溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇“MySQL索引優化之適合構建索引的情況有哪些”文章的知識點大部分人都不太理解,所以小編給大家總結了以下內容,內容詳細,步驟清晰,具有一定的借鑒價值,希望大家閱讀完這篇文章能有所收獲,下面我們一起來看看這篇“MySQL索引優化之適合構建索引的情況有哪些”文章吧。
在where后面的過濾字段上建立索引(select/update/delete后面的where都是適用的),使用索引加快過濾效率,不用進行全表掃描
在具有唯一要求的字段上添加唯一索引,加快查詢效率,查到即可直接返回
group by或者order by后面的字段添加索引,由于索引是排好序的,所以建立索引就等同于在查詢之前已經是排好序了(這里需要注意建立的聯合索引建立中字段的順序,可以結合具體案例場景7進行學習)
在DISTINCT(去重字段)后面的字段添加索引,由于建立了索引,那么相同的數據就是挨在一起的,所以就可以進行快速的去重操作,否則可能就需要將相同的數據找出來在進行去重操作
在多表連接join的時候在連接的字段上建立索引(小表驅動大表)
取字符串一定前綴建立索引(不是用整個字符串作為索引,否則將會占用太大的空間)
在頻繁使用的列上建立索引(可以建立聯合索引,同時最頻繁使用的字段應該在聯合索引的最左側,最左側原則)
在區分度高的列上建立索引(主鍵的區分度最高,因為所有的鍵都是唯一的)
場景一:在where字段后面的字段建立索引
-- 描述:當where中有多個條件需要進行匹配的時候,那么可以創建聯合索引,這樣所有的條件都可以使用索引,大大提高了檢索的效率 select * from student_info where student_id = 1; -- 當然數據量比較大的時候給where后面的字段添加索引 create index student_id_index on student_info (student_id)
未添加索引前,耗費0.383秒,基本遍歷整個表

添加索引后,耗費0.001秒,使用了索引(但是創建索引的時候會耗費一定時間)
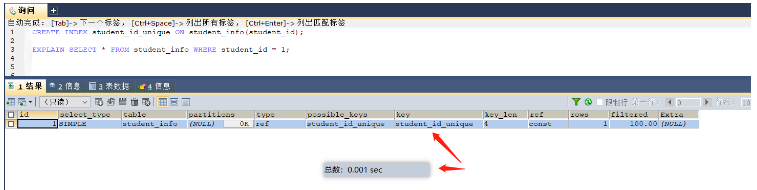
在頻繁的查詢的業務中可以對where篩選的字段建立索引,如果where篩選的字段有多個還可以建立聯合索引
場景二:在具有唯一性約束的字段上建立唯一索引(查找到目標即可返回不用繼續查找)
select * from student_info where id = 1001; -- 因為學號是唯一的,所以可以在學號這個字段上添加唯一所用 create index id_unique on student_info(id);
具有唯一性約束的字段上就可以建立唯一索引,雖然建立了唯一索引對insert操作有一定的影響(需要判斷新增的數據是否已經在表中),但是建立唯一索引對于查詢的效率是顯著提升的,例如上面的例子,因為建立了唯一索引,一旦查找到id為1001的學生信息之后就不需要判斷數據庫中是否還有id等于1001的學生(只有唯一一份),直接返回信息即可,如果沒有建立索引,那么就需要全表掃描
場景三:經常group by和order by的字段上建立索引(因為索引本身就是排好序的,相當于查詢之前就已經進行了排序)
select * from student_info order by name; -- 這里就可以給name字段進行索引的添加 select * from student_info group by class_id; -- 這里就可以給class_id字段添加索引
建立索引前,耗時0.501秒,使用的是所有數據在內存中排序
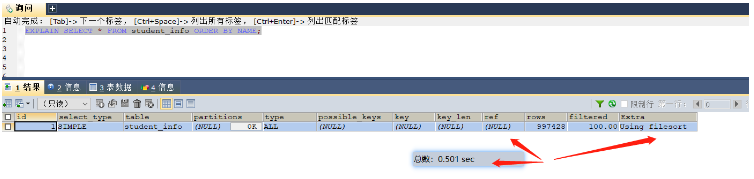
建立索引后,耗時0.01秒
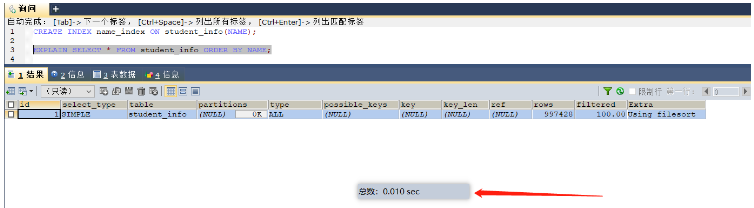
場景四:在DISTINCT后面的字段添加索引(索引已經將相同的字段排好序,去重效率更高)
select distinct(student_id) from student_info; -- 這里就可以根據student_id字段建立索引 create index student_id_index on student_info;
建立了索引,那么默認就是按照索引字段的升序排列的,那么相同值的字段也就排列在一起了,那么去重也就變得簡單、高效
場景五:在join多表連接大表中的連接字段建立索引
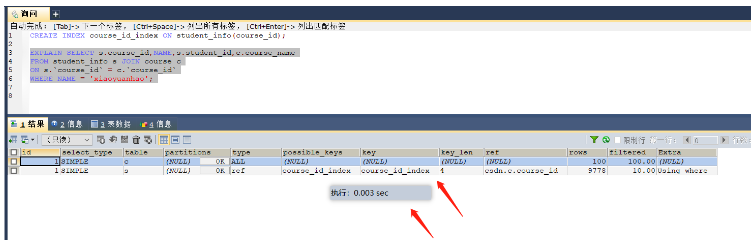
SELECT s.course_id,NAME,s.student_id,c.course_name FROM student_info s JOIN course c ON s.`course_id` = c.`course_id` WHERE NAME = 'xiaoyuanhao'; -- 根據大表驅動小表的原則需要在student_info表的course_id字段上建立索引
沒有建立索引之前,耗時0.697s,沒有使索引
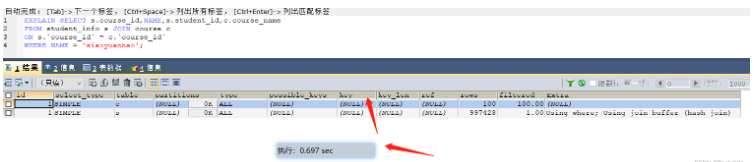
建立索引后,使用了索引,耗時0.003s
小表驅動大表:
通過對小表進行逐一遍歷,同時在大表中的連接字段建立索引即可加快查詢,本案例中,每次取出課程表中course_id和學生表中學生的course_id進行連接操作,在學生表中對course_id建立索引即可
場景六:使用字符串的前綴建立索引
create table shop(address varchar(120) not null); alter table shop add index(address(12)); --這里只是對表中的address的前12個字符建立了索引,而不是整個字符串建立索引
前綴建立索引的原因:
由于有些字符串很長,如果為整個字符串建立索引,那么索引將占用很大的空間
由于需要存儲整個字符串,那么數據項就會很大,那么索引樹的深度就會加深,檢索速度下降
雖然可能出現在索引中兩個字符串相同,但是再根據主鍵進行回表操作效率依然比較高
如何確定前綴索引中前綴的長度呢?(也就是如果前綴的長度太短,那么索引的區分度就很低,從多個字符串截取的前綴數據可能都是一樣的,但是如果前綴索引的前綴過長,那么前綴索引的優點就消失了)
引入了區別度的概念,select count(distinct left(索引字段,前綴索引長度) / count(*) from xxx),該值越接近1,那么區分度就越明顯,那么該索引長度就是所求的前綴索引長度
場景七:在頻繁使用的列上建立索引或聯合索引(頻繁使用的字段應該在索引的左側)
select * from xiaoyuanhao where age = 18; select * from xiaoyuanhao where age = 19 and sex = 'man'; select * from xiaoyuanhao where age = 10 and sex = 'man' and password = '123456'; -- 在這里實際上就可以建立age,sex,password的聯合索引,只需要建立一個索引,這三個查詢都是可以使用的 create index age_sex_password_index on xiaoyuanhao(age,sex,password); select * from student_info group by class_id order by name; -- 在這里可以建立class_id和name的聯合索引,但是一定要注意索引的順序,一定是要class_id在前,name在后,因為在select語句中執行的順序是先group by 之后才是 order by 索引如果索引的字段順序是相反的,那么就無法使用索引 create index class_id_name_index on student(class_id,name);
索引建立需要符合順序的原因:
索引字段的順序如果是錯誤的,那么索引就會失效,因為索引實際上是排好序的,如果索引建立的時候是現根據name排好序之后在根據class_id進行排序,那么在面對需要先根據class_id排序再根據name排序的業務就無法進行使用
補充:
在select * from xxx where age = 19 and sex = ‘man’ and password = '123456’這里索引建立的順序不一定是(age,sex,password)因為在實際執行的過程中,優化器會優化執行步驟會按照索引的順序進行查詢,但是group by 和 order by的執行順序是無法改變的,索引必須嚴格的按照順序建立索引,否則索引失效
以上就是關于“MySQL索引優化之適合構建索引的情況有哪些”這篇文章的內容,相信大家都有了一定的了解,希望小編分享的內容對大家有幫助,若想了解更多相關的知識內容,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





