [, select_expr] FROM table_name WHERE where_condition GROUP BY col_name HAVING where_condition ORDER BY col_name ASC | DESC LIMIT offset[, row_count]
記住這些關鍵點,查詢就相當簡單了,下面我們先來看個簡單的操作
select * from tb_user; -- 按照指定字段排序 asc: 正序 desc: 倒序 select * from tb_user order by id desc;
一共插入了44條數據,沒有全部截圖
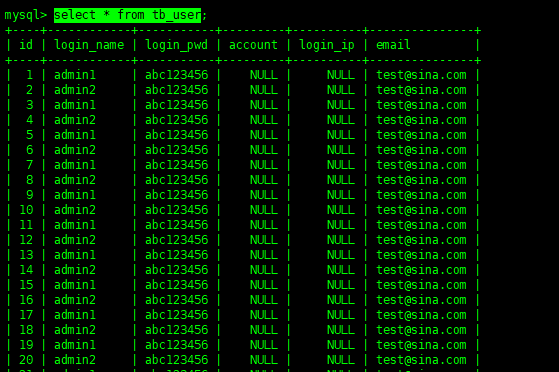
當前SQL會查詢出表中全部數據,而跟在select后面的*表示:列出全部的字段,如果我們只是想列出某些列的話,那么將它換成指定的字段名就好:
select id, login_name, login_pwd from tb_user;
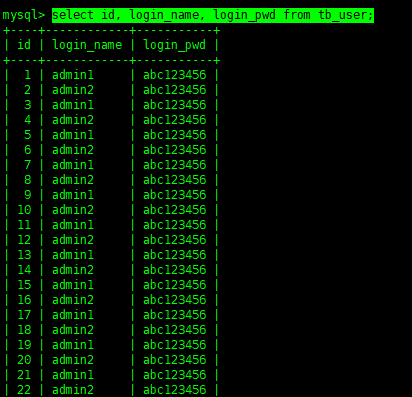
就是這么簡單
當然了,還記得這個關鍵字么:DISTINCT,我們來實驗一下:
select distinct login_name from tb_user;
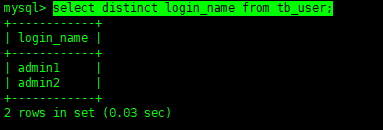
意思已經很明顯了,沒錯,就是去重操作。
但是我要告訴大家的是,distinct關鍵字如果作用在多個字段的話,那么只有在多個字段組合的情況下重復才會進行生效,舉個栗子:
select distinct id,login_name from tb_user;
只有在 id + login_name有重復的時候會生效
在MySQL中內置的聚合函數,對一組數據執行計算,并返回單條值,在特殊場景下有特殊的作用
可以加where條件
-- 查詢當前表中的數據條數 select count(*) from tb_user; -- 查詢當前表中指定列最大的一條 select max(id) from tb_user; -- 查詢當前表中指定列最小的一條 select min(id) from tb_user; -- 查詢當前表中指定列的平均值 select avg(account) from tb_user; -- 查詢當前表中指定列的總和 select sum(account) from tb_user;
除了聚合函數之外,還包含很多普通函數,這里就不一一列舉了,給出 官方文檔,用的時候具體查
看到了第一個例子是不是感覺其實查詢沒有那么難。上面的例子都是查詢出全部數據,下面我們要加一些條件進行篩選,這里就用到了我們的where語句,記住一點:
條件篩選是可以有多個的
我們可以通過如下方式進行條件判斷
select * from tb_user where login_name = 'admin1' and login_pwd = 'abc123456';
很多情況下,column_name = column_value是我們用到更多的查詢方式,這種方式我們可以稱為等值查詢,
而且注意到,在條件之前我是通過and來進行關聯的,Java基礎不錯的小伙伴肯定也記得&&,都是表示并且的意
既然有and,那么與之相反的肯定就是or了,表示只要兩者滿足其中一條就好
select * from tb_user where login_name = 'admin1' or login_pwd = 'abc123456';
除了=匹配的方式,還有其他更多的方式,<,<=,>,>=
和我們認知中不一樣的是:<>表示不等于
不過這些使用方式都是一樣的
在某些特定的情況下,如果想要查詢出一批數據,可以通過in來進行查詢
select * from tb_user where id in(1,2,3,4,5,6);
在in中,相當于傳入的是一個集合,然后查詢指定集合的數據,在很多情況下,這條sql還可以這么寫
select * from tb_user where id in ( select id from tb_user where login_name = 'admin1' );
除了in,還有not in與之相反:表示要查詢出來的不包含這些指定的數據
看完了等值查詢,我們再來看一個模糊查詢:
只要字段數據中包含查詢的數據,就能夠匹配到數據
select * from tb_user where login_name like '%admin%'; select * from tb_user where login_name like '%admin'; select * from tb_user where login_name like 'admin%';
like就是我們模糊查詢中的關鍵成員,而后面的查詢關鍵字分為三種情況:
%admin%:%夾著查詢關鍵字表示只要數據中包含admin就能匹配到
%admin: 任意關鍵字開頭,只要是admin結尾的數據都能匹配到
admin%:必須是admin開頭,其他的隨意,這樣的數據就能匹配到
更多的推薦采用這種方式,如果查詢列設置了索引的話,其他方式會讓索引失效
查詢當前表會發現,數據中的某些列是NULL值,如果我們在查詢過程中向要過濾掉這些數據,我們可以這么做:
select * from tb_user where account is not null; select * from tb_user where account is null;
is not null就是其中的關鍵點,與之相對的還有is null,意思正好相反
很多情況下,如果我們想要通過時間段來匹配查詢,那么我們可以這樣做:
tb_user表沒有時間字段,這里添加了一個字段:create_time
select * from tb_user where create_time between '2021-04-01 00:00:00' and now();
**now()**函數表示當前時間
between之后表示開始時間,and之后表示結束時間
我從一個面試題來聊一聊這個查詢吧:
場景是一樣的,但是SQL不一樣 (關注重點,看題)
create table test( id int(10) primary key, type int(10) , t_id int(10), value varchar(5) ); insert into test values(100,1,1,'張三'); insert into test values(200,2,1,'男'); insert into test values(300,3,1,'50'); insert into test values(101,1,2,'劉二'); insert into test values(201,2,2,'男'); insert into test values(301,3,2,'30'); insert into test values(102,1,3,'劉三'); insert into test values(202,2,3,'女'); insert into test values(302,3,3,'10');
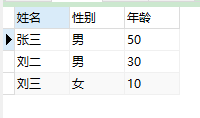
請寫出一條SQL展示如下結果:
姓名 性別 年齡
--------- -------- ----
張三 男 50
劉二 男 30
劉三 女 10
對比常規查詢,可以說我們需要重新定義新的屬性列來展示,所以需要需要通過判斷來完成屬性列的轉換
先一步一步的來,既然需要判斷,那么就通過case .. when .. then .. else .. end來
SELECT CASE type WHEN 1 THEN value END '姓名', CASE type WHEN 2 THEN value END '性別', CASE type WHEN 3 THEN value END '年齡' FROM test
看看,最終成了這個德行
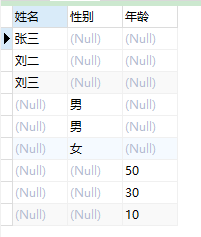
再下一步,我們就需要對全部數據進行聚合,根據前面了解到的聚合函數,我們可以選擇使用max()
SELECT max(CASE type WHEN 1 THEN value END) '姓名', max(CASE type WHEN 2 THEN value END) '性別', max(CASE type WHEN 3 THEN value END) '年齡' FROM test GROUP BY t_id; -- 第二種語法 SELECT max(CASE WHEN type = 1 THEN value END) '姓名', max(CASE WHEN type = 2 THEN value END) '性別', max(CASE WHEN type = 3 THEN value END) '年齡' FROM test GROUP BY t_id;
這樣我們就完成了行轉列,之后如果有遇到這樣的需求,我們也可以使用相同的方式來實現:
主要的是要找到其中數據的規律
如果單純的只是聚合的話,那么最終只能展示出一條數據,所以這里我們需要進行分組
GROUP BY不了解沒關系,后面我們會詳細聊到
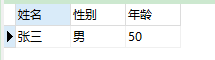
除了采用case之外,還有其他的方式我們來看看
SELECT max(if(type = 1, value, '')) '姓名', max(if(type = 2, value, '')) '性別', max(if(type = 3, value, 0)) '年齡' FROM test GROUP BY t_id
if()表示如果條件滿足,就返回第一個值,否則就返回第二個值
除此之外,如果我們想要給NULL值的數據查詢出默認值,可以通過ifnull()來操作
-- 如果`account`為`null`,那么顯示為0 select ifnull(account, 0) from tb_user;
現在上面的查詢都是匹配出符合條件的全部數據,如果在實際開發中數量很大的情況下這種方式很可能會將服務器拖垮,所以這里我們要將數據一頁一頁的顯示出來
在MySQL中,通過limit關鍵字來進行分頁
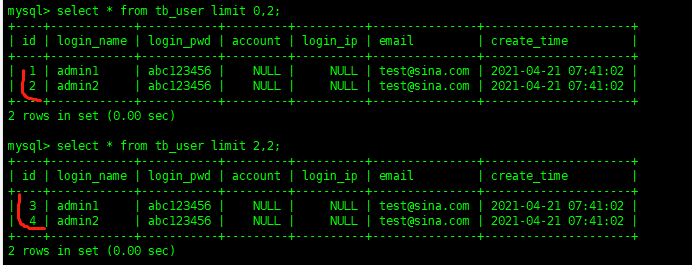
select * from tb_user limit 0,2
前一個參數表示開始位置,后一個參數表示顯示條數
有這么一個場景:MySQL中有2000W的數據,現在要分頁顯示第1000W之后的10條數據,那么通過常規的方式是這樣的:
select * from tb_user limit 10000000,10
這里我們來說一說limit是如何進行分頁的
limit在分頁的時候會查詢到需要顯示的開始位置,然后丟棄掉查詢出的數據,從那個位置開始,繼續向后讀取顯示條數的數據
所以說如果開始位置越大,那么需要讀取的數據就越多,查詢時間也就越長
這里給出一個優化方案:給定數據的查詢范圍,最好是索引列(索引列可以加快查詢效率)
select * from tb_user where id > 10000000 limit 10; select * from tb_user where id > 10000000 limit 0 10;
limit后如果只跟一個參數,那么這個參數只表示顯示條數
目前我們的查詢都是單表查詢,我們在工作中的查詢SQL基本上都涉及到多表間的操作,這樣我們就需要進行多表關聯查詢
下面我們再簡單創建一張表,然后再看看如果進行多表關聯查詢
create table tb_order( id bigint primary key auto_increment, user_id bigint comment '所屬用戶', order_title varchar(50) comment '訂單名稱' ) comment '訂單表'; insert into tb_order(user_id, order_title) values(1, '訂單-1'),(1, '訂單-2'),(1, '訂單-3'),(2, '訂單-4'),(5, '訂單-5'),(7, '訂單-71');
想要進行關聯查詢的話,SQL是這么操作的
select * from tb_user, tb_order where tb_user.id = tb_order.user_id;
等值查詢也就是說:兩個表中包含相同的列名,在查詢的時候匹配相同列名
對比等值查詢,還存在非等值查詢:兩個表中沒有相同的列名,但是某一個列在另一張表的列的范圍之中
范圍查詢我們已經介紹過了,通過 **between … and …**來查詢
所謂的子查詢我們可以理解為:
嵌套在其他SQL語句中的完整SQL語句
還是上面的查詢,我們換一種方式
select * from tb_order where user_id = (select id from tb_user where id = 1); select * from tb_order where user_id in ( select id from tb_user);
根據子查詢返回結果的不同,子查詢也可以分為不同類型
SQL1只返回了一條數據,而且在查詢的時候通過等值來判斷的,就可以稱為單行子查詢
SQL2很明顯,就是多行子查詢
子查詢除了用在where條件之后,也可以用在顯示列中
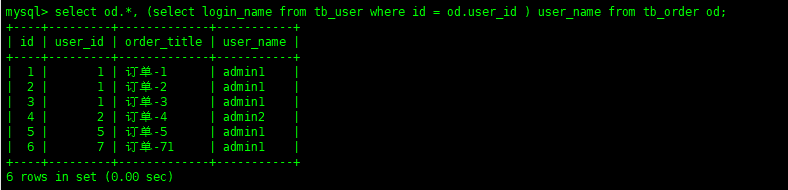
select od.*, (select login_name from tb_user where id = od.user_id ) from tb_order od;
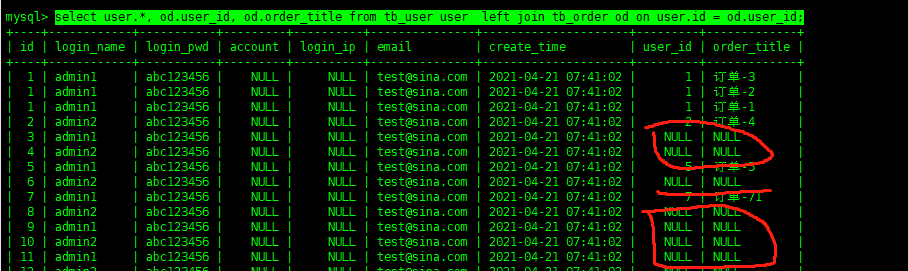
左關聯查詢已left join為主要關鍵點,兩表中的關鍵字段通過on來進行關聯,通過這種方式查詢出的數據已左側表為主,如果其關聯的表中不存在數據,那么就返回NULL
select user.*, od.user_id, od.order_title from tb_user user left join tb_order od on user.id = od.user_id;
右關聯已right join為主要關鍵點,數據已右側的關聯表為主,其他的操作方式和左關聯一樣
select user.*, od.user_id, od.order_title from tb_user user right join tb_order od on user.id = od.user_id;

而且可以看出來,在數據的展示上,右側表沒有在左側表有對應數據的話,那么左側表的數據是不會顯示出來的
如果在實際工作中的查詢都是這么簡單的話,簡直不要太舒服
前面聊到了聚合函數,聚合函數對一組數據執行計算,并返回單條值。
很多情況下,如果我們想通過聚合函數對表中數據進行分組操作的話,那么就需要采用group by來進行查詢
就目前表中的數據,我們可以做一個場景:
計算出表中每個登錄賬號有多少條記錄
select count(*), login_name from tb_user group by login_name
其實每個查詢語法的使用都非常簡單
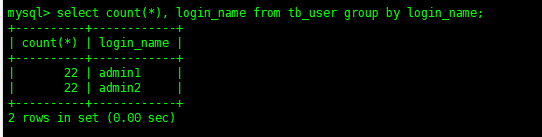
如果想要對聚合查詢出來的數據進行條件篩選,不能使用where來查詢,需要通過having來篩選
select count(*), login_name from tb_user group by login_name having login_name = 'admin1';

還需要注意的是:
當前列沒有通過group by 分組,那么無法通過having來查詢
語法問題

如果我們在操作的時候遇到了這樣的問題:這是由于顯示列中包含沒有分組的列,由sql_mode的模式來決定的。先來查看下默認設置
主要的是語法不規范
-- ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION select @@sql_mode;

set sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';
根據提示修改就好
關于“MySQL表數據操作實例分析”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





