溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了C語言關鍵字sizeof、unsigned及signed怎么使用的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇C語言關鍵字sizeof、unsigned及signed怎么使用文章都會有所收獲,下面我們一起來看看吧。
sizeof:確定一種類型在開辟空間的時候的大小。
sizeof是關鍵字而不是函數,可以借助編譯器來確定它的身份。
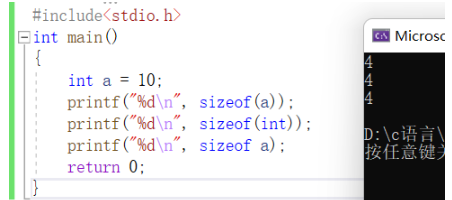
#include<stdio.h>
int main()
{
int a = 10;
printf("%d\n", sizeof(a));
printf("%d\n", sizeof(int));
printf("%d\n", sizeof a);
printf("%d\n", sizeof int);//error
return 0;
}
sizeof(a)可以去掉()說明sizeof不是函數,是關鍵字(操作符),因為函數后面的括號是不能省略的。
sizeof在計算變量所占的空間大小時,可以省略括號,而計算類型大小時,不能省略括號。
注:sizeof操作符里面不能有其他運算,否則達不到預期的結果。
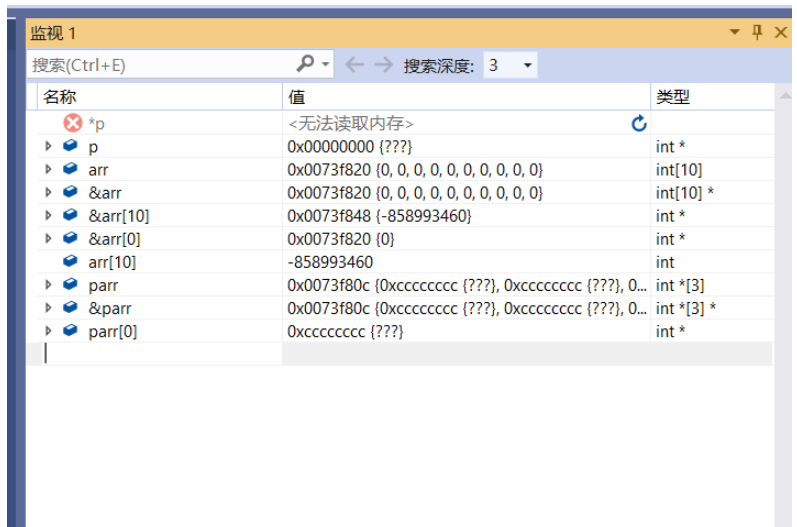
#include<stdio.h>
int main()
{
int* p = NULL;
int arr[10] = { 0 };
int* parr[3];
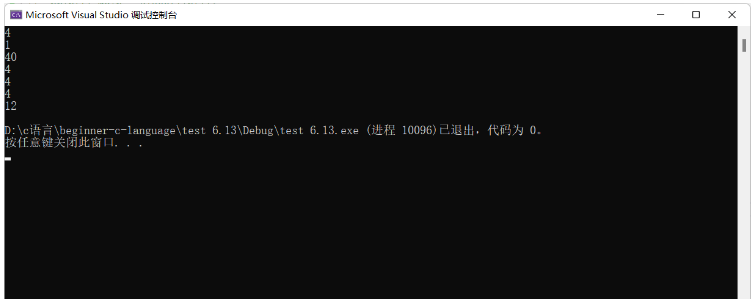
printf("%d\n", sizeof(p));//p是指針變量,指針變量的大小是固定的4或者8
printf("%d\n", sizeof(*p));//指針變量所指的變量所占的內存的大小
printf("%d\n", sizeof(arr));//sizeof(arr)中arr指整個數組,即10個int類型元素。
printf("%d\n", sizeof(arr[10]));//數組越界
printf("%d\n", sizeof(&arr));//&arr取得是整個數組的地址
printf("%d\n", sizeof(&arr[0]));//取的是首元素的地址,相當于指針
printf("%d\n", sizeof(parr));//parr指整個數組。
return 0;
}
指針變量p所指向的變量類型為char,指針數組parr中存儲的指針變量的類型為char時候:
char
unsigned char//無符號的字符類型
//取值范圍是0~255
//無符號表示二進制的最高位不表示正負,該整型只為正數。
//但可以儲存負數,只是值會變成很大的正數
signed char//有符號字符
//取值范圍是-128~127
//因為字符的本質是ASCII碼值,在內存中以ASCII碼值進行存儲,所以劃分到整型家族
short
unsigned short [int]//無符號短整型
signed short [int]//有符號短整型
int
unsigned int//無符號整型
signed int//有符號整型
long
unsigned long [int]//無符號長整型
signed long [int]//有符號整型
long long
unsigned long long [int]//無符號更長的整型
signed long long [int] //有符號更長的整型

char到底是signed char (取值范圍-128~127)還是unsigned char(取值范圍0~255)
標準是為定義的,取決于編譯器的實現,小沐所使用的VS2019環境的char是signed char。
char a;// signed char a 或者 unsigned char a
int 標準定義是 signed int ,有符號整型,4個字節,32個比特位
int a = 10;//signed int a //轉換成二進制是00000000000000000000000000001010
一個變量的創建是要在內存中開辟空間的,空間的大小是根據不同的類型而決定的。
那么,數據在所開辟內存中到底是如何存儲的呢?
計算機存儲數值時時存儲的該數值的二進制的補碼的,而補碼是通過原碼和反碼進行換算得到的。
任何數據在計算機中,都必須轉換成二進制,計算機只認識二進制。
直接將數值按照正負數的形式翻譯成二進制就可以得到原碼。
將原碼的符號位不變,其他位依次按位取反就可以得到反碼。
反碼+1就得到補碼。
int a = 10; //00000000000000000000000000001010 a的原碼 //00000000000000000000000000001010 a的反碼 //00000000000000000000000000001010 a的補碼 //0x0000000a int b = -10; //10000000000000000000000000001010 b的原碼 //0x8000000a //11111111111111111111111111110101 b的反碼 //0xfffffff5 //11111111111111111111111111110110 b的補碼 //0xfffffff6
符號位+數據位
有符號數且正數,原碼,反碼和補碼相同。
有符號數且負數,原碼,反碼和補碼不相同,需要通過計算轉換。計算機內存儲的整型必須是補碼,符號位要參與計算的。
無符號數:沒有符號位,原碼,反碼和補碼相同。
int a = 20;
int b = -10;
我們知道,編譯器為 a 分配四個字節的空間。那如何存儲呢? 首先,對于有符號數,一定要能表示該數據是正數還是負數。所以我們一般用最高比特位來進行充當符號位。 原碼、反碼、補碼 計算機中的有符號數有三種表示方法,即原碼、反碼和補碼。 三種表示方法均有符號位和數值位兩部分,符號位都是用0表示“正”,用1表示“負”,而數值位三種表示方法各不相同。 如果一個數據是負數,那么就要遵守下面規則進行轉化: 原碼:直接將二進制按照正負數的形式翻譯成二進制就可以。 反碼:將原碼的符號位不變,其他位依次按位取反就可以得到了。 補碼:反碼+1就得到補碼。 如果一個數據是正數,那么它的原反補都相同。
無符號數:不需要轉化,也不需要符號位,原反補相同。
對于整形來說:數據存放內存中其實存放的是補碼。
//字面值轉補碼
int a = 20;
//20是正整數
//0000 0000 0000 0000 0000 0000 0001 0100
int b = -10;
//-10是正整數
//1000 0000 0000 0000 0000 0000 0000 1010
//1111 1111 1111 1111 1111 1111 1111 0101
//1111 1111 1111 1111 1111 1111 1111 0110
補碼轉原碼
方法一:先-1,在符號位不變,按位取反。
方法二:將原碼到補碼的過程在來一遍。
原反補轉換需要通過計算機硬件來完成,

可以使用一條硬件電路就能完成原反補碼的轉換。
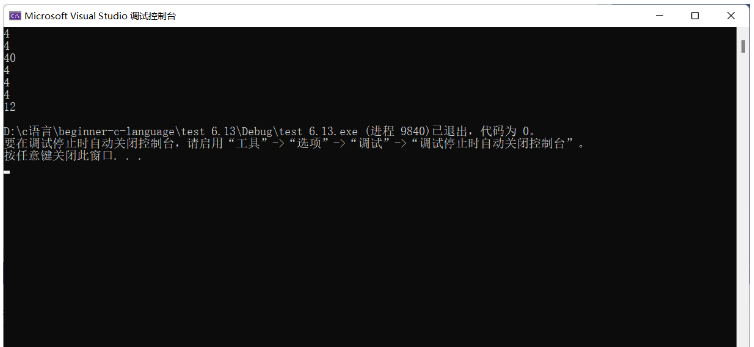
#include<stdio.h>
int main()
{
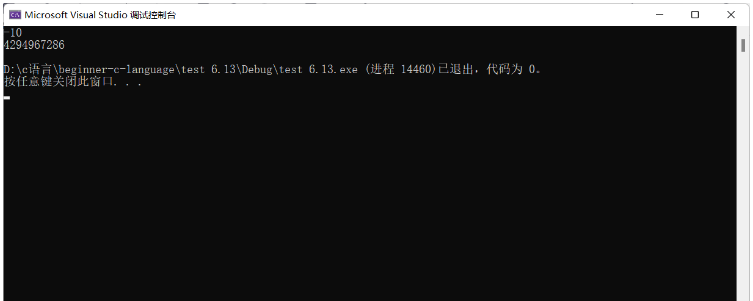
unsigned int a = -10;
//1000 0000 0000 0000 0000 0000 0000 1010-- -10的原碼
//1111 1111 1111 1111 1111 1111 1111 0110-- -10的補碼
printf("%d\n", a);
printf("%u\n", a);
return 0;
}
無符號整型變量a定義時,先有空間,再有內容,先將內容轉換成二進制。 整型再存儲的時候,空間不關心內容的。
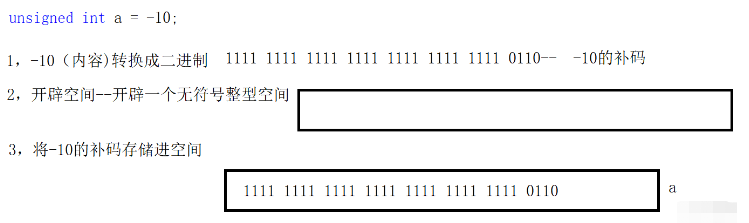
在將數據保存在空間內的時候,數據已經被轉換成二進制的補碼。
數據帶上類型才有意義。類型覺得了如何解釋空間內部保存的二進制序列。
變量的類型什么時候起效果?
在讀取數據的過程中,變量的類型起效果。
//變量的存和取過程的結論:
//存:字面數據必須先轉成補碼,在放入空間當中。所以,所謂符號位,完全看數據本身是否攜帶±號。和變量是否有符號
無關!
//取:取數據一定要先看變量本身類型,然后才決定要不要看最高符號位。如果不需要,直接二進制轉成十進制。如果需要,則需要轉成原碼,然后才能識別。(當然,最高符號位在哪里,又要明確大小端)
口訣:1后面跟n個0,就是2的n次方
67->64++1-->2^6+2^1+2^0
0000 0000 0000 0000 0000 0000 00100 0011
1->2^0
10->2^1
100->2^2
1000->2^3
后面跟n給比特位就是2^n
2^9->1000000000
在計算機系統中,數值一律用補碼來表示和存儲。原因在于,使用補碼,可以將符號位和數值域統一處理;
同時,加法和減法也可以統一處理(CPU只有加法器)。此外,補碼與原碼相互轉換,其運算過程是相同的,不需要額外的硬件電路。
什么大端小端:
大端(存儲)模式,是指數據的低位保存在內存的高地址中,而數據的高位,保存在內存的低地址中;
小端(存儲)模式,是指數據的低位保存在內存的低地址中,而數據的高位,,保存在內存的高地址中。
例如:
0x11223344

為什么有大端和小端:
因為在計算機系統中,我們是以字節為單位的,每個地址單元都對應著一個字節,一個字節為8 bit。但是在C語言中除了8 bit的char之外,還有16 bit的short型,32 bit的long型(要看具體的編譯器),另外,對于位數大于8位的處理器,例如16位或者32位的處理器,由于寄存器寬度大于一個字節,那么必然存在著一個如何將多個字節安排的問題。因此就導致了大端存儲模式和小端存儲模式。
例如:一個 16bit 的 short 型 x ,在內存中的地址為 0x0010 , x 的值為 0x1122 ,那么 0x11 為高字節, 0x22 為低字節。對于大端模式,就將 0x11 放在低地址中,即 0x0010 中, 0x22 放在高地址中,即 0x0011 中。小端模式,剛好相反。我們常用的 X86 結構是小端模式,而 KEIL C51 則為大端模式。很多的ARM,DSP都為小端模式。有些ARM處理器還可以由硬件來選擇是大端模式還是小端模式。
關于“C語言關鍵字sizeof、unsigned及signed怎么使用”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“C語言關鍵字sizeof、unsigned及signed怎么使用”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





