溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章和大家了解一下Pandas數值排序 sort_values()的使用方法。有一定的參考價值,有需要的朋友可以參考一下,希望對大家有所幫助。
參數解釋
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', # last,first;默認是last ignore_index=False, key=None)
參數的具體解釋為:
by:表示根據什么字段或者索引進行排序,可以是一個或多個
axis:排序是在橫軸還是縱軸,默認是縱軸axis=0
ascending:排序結果是升序還是降序,默認是升序
inplace:表示排序的結果是直接在原數據上的就地修改還是生成新的DatFrame
kind:表示使用排序的算法,快排quicksort,,歸并mergesort, 堆排序heapsort,穩定排序stable ,默認是 :快排quicksort
na_position:缺失值的位置處理,默認是最后,另一個選擇是首位
ignore_index:新生成的數據幀的索引是否重排,默認False(采用原數據的索引)
key:排序之前使用的函數
數據值的排序主要使用sort_values(),數字按大小排序,字符按字母順序
Series和DataFrame都支持此方法
import pandas as pd
df = pd.DataFrame([['liver','E',89,21,24,64],
['Arry','C',36,37,37,57],
['Ack','A',57,60,18,84],
['Eorge','C',93,96,71,78],
['Oah','D',65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])
res1 = df.Q1.sort_values()
# DataFrame 需要傳入一個或多個排序的列名
res2 = df.sort_values('Q4')
# 默認排序是升序,但可以指定排序方式
# 下例先按team升序排列,如遇到相同的team再按name降序排列
res3 = df.sort_values(by = ['team','name'], ascending = [True, False])結果展示
df
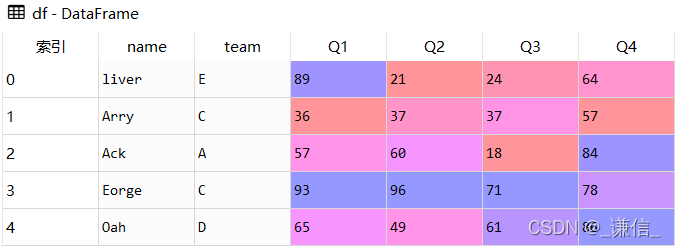
res1
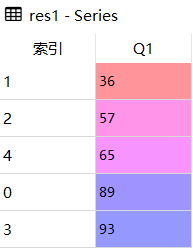
res2
res3

擴展
# 其他常用方法如下:
s.sort_values(ascending = False) # 降序
s.sort_values(inplace = True) # 修改生效
s.sort_values(na_position = 'first') # 空值在前
# df按指定字段排列
df.sort_values(by = ['team'])
df.sort_values('Q1')
# 按多個字段,先排team,在同team內再看Q1
df.sort_values(by = ['mean','Q1'])
# 全降序
df.sort_values(by = ['mean','Q1'], ascending = False)
# 對應指定team升Q1降
df.sort_values(by = ['mean','Q1'], ascending = [True, False])以上就是Pandas數值排序 sort_values()的使用方法的簡略介紹,當然詳細使用上面的不同還得要大家自己使用過才領會。如果想了解更多,歡迎關注億速云行業資訊頻道哦!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





