溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了python爬蟲之selenium模塊怎么使用的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇python爬蟲之selenium模塊怎么使用文章都會有所收獲,下面我們一起來看看吧。
selenium 是一套完整的web應用程序測試系統,包含了測試的錄制(selenium IDE),編寫及運行(Selenium Remote Control)和測試的并行處理(Selenium Grid)。Selenium的核心Selenium Core基于JsUnit,完全由JavaScript編寫,因此可以用于任何支持JavaScript的瀏覽器上。
selenium可以模擬真實瀏覽器,自動化測試工具,支持多種瀏覽器,爬蟲中主要用來解決JavaScript渲染問題。
用python寫爬蟲的時候,主要用的是selenium的Webdriver,我們可以通過下面的方式先看看Selenium.Webdriver支持哪些瀏覽器
from selenium import webdrive help(webdriver)
執行結果如下,從結果中我們也可以看出基本山支持了常見的所有瀏覽器:
NAME: selenium.webdriver
PACKAGE CONTENTS:
android (package)
blackberry (package)
chrome (package)
common (package)
edge (package)
firefox (package)
ie (package)
opera (package)
phantomjs (package)
remote (package)
safari (package)
support (package)
webkitgtk (package)
VERSION: 3.14.1
PhantomJS是一個而基于WebKit的服務端JavaScript API,支持Web而不需要瀏覽器支持,其快速、原生支持各種Web標準:Dom處理,CSS選擇器,JSON等等。
PhantomJS可以用用于頁面自動化、網絡監測、網頁截屏,以及無界面測試。
當selenium升級到3.0之后,對不同的瀏覽器驅動進行了規范。如果想使用selenium驅動不同的瀏覽器,必須單獨下載并設置不同的瀏覽器驅動。
各瀏覽器下載地址:
Firefox瀏覽器驅動:geckodriver
Chrome瀏覽器驅動:chromedriver , taobao備用地址
IE瀏覽器驅動:IEDriverServer
Edge瀏覽器驅動:MicrosoftWebDriver
注:webdriver需要和對應的瀏覽器版本以及selenium版本對應。
查看驅動和瀏覽器版本的映射關系:
按照chrome版本對應的driver,直接按照瀏覽器版本去找對應的driver(只對應大版本就行)
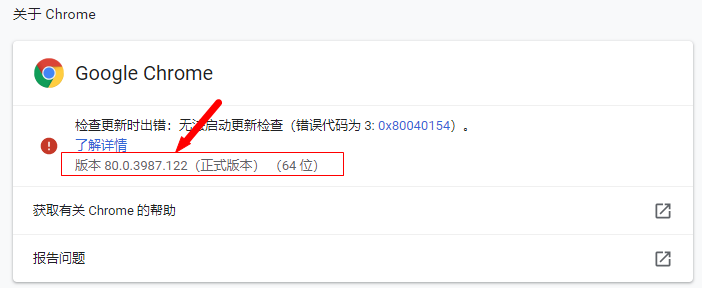
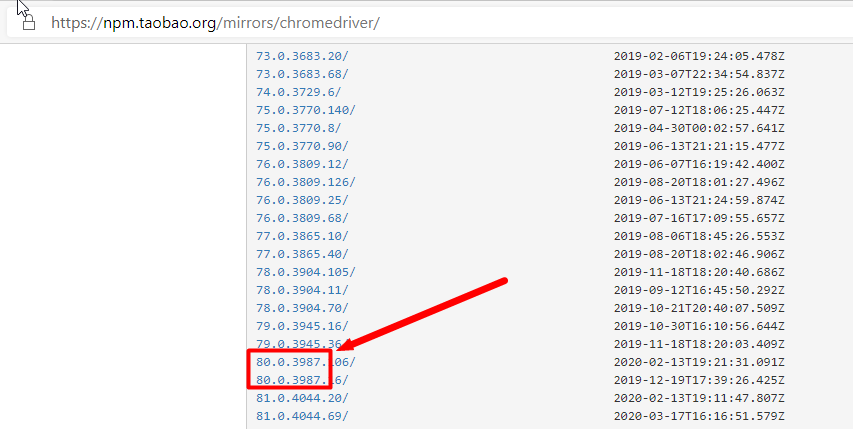
下載之后,解壓到任意目錄(路徑不要有中文)。
瀏覽器驅動文件,(win環境下載解壓后得到的.exe文件)需要放到與python.exe同級目錄中方能使用。或者配置電腦環境變量
可以手動創建一個存放瀏覽器驅動的目錄,如: C:\driver , 將下載的瀏覽器驅動文件(例如:chromedriver、geckodriver)丟到該目錄下。
我的電腦-->屬性-->系統設置-->高級-->環境變量-->系統變量-->Path,將“C:\driver”目錄添加到Path的值中。
上面我們知道了selenium支持很多的瀏覽器,但是如果想要聲明并調用瀏覽器則需要:
這里只寫了兩個例子,當然了其他的支持的瀏覽器都可以通過這種方式調用
from selenium import webdriver browser = webdriver.Chrome() # browser = webdriver.Firefox()
Headless Chrome 是 Chrome 瀏覽器的無界面形態,可以在不打開瀏覽器的前提下,使用所有 Chrome 支持的特性運行你的程序。相比于現代瀏覽器,Headless Chrome 更加方便測試 web 應用,獲得網站的截圖,做爬蟲抓取信息等。相比于較早的 PhantomJS,SlimerJS 等,Headless Chrome 則更加貼近瀏覽器環境。
Headless Chrome 對Chrome版本要求:官方文檔中介紹,mac和linux環境要求chrome版本是59+,而windows版本的chrome要求是60+,同時chromedriver要求2.30+版本。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
chrome_options = webdriver.ChromeOptions()
# 使用headless無界面瀏覽器模式
chrome_options.add_argument('--headless') //增加無界面選項
chrome_options.add_argument('--disable-gpu') //如果不加這個選項,有時定位會出現問題
# 啟動瀏覽器,獲取網頁源代碼
browser = webdriver.Chrome(chrome_options=chrome_options)
mainUrl = "https://www.taobao.com/"
browser.get(mainUrl)
print(f"browser text = {browser.page_source}")
browser.quit()下面代碼運行后,會自動打開Chrome瀏覽器,并登陸百度打印百度首頁的源代碼,然后關閉瀏覽器
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("http://www.baidu.com")
print(browser.page_source)
browser.close()browser.get(<a href="http://www.taobao.com/" rel="external nofollow" rel="external nofollow" target="_blank">http://www.taobao.com</a>)
input_first = browser.find_element_by_id("q")
input_second = browser.find_element_by_css_selector("#q")
input_third = browser.find_element_by_xpath('//*[@id="q"]')
print(input_first)
print(input_second)
print(input_third)
browser.close()這里我們通過三種不同的方式去獲取響應的元素,第一種是通過id的方式,第二個中是CSS選擇器,第三種是xpath選擇器,結果都是相同的。
結果如下:

常用的查找元素方法:
find_element_by_name:通過元素name定位
find_element_by_id:通過元素id定位
find_element_by_xpath:通過xpath表達式定位
find_element_by_link_text:通過完整超鏈接文本定位
find_element_by_partial_link_text:通過部分鏈接文本定位
find_element_by_tag_name:通過標簽定位
find_element_by_class_name:通過類名進行定位
find_element_by_css_selector:通過css選擇器進行定位
舉例:
通過xpath定位,xpath定位有N種寫法,這里列幾個常用寫法:
dr.find_element_by_xpath("//*[@id='kw']")
dr.find_element_by_xpath("//*[@name='wd']")
dr.find_element_by_xpath("//input[@class='s_ipt']")
dr.find_element_by_xpath("/html/body/form/span/input")
dr.find_element_by_xpath("//span[@class='soutu-btn']/input")
dr.find_element_by_xpath("//form[@id='form']/span/input")
dr.find_element_by_xpath("//input[@id='kw' and @name='wd']")通過css定位,css定位有N種寫法,這里列幾個常用寫法:
dr.find_element_by_css_selector("#kw")
dr.find_element_by_css_selector("[name=wd]")
dr.find_element_by_css_selector(".s_ipt")
dr.find_element_by_css_selector("html > body > form > span > input")
dr.find_element_by_css_selector("span.soutu-btn> input#kw")
dr.find_element_by_css_selector("form#form > span > input")xpath的使用方法
1. 第一種方法:通過絕對路徑做定位(相信大家不會使用這種方式)
By.xpath(“html/body/div/form/input”)
2. 第二種方法:通過相對路徑做定位,兩個斜杠代表相對路徑
By.xpath(“//input//div”)
3. 第三種方法:通過元素索引定位
By.xpath(“//input[4]”)
4. 第四種方法:使用xpath+節點屬性定位(結合第2、第3中方法可以使用)
By.xpath(“//input[@id='kw1']”) By.xpath(“//input[@type='name' and @name='kw1']”)
5. 第五種方法:使用部分屬性值匹配(最強大的方法)
By.xpath(“//input[start-with(@id,'nice')]”) By.xpath(“//input[ends-with(@id,'很漂亮')]”) By.xpath(“//input[contains(@id,'那么美')]”)
6. 第六種方法:使用前集中方法的組合
By.xpath(“//input[@id='kw1']//input[start-with(@id,'nice']/div[1]/form[3])
下面這種方式是比較通用的一種方式:這里需要記住By模塊所以需要導入。
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get("http://www.taobao.com")
input_first = browser.find_element(By.ID,"q")
print(input_first)
browser.close()當然這種方法和上述的方式是通用的,browser.find_element(By.ID,"q")這里By.ID中的ID可以替換為其他幾個
多個元素find_elements,單個元素是find_element,其他使用上沒什么區別,通過其中的一個例子演示:
browser.get(<a href="http://www.taobao.com/" rel="external nofollow" rel="external nofollow" target="_blank">http://www.taobao.com</a>)
lis = browser.find_elements_by_css_selector('.service-bd li')
print(lis)
browser.close()這樣獲得就是一個列表
當然上面的方式也是可以通過導入from selenium.webdriver.common.by import By 這種方式實現
lis = browser.find_elements(By.CSS_SELECTOR,'.service-bd li')
同樣的在單個元素中查找的方法在多個元素查找中同樣存在:
find_elements_by_name
find_elements_by_id
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
一般來說,webdriver 中比較常用的操作對象的方法有下面幾個:
click——點擊對象
send_keys——在對象上模擬按鍵輸入
clear——清除對象的內容,如果可以的話
submit——提交對象的內容,如果可以的話
text——用于獲取元素的文本信息
要想調用鍵盤按鍵操作需要引入 keys 包:
from selenium.webdriver.common.keys import Keys
通過 send_keys()調用按鍵:
send_keys(Keys.TAB) # TAB
send_keys(Keys.ENTER) # 回車
send_keys(Keys.CONTROL,'a') # ctrl+a 全選輸入框內容
send_keys(Keys.CONTROL,'x') # ctrl+x 剪切輸入框內容
import time
browser.get(http://www.taobao.com)
input_str = browser.find_element_by_id('q')
input_str.send_keys("ipad")
time.sleep(1)
input_str.clear()
input_str.send_keys("MakBook pro")
button = browser.find_element_by_class_name('btn-search')
button.click()運行的結果可以看出程序會自動打開Chrome瀏覽器并打開淘寶輸入ipad,然后刪除,重新輸入MakBook pro,并點擊搜索。
鼠標事件一般包括鼠標右鍵、雙擊、拖動、移動鼠標到某個元素上等等。需要引入ActionChains類。引入方法:
from selenium.webdriver.common.action_chains import ActionChains
ActionChains 常用方法:
context_click() :右擊;
double_click() :雙擊;
drag_and_drop(): 拖動;
move_to_element() :鼠標懸停。
perform(): 執行所有ActionChains 中存儲的行為;
鼠標雙擊示例:
qqq =driver.find_element_by_xpath("xxx") #定位到要雙擊的元素
ActionChains(driver).double_click(qqq).perform() #對定位到的元素執行鼠標雙擊操作鼠標拖放示例:
from selenium.webdriver import ActionChains
url = "http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable"
browser.get(url)
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_css_selector('#draggable')
target = browser.find_element_by_css_selector('#droppable')
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()更多操作參考:
http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.common.action_chains
這是一個非常有用的方法,這里就可以直接調用js方法來實現一些操作,下面的例子是通過登錄知乎然后通過js翻到頁面底部,并彈框提示
browser.get(<a href="http://www.zhihu.com/explore" rel="external nofollow" target="_blank">http://www.zhihu.com/explore</a>)
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')url = 'https://www.zhihu.com/explore'
browser.get(url)
logo = browser.find_element_by_id('zh-top-link-logo')
print(logo)
print(logo.get_attribute('class'))url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input.text)id
location
tag_name
size
url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input.id)
print(input.location)
print(input.tag_name)
print(input.size)在很多網頁中都是有Frame標簽,所以我們爬取數據的時候就涉及到切入到frame中以及切出來的問題,通過下面的例子演示
這里常用的是switch_to.from()和switch_to.parent_frame()
import time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_css_selector('#draggable')
print(source)
try:
logo = browser.find_element_by_class_name('logo')
except NoSuchElementException:
print('NO LOGO')
browser.switch_to.parent_frame()
logo = browser.find_element_by_class_name('logo')
print(logo)
print(logo.text)當使用了隱式等待執行測試的時候,如果 WebDriver沒有在 DOM中找到元素,將繼續等待,超出設定時間后則拋出找不到元素的異常。
換句話說,當查找元素或元素并沒有立即出現的時候,隱式等待將等待一段時間再查找 DOM,默認的時間是0
到了一定的時間發現元素還沒有加載,則繼續等待我們指定的時間,如果超過了我們指定的時間還沒有加載就會拋出異常,如果沒有需要等待的時候就已經加載完畢就會立即執行
browser.implicitly_wait(10)
browser.get('https://www.zhihu.com/explore')
input = browser.find_element_by_class_name('zu-top-add-question')
print(input)指定一個等待條件,并且指定一個最長等待時間,會在這個時間內進行判斷是否滿足等待條件。
如果成立就會立即返回,如果不成立,就會一直等待,直到等待你指定的最長等待時間,如果還是不滿足,就會拋出異常,如果滿足了就會正常返回。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.get('https://www.taobao.com/')
wait = WebDriverWait(browser, 10)
input = wait.until(EC.presence_of_element_located((By.ID, 'q')))
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.btn-search')))
print(input, button)上述的例子中的條件:EC.presence_of_element_located()是確認元素是否已經出現了。EC.element_to_be_clickable()是確認元素是否是可點擊的
title_is :標題是某內容
title_contains :標題包含某內容
presence_of_element_located :元素加載出,傳入定位元組,如(By.ID, 'p')
visibility_of_element_located :元素可見,傳入定位元組
visibility_of :可見,傳入元素對象
presence_of_all_elements_located :所有元素加載出
text_to_be_present_in_element :某個元素文本包含某文字
text_to_be_present_in_element_value :某個元素值包含某文字
frame_to_be_available_and_switch_to_it :frame加載并切換
invisibility_of_element_located :元素不可見
element_to_be_clickable :元素可點擊
staleness_of :判斷一個元素是否仍在DOM,可判斷頁面是否已經刷新
element_to_be_selected :元素可選擇,傳元素對象
element_located_to_be_selected :元素可選擇,傳入定位元組
element_selection_state_to_be :傳入元素對象以及狀態,相等返回True,否則返回False
element_located_selection_state_to_be :傳入定位元組以及狀態,相等返回True,否則返回False
alert_is_present :是否出現Alert
實例:博客園標題判斷
# coding: utf-8
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://www.cnblogs.com/101718qiong/")
title = EC.title_is(u"Silence&QH - 博客園") # 判斷title完全等于
print title(driver)
title1 = EC.title_contains("Silence&QH") # 判斷title包含
print title1(driver)
r1 = EC.title_is(u"Silence&QH - 博客園")(driver) # 另外寫法
r2 = EC.title_contains("Silence&QH")(driver)
print r1
print r2更多操作參考:
http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.support.expected_conditions
瀏覽器最大化、最小化
browser.maximize_window() # 將瀏覽器最大化顯示 browser.minimize_window() # 將瀏覽器最小化顯示
瀏覽器設置窗口大小
browser.set_window_size(480, 800) # 設置瀏覽器寬480、高800顯示
瀏覽器前進后退
back() :后退
forward():前進
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com/')
browser.get('https://www.taobao.com/')
browser.get('https://www.python.org/')
browser.back()
time.sleep(1)
browser.forward()
browser.close()get_cookies()
delete_all_cookes()
add_cookie()
browser.get('https://www.zhihu.com/explore')
print(browser.get_cookies())
browser.add_cookie({'name': 'name', 'domain': 'www.zhihu.com', 'value': 'zhaofan'})
print(browser.get_cookies())
browser.delete_all_cookies()
print(browser.get_cookies())通過執行js命令實現新開選項卡window.open(),不同的選項卡是存在列表里browser.window_handles。
通過browser.window_handles[0]就可以操作第一個選項卡,current_window_handle:獲得當前窗口句柄
import time
browser.get('https://www.baidu.com')
browser.execute_script('window.open()')
print(browser.window_handles)
browser.switch_to.window(browser.window_handles[1])
browser.get('https://www.taobao.com')
time.sleep(1)
browser.switch_to.window(browser.window_handles[0])
browser.get('https://python.org')這里的異常比較復雜,官網的參考地址:
http://selenium-python.readthedocs.io/api.html#module-selenium.common.exceptions
這里只進行簡單的演示,查找一個不存在的元素
from selenium import webdriver
from selenium.common.exceptions import TimeoutException, NoSuchElementException
browser = webdriver.Chrome()
try:
browser.get('https://www.baidu.com')
except TimeoutException:
print('Time Out')
try:
browser.find_element_by_id('hello')
except NoSuchElementException:
print('No Element')
finally:
browser.close()在WebDriver中處理JavaScript所生成的alert、confirm以及prompt十分簡單,具體做法是使用 switch_to.alert 方法定位到 alert/confirm/prompt,然后使用text/accept/dismiss/ send_keys等方法進行操作。
方法
text : 返回 alert/confirm/prompt 中的文字信息
accept() : 接受現有警告框
dismiss() : 解散現有警告框
send_keys(keysToSend) : 發送文本至警告框。keysToSend:將文本發送至警告框。
實例演示
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import time
driver = webdriver.Chrome("F:\Chrome\ChromeDriver\chromedriver")
driver.implicitly_wait(10)
driver.get('http://www.baidu.com')
# 鼠標懸停至“設置”鏈接
link = driver.find_element_by_link_text('設置')
ActionChains(driver).move_to_element(link).perform()
# 打開搜索設置
driver.find_element_by_link_text("搜索設置").click()
#在此處設置等待2s否則可能報錯
time.sleep(2)
# 保存設置
driver.find_element_by_class_name("prefpanelgo").click()
time.sleep(2)
# 接受警告框
driver.switch_to.alert.accept()
driver.quit()導入選擇下拉框Select類,使用該類處理下拉框操作。
from selenium.webdriver.support.select import Select
Select類的方法:
select_by_value(“選擇值”) select標簽的value屬性的值
select_by_index(“索引值”) 下拉框的索引
select_by_visible_testx(“文本值”) 下拉框的文本值
有時我們會碰到下拉框,WebDriver提供了Select類來處理下拉框。 如百度搜索設置的下拉框。
from selenium import webdriver
from selenium.webdriver.support.select import Select
from time import sleep
driver = webdriver.Chrome("F:\Chrome\ChromeDriver\chromedriver")
driver.implicitly_wait(10)
driver.get('http://www.baidu.com')
#1.鼠標懸停至“設置”鏈接
driver.find_element_by_link_text('設置').click()
sleep(1)
#2.打開搜索設置
driver.find_element_by_link_text("搜索設置").click()
sleep(2)
#3.搜索結果顯示條數
sel = driver.find_element_by_xpath("//select[@id='nr']")
Select(sel).select_by_value('50') # 顯示50條
sleep(3)
driver.quit()對于通過input標簽實現的上傳功能,可以將其看作是一個輸入框,即通過send_keys()指定本地文件路徑的方式實現文件上傳。
通過send_keys()方法來實現文件上傳:
from selenium import webdriver
import os
driver = webdriver.Firefox()
file_path = 'file:///' + os.path.abspath('upfile.html')
driver.get(file_path)
# 定位上傳按鈕,添加本地文件
driver.find_element_by_name("file").send_keys('D:\\upload_file.txt')
driver.quit()自動化用例是由程序去執行的,因此有時候打印的錯誤信息并不十分明確。如果在腳本執行出錯的時候能對當前窗口截圖保存,那么通過圖片就可以非常直觀地看出出錯的原因。WebDriver提供了截圖函數get_screenshot_as_file()來截取當前窗口。
截屏方法:
get_screenshot_as_file(self, filename) 用于截取當前窗口,并把圖片保存到本地
from selenium import webdriver
from time import sleep
driver =webdriver.Firefox(executable_path ="F:\GeckoDriver\geckodriver")
driver.get('http://www.baidu.com')
driver.find_element_by_id('kw').send_keys('selenium')
driver.find_element_by_id('su').click()
sleep(2)
#1.截取當前窗口,并指定截圖圖片的保存位置
driver.get_screenshot_as_file("D:\\baidu_img.jpg")
driver.quit()在前面的例子中我們一直使用quit()方法,其含義為退出相關的驅動程序和關閉所有窗口。除此之外,WebDriver還提供了close()方法,用來關閉當前窗口。例多窗口的處理,在用例執行的過程中打開了多個窗口,我們想要關閉其中的某個窗口,這時就要用到close()方法進行關閉了。
close() 關閉單個窗口
quit() 關閉所有窗口
現在不少大網站有對selenium采取了監測機制。比如正常情況下我們用瀏覽器訪問淘寶等網站的 window.navigator.webdriver的值為
undefined。而使用selenium訪問則該值為true。那么如何解決這個問題呢?
只需要設置Chromedriver的啟動參數即可解決問題。在啟動Chromedriver之前,為Chrome開啟實驗性功能參數excludeSwitches,它的值為['enable-automation'],完整代碼如下:
from selenium.webdriver import Chrome
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = Chrome(options=option)自動登陸CSDN
import time
import numpy as np
from numpy import random
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
def ease_out_expo(x):
if x == 1:
return 1
else:
return 1 - pow(2, -10 * x)
def get_tracks(distance, seconds, ease_func):
tracks = [0]
offsets = [0]
for t in np.arange(0.0, seconds+0.1, 0.1):
ease = globals()[ease_func]
offset = round(ease(t / seconds) * distance)
tracks.append(offset - offsets[-1])
offsets.append(offset)
return offsets, tracks
def drag_and_drop(browser, offset):
# 定位滑塊元素
WebDriverWait(browser, 20).until(
EC.visibility_of_element_located((By.XPATH, "//*[@class='nc_iconfont btn_slide']"))
)
knob = browser.find_element_by_xpath("//*[@class='nc_iconfont btn_slide']")
offsets, tracks = get_tracks(offset, 0.2, 'ease_out_expo')
ActionChains(browser).click_and_hold(knob).perform()
for x in tracks:
ActionChains(browser).move_by_offset(x, 0).perform()
# 放開
ActionChains(browser).pause(random.randint(6, 14) / 10).release().perform()
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("--start-maximized")
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.get('http://www.baidu.com')
browser.find_element_by_id('kw').send_keys('CSDN')
browser.find_element_by_id('su').click()
WebDriverWait(browser, 20).until(
EC.visibility_of_element_located((By.PARTIAL_LINK_TEXT, "-專業IT技術社區"))
)
browser.find_element_by_partial_link_text('-專業IT技術社區').click()
browser.switch_to.window(browser.window_handles[1]) # 移動句柄
time.sleep(1)
browser.find_element_by_partial_link_text('登錄').click()
browser.find_element_by_link_text('賬號密碼登錄').click()
browser.find_element_by_id('all').send_keys('yangbobin')
browser.find_element_by_name('pwd').send_keys('pass-word')
browser.find_element_by_css_selector("button[data-type='account']").click()
time.sleep(5) # 等待滑動模塊和其他JS文件加載完畢!
while True:
# 定義鼠標拖放動作
drag_and_drop(browser, 261)
# 等待JS認證運行,如果不等待容易報錯
time.sleep(2)
# 查看是否認證成功,獲取text值
WebDriverWait(browser, 20).until(
EC.visibility_of_element_located((By.LINK_TEXT, "刷新"))
)
browser.find_element_by_link_text('刷新').click()自動登陸163郵箱
首先,是163.的登陸為iframe
browser.switch_to_frame('x-URS-iframe')關于“python爬蟲之selenium模塊怎么使用”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“python爬蟲之selenium模塊怎么使用”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





