溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Redis中命令的原子性是什么”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Redis中命令的原子性是什么”吧!

業務中有時候我們會用 Redis 處理一些高并發的業務場景,例如,秒殺業務,對于庫存的操作。。。
先來分析下,并發場景下會發生什么問題
并發問題主要發生在數據的修改上,對于客戶端修改數據,一般分成下面兩個步驟:
1、客戶端先把數據讀取到本地,在本地進行修改;
2、客戶端修改完數據后,再寫回Redis。
我們把這個流程叫做讀取-修改-寫回操作(Read-Modify-Write,簡稱為 RMW 操作)。如果客戶端并發進行 RMW 操作的時候,就需要保證 讀取-修改-寫回是一個原子操作,進行命令操作的時候,其他客戶端不能對當前的數據進行操作。
錯誤的栗子:
統計一個頁面的訪問次數,每次刷新頁面訪問次數+1,這里使用 Redis 來記錄訪問次數。
如果每次的讀取-修改-寫回操作不是一個原子操作,那么就可能存在下圖的問題,客戶端2在客戶端1操作的中途,也獲取 Redis 的值,也對值進行+1,操作,這樣就導致最終數據的錯誤。

對于上面的這種情況,一般會有兩種方式解決:
1、使用 Redis 實現一把分布式鎖,通過鎖來保護每次只有一個線程來操作臨界資源;
2、實現操作命令的原子性。
栗如,對于上面的錯誤栗子,如果讀取-修改-寫回是一個原子性的命令,那么這個命令在操作過程中就不有別的線程同時讀取操作數據,這樣就能避免上面栗子出現的問題。
下面從原子性和鎖兩個方面,具體分析下,對并發訪問問題的處理
為了實現并發控制要求的臨界區代碼互斥執行,如果使用 Redis 中命令的原子性,可以有下面兩種處理方式:
1、借助于 Redis 中的原子性的單命令;
2、把多個操作寫到一個Lua腳本中,以原子性方式執行單個Lua腳本。
在探討 Redis 原子性的時候,先來探討下 Redis 中使用到的編程模型
Redis 中使用到了 Reactor 模型,Reactor 是非阻塞 I/O 模型,這里來看下 Unix 中的 I/O 模型。
操作系統上的 I/O 是用戶空間和內核空間的數據交互,因此 I/O 操作通常包含以下兩個步驟:
1、等待網絡數據到達網卡(讀就緒)/等待網卡可寫(寫就緒) –> 讀取/寫入到內核緩沖區;
2、從內核緩沖區復制數據 –> 用戶空間(讀)/從用戶空間復制數據 -> 內核緩沖區(寫);
Unix 中有五種基本的 I/O 模型
阻塞式 I/O;
非阻塞式 I/O;
I/O 多路復用;
信號驅動 I/O;
異步 I/O;
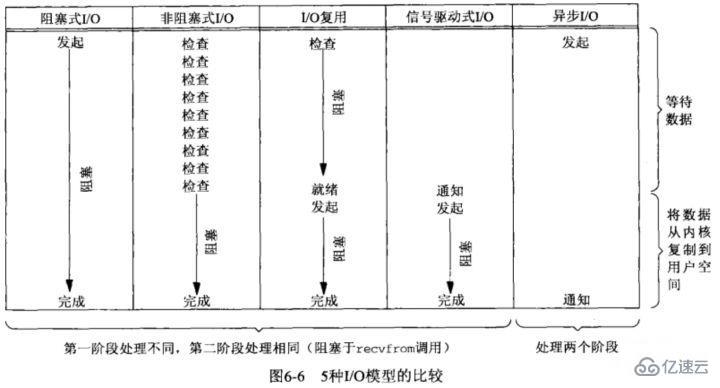
而判定一個 I/O 模型是同步還是異步,主要看第二步:數據在用戶和內核空間之間復制的時候是不是會阻塞當前進程,如果會,則是同步 I/O,否則,就是異步 I/O。
這里主要分下下面三種 I/O 模型
阻塞型 I/O;
當用戶程序執行 read ,線程會被阻塞,一直等到內核數據準備好,并把數據從內核緩沖區拷貝到應用程序的緩沖區中,當拷貝過程完成,read 才會返回。
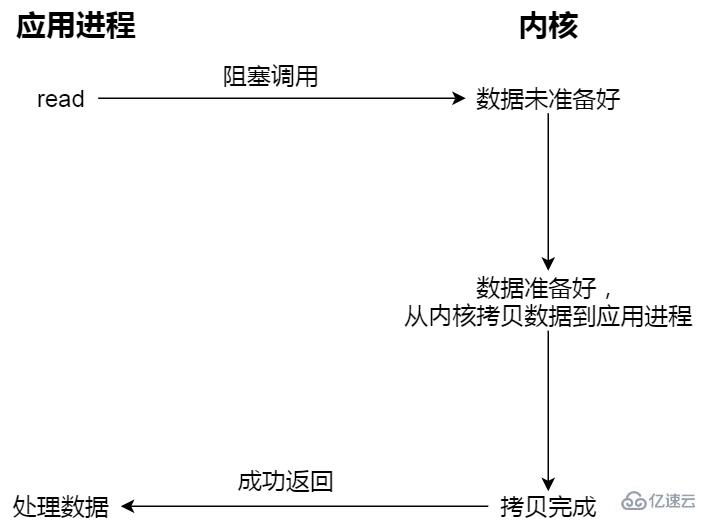
阻塞等待的是「內核數據準備好」和「數據從內核態拷貝到用戶態」這兩個過程。
非阻塞同步 I/O;
非阻塞的 read 請求在數據未準備好的情況下立即返回,可以繼續往下執行,此時應用程序不斷輪詢內核,直到數據準備好,內核將數據拷貝到應用程序緩沖區,read 調用才可以獲取到結果。
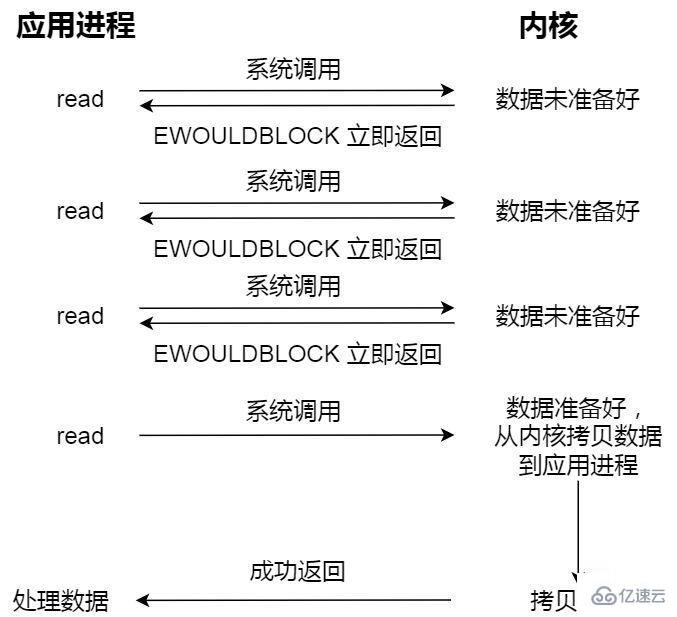
這里最后一次 read 調用,獲取數據的過程,是一個同步的過程,是需要等待的過程。這里的同步指的是內核態的數據拷貝到用戶程序的緩存區這個過程。
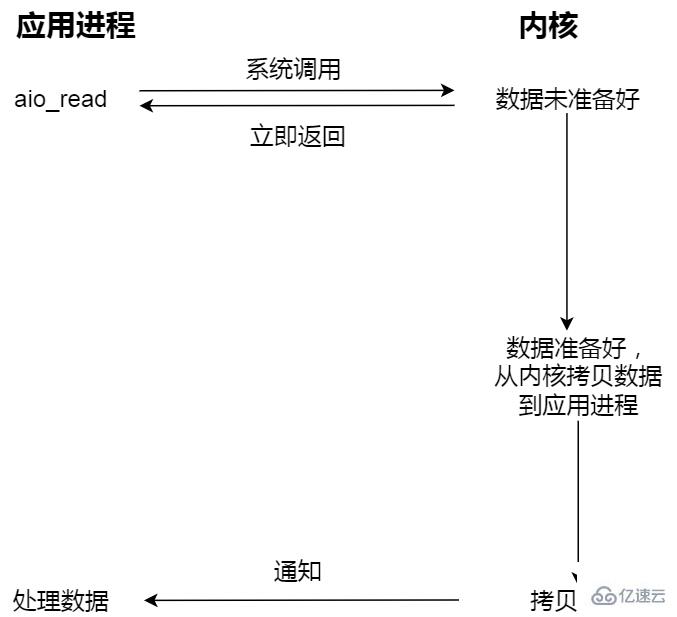
非阻塞異步 I/O;
發起異步 I/O,就立即返回,內核自動將數據從內核空間拷貝到用戶空間,這個拷貝過程同樣是異步的,內核自動完成的,和前面的同步操作不一樣,應用程序并不需要主動發起拷貝動作。
舉個你去飯堂吃飯的例子,你好比應用程序,飯堂好比操作系統。
阻塞 I/O 好比,你去飯堂吃飯,但是飯堂的菜還沒做好,然后你就一直在那里等啊等,等了好長一段時間終于等到飯堂阿姨把菜端了出來(數據準備的過程),但是你還得繼續等阿姨把菜(內核空間)打到你的飯盒里(用戶空間),經歷完這兩個過程,你才可以離開。
非阻塞 I/O 好比,你去了飯堂,問阿姨菜做好了沒有,阿姨告訴你沒,你就離開了,過幾十分鐘,你又來飯堂問阿姨,阿姨說做好了,于是阿姨幫你把菜打到你的飯盒里,這個過程你是得等待的。
異步 I/O 好比,你讓飯堂阿姨將菜做好并把菜打到飯盒里后,把飯盒送到你面前,整個過程你都不需要任何等待。
在 web 服務中,處理 web 請求通常有兩種體系結構,分別為:thread-based architecture(基于線程的架構)、event-driven architecture(事件驅動模型)
thread-based architecture(基于線程的架構):這種比較容易理解,就是多線程并發模式,服務端在處理請求的時候,一個請求分配一個獨立的線程來處理。
因為每個請求分配一個獨立的線程,所以單個線程的阻塞不會影響到其他的線程,能夠提高程序的響應速度。
不足的是,連接和線程之間始終保持一對一的關系,如果是一直處于 Keep-Alive 狀態的長連接將會導致大量工作線程在空閑狀態下等待,例如,文件系統訪問,網絡等。此外,成百上千的連接還可能會導致并發線程浪費大量內存的堆棧空間。
事件驅動的體系結構由事件生產者和事件消費者組,是一種松耦合、分布式的驅動架構,生產者收集到某應用產生的事件后實時對事件采取必要的處理后路由至下游系統,無需等待系統響應,下游的事件消費者組收到是事件消息,異步的處理。
事件驅動架構具有以下優勢:
降低耦合;
降低事件生產者和訂閱者的耦合性。事件生產者只需關注事件的發生,無需關注事件如何處理以及被分發給哪些訂閱者。任何一個環節出現故障,不會影響其他業務正常運行。
異步執行;
事件驅動架構適用于異步場景,即便是需求高峰期,收集各種來源的事件后保留在事件總線中,然后逐步分發傳遞事件,不會造成系統擁塞或資源過剩的情況。
可擴展性;
事件驅動架構中路由和過濾能力支持劃分服務,便于擴展和路由分發。
Reactor 模式和 Proactor 模式都是 event-driven architecture(事件驅動模型)的實現方式,這里具體分析下
Reactor 模式,是指通過一個或多個輸入同時傳遞給服務處理器的服務請求的事件驅動處理模式。
在處理?絡 IO 的連接事件、讀事件、寫事件。Reactor 中引入了三類角色
reactor:監聽和分配事件,連接事件交給 acceptor 處理,讀寫事件交給 handler 處理;
acceptor:接收連接請求,接收連接后,會創建 handler ,處理網絡連接上對后續讀寫事件的處理;
handler:處理讀寫事件。
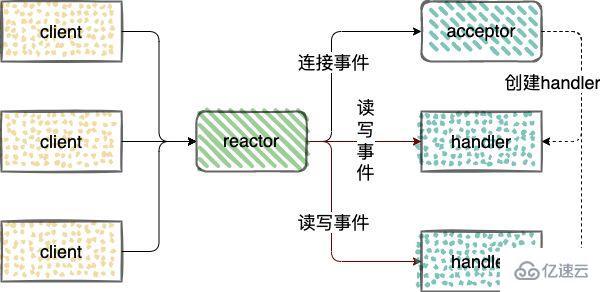
Reactor 模型又分為 3 類:
單線程 Reactor 模式;
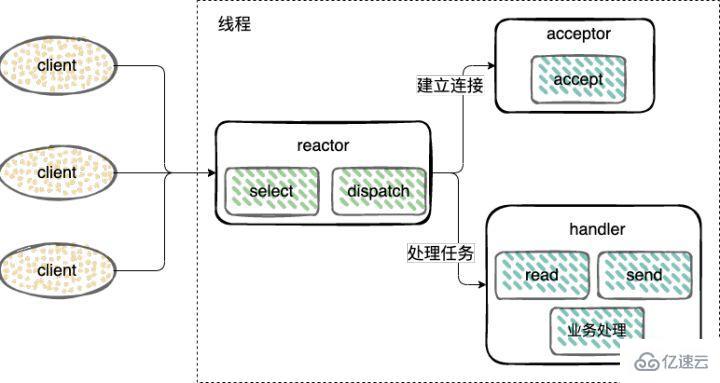
建立連接(Acceptor)、監聽accept、read、write事件(Reactor)、處理事件(Handler)都只用一個單線程;
多線程 Reactor 模式;
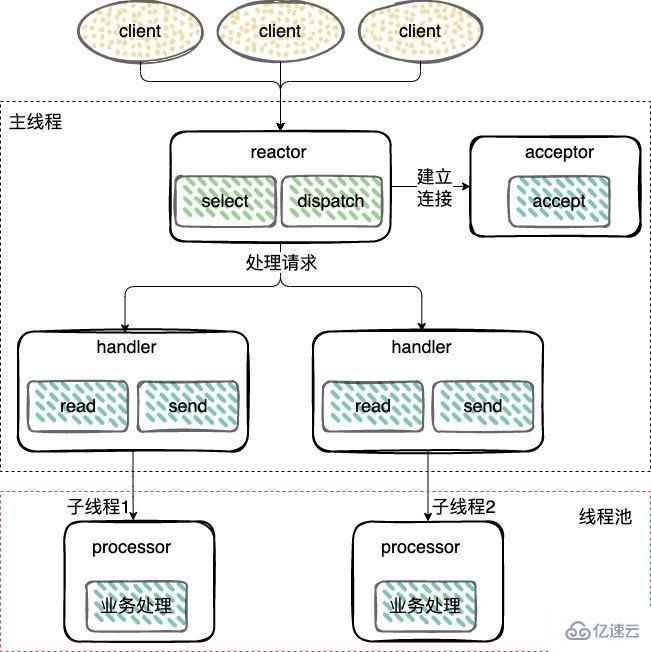
與單線程模式不同的是,添加了一個工作者線程池,并將非 I/O 操作從 Reactor 線程中移出轉交給工作者線程池(Thread Pool)來執行。
建立連接(Acceptor)和 監聽accept、read、write事件(Reactor),復用一個線程。
工作線程池:處理事件(Handler),由一個工作線程池來執行業務邏輯,包括數據就緒后,用戶態的數據讀寫。
主從 Reactor 模式;
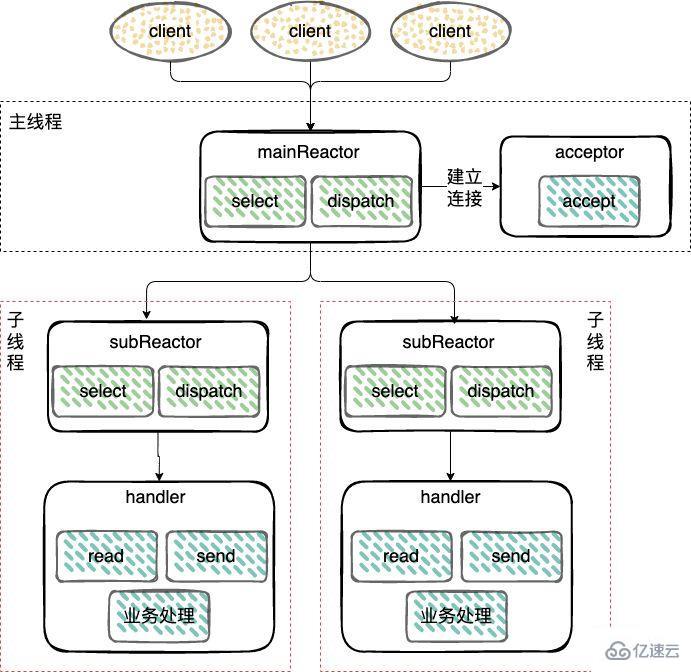
對于多個CPU的機器,為充分利用系統資源,將 Reactor 拆分為兩部分:mainReactor 和 subReactor。
mainReactor:負責監聽server socket,用來處理網絡新連接的建立,將建立的socketChannel指定注冊給subReactor,通常一個線程就可以處理;
subReactor:監聽accept、read、write事件(Reactor),包括等待數據就緒時,內核態的數據讀寫,通常使用多線程。
工作線程:處理事件(Handler)可以和 subReactor 共同使用同一個線程,也可以做成線程池,類似上面多線程 Reactor 模式下的工作線程池的處理方式。
reactor 流程與 Reactor 模式類似
不同點就是
Reactor 是非阻塞同步網絡模式,感知的是就緒可讀寫事件。
在每次感知到有事件發生(比如可讀就緒事件)后,就需要應用進程主動調用 read 方法來完成數據的讀取,也就是要應用進程主動將 socket 接收緩存中的數據讀到應用進程內存中,這個過程是同步的,讀取完數據后應用進程才能處理數據。
Proactor 是異步網絡模式,感知的是已完成的讀寫事件。
在發起異步讀寫請求時,需要傳入數據緩沖區的地址(用來存放結果數據)等信息,這樣系統內核才可以自動幫我們把數據的讀寫工作完成,這里的讀寫工作全程由操作系統來做,并不需要像 Reactor 那樣還需要應用進程主動發起 read/write 來讀寫數據,操作系統完成讀寫工作后,就會通知應用進程直接處理數據。
因此,Reactor 可以理解為「來了事件操作系統通知應用進程,讓應用進程來處理」,而 Proactor 可以理解為「來了事件操作系統來處理,處理完再通知應用進程」。
舉個實際生活中的例子,Reactor 模式就是快遞員在樓下,給你打電話告訴你快遞到你家小區了,你需要自己下樓來拿快遞。而在 Proactor 模式下,快遞員直接將快遞送到你家門口,然后通知你。
Redis 中使用是單線程,可能處于以下幾方面的考慮
1、Redis 是純內存的操作,執行速度是非常快的,因此這部分操作通常不會是性能瓶頸,性能瓶頸在于網絡 I/O;
2、避免過多的上下文切換開銷,單線程則可以規避進程內頻繁的線程切換開銷;
3、避免同步機制的開銷,多線程必然會面臨對于共享資源的訪問,這時候通常的做法就是加鎖,雖然是多線程,這時候就會變成串行的訪問。也就是多線程編程模式會面臨的共享資源的并發訪問控制問題;
4、簡單可維護,多線程也會引入同步原語來保護共享資源的并發訪問,代碼的可維護性和易讀性將會下降。
Redis 在 v6.0 版本之前,Redis 的核心網絡模型一直是一個典型的單 Reactor 模型:利用 epoll/select/kqueue 等多路復用技術,在單線程的事件循環中不斷去處理事件(客戶端請求),最后回寫響應數據到客戶端:
這里來看下 Redis 如何使用單線程處理任務

Redis 的網絡框架實現了 Reactor 模型,并且自行開發實現了一個事件驅動框架。
事件驅動框架的邏輯簡單點講就是
事件初始化;
事件捕獲;
分發和處理主循環。

來看下 Redis 中事件驅動框架實現的幾個主要函數
// 執行事件捕獲,分發和處理循環 void aeMain(aeEventLoop *eventLoop); // 用來注冊監聽的事件和事件對應的處理函數。只有對事件和處理函數進行了注冊,才能在事件發生時調用相應的函數進行處理。 int aeCreateFileEvent(aeEventLoop *eventLoop, int fd, int mask, aeFileProc *proc, void *clientData); // aeProcessEvents 函數實現的主要功能,包括捕獲事件、判斷事件類型和調用具體的事件處理函數,從而實現事件的處理 int aeProcessEvents(aeEventLoop *eventLoop, int flags);
使用 aeMain 作為主循環來對事件進行持續監聽和捕獲,其中會調用 aeProcessEvents 函數,實現事件捕獲、判斷事件類型和調用具體的事件處理函數,從而實現事件的處理。
// https://github.com/redis/redis/blob/5.0/src/ae.c#L496
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
aeProcessEvents(eventLoop, AE_ALL_EVENTS|AE_CALL_AFTER_SLEEP);
}
}
// https://github.com/redis/redis/blob/5.0/src/ae.c#L358
int aeProcessEvents(aeEventLoop *eventLoop, int flags)
{
...
if (eventLoop->maxfd != -1 || ((flags & AE_TIME_EVENTS) && !(flags & AE_DONT_WAIT))) {
...
//調用aeApiPoll函數捕獲事件
numevents = aeApiPoll(eventLoop, tvp);
...
}
...
}可以看到 aeProcessEvents 中對于 IO 事件的捕獲是通過調用 aeApiPoll 來完成的。
aeApiPoll 是 I/O 多路復用 API,是基于 epoll_wait/select/kevent 等系統調用的封裝,監聽等待讀寫事件觸發,然后處理,它是事件循環(Event Loop)中的核心函數,是事件驅動得以運行的基礎。
Redis 是依賴于操作系統底層提供的 IO 多路復用機制,來實現事件捕獲,檢查是否有新的連接、讀寫事件發生。為了適配不同的操作系統,Redis 對不同操作系統實現的網絡 IO 多路復用函數,都進行了統一的封裝。
// https://github.com/redis/redis/blob/5.0/src/ae.c#L49 #ifdef HAVE_EVPORT #include "ae_evport.c" // Solaris #else #ifdef HAVE_EPOLL #include "ae_epoll.c" // Linux #else #ifdef HAVE_KQUEUE #include "ae_kqueue.c" // MacOS #else #include "ae_select.c" // Windows #endif #endif #endif
ae_epoll.c:對應 Linux 上的 IO 復用函數 epoll;
ae_evport.c:對應 Solaris 上的 IO 復用函數 evport;
ae_kqueue.c:對應 macOS 或 FreeBSD 上的 IO 復用函數 kqueue;
ae_select.c:對應 Linux(或 Windows)的 IO 復用函數 select。
監聽 socket 的讀事件,當有客戶端連接請求過來,使用函數 acceptTcpHandler 和客戶端建立連接
當 Redis 啟動后,服務器程序的 main 函數會調用 initSever 函數來進行初始化,而在初始化的過程中,aeCreateFileEvent 就會被 initServer 函數調用,用于注冊要監聽的事件,以及相應的事件處理函數。
// https://github.com/redis/redis/blob/5.0/src/server.c#L2036
void initServer(void) {
...
// 創建一個事件處理程序以接受 TCP 和 Unix 中的新連接
for (j = 0; j < server.ipfd_count; j++) {
if (aeCreateFileEvent(server.el, server.ipfd[j], AE_READABLE,
acceptTcpHandler,NULL) == AE_ERR)
{
serverPanic(
"Unrecoverable error creating server.ipfd file event.");
}
}
...
}可以看到 initServer 中會根據啟用的 IP 端口個數,為每個 IP 端口上的網絡事件,調用 aeCreateFileEvent,創建對 AE_READABLE 事件的監聽,并且注冊 AE_READABLE 事件的處理 handler,也就是 acceptTcpHandler 函數。
然后看下 acceptTcpHandler 的實現
// https://github.com/redis/redis/blob/5.0/src/networking.c#L734
void acceptTcpHandler(aeEventLoop *el, int fd, void *privdata, int mask) {
int cport, cfd, max = MAX_ACCEPTS_PER_CALL;
char cip[NET_IP_STR_LEN];
UNUSED(el);
UNUSED(mask);
UNUSED(privdata);
while(max--) {
// 用于accept客戶端的連接,其返回值是客戶端對應的socket
cfd = anetTcpAccept(server.neterr, fd, cip, sizeof(cip), &cport);
if (cfd == ANET_ERR) {
if (errno != EWOULDBLOCK)
serverLog(LL_WARNING,
"Accepting client connection: %s", server.neterr);
return;
}
serverLog(LL_VERBOSE,"Accepted %s:%d", cip, cport);
// 會調用acceptCommonHandler對連接以及客戶端進行初始化
acceptCommonHandler(cfd,0,cip);
}
}
// https://github.com/redis/redis/blob/5.0/src/networking.c#L664
static void acceptCommonHandler(int fd, int flags, char *ip) {
client *c;
// 分配并初始化新客戶端
if ((c = createClient(fd)) == NULL) {
serverLog(LL_WARNING,
"Error registering fd event for the new client: %s (fd=%d)",
strerror(errno),fd);
close(fd); /* May be already closed, just ignore errors */
return;
}
// 判斷當前連接的客戶端是否超過最大值,如果超過的話,會拒絕這次連接。否則,更新客戶端連接數的計數
if (listLength(server.clients) > server.maxclients) {
char *err = "-ERR max number of clients reached\r\n";
/* That's a best effort error message, don't check write errors */
if (write(c->fd,err,strlen(err)) == -1) {
/* Nothing to do, Just to avoid the warning... */
}
server.stat_rejected_conn++;
freeClient(c);
return;
}
...
}
// 使用多路復用,需要記錄每個客戶端的狀態,client 之前通過鏈表保存
typedef struct client {
int fd; // 字段是客戶端套接字文件描述符
sds querybuf; // 保存客戶端發來命令請求的輸入緩沖區。以Redis通信協議的方式保存
int argc; // 當前命令的參數數量
robj **argv; // 當前命令的參數
redisDb *db; // 當前選擇的數據庫指針
int flags;
list *reply; // 保存命令回復的鏈表。因為靜態緩沖區大小固定,主要保存固定長度的命令回復,當處理一些返回大量回復的命令,則會將命令回復以鏈表的形式連接起來。
// ... many other fields ...
char buf[PROTO_REPLY_CHUNK_BYTES];
} client;
client *createClient(int fd) {
client *c = zmalloc(sizeof(client));
// 如果fd為-1,表示創建的是一個無網絡連接的偽客戶端,用于執行lua腳本的時候。
// 如果fd不等于-1,表示創建一個有網絡連接的客戶端
if (fd != -1) {
// 設置fd為非阻塞模式
anetNonBlock(NULL,fd);
// 禁止使用 Nagle 算法,client向內核遞交的每個數據包都會立即發送給server出去,TCP_NODELAY
anetEnableTcpNoDelay(NULL,fd);
// 如果開啟了tcpkeepalive,則設置 SO_KEEPALIVE
if (server.tcpkeepalive)
anetKeepAlive(NULL,fd,server.tcpkeepalive);
// 創建一個文件事件狀態el,且監聽讀事件,開始接受命令的輸入
if (aeCreateFileEvent(server.el,fd,AE_READABLE,
readQueryFromClient, c) == AE_ERR)
{
close(fd);
zfree(c);
return NULL;
}
}
...
// 初始化client 中的參數
return c;
}1、acceptTcpHandler 主要用于處理和客戶端連接的建立;
2、其中會調用函數 anetTcpAccept 用于 accept 客戶端的連接,其返回值是客戶端對應的 socket;
3、然后調用 acceptCommonHandler 對連接以及客戶端進行初始化;
4、初始化客戶端的時候,同時使用 aeCreateFileEvent 用來注冊監聽的事件和事件對應的處理函數,將 readQueryFromClient 命令讀取處理器綁定到新連接對應的文件描述符上;
5、服務器會監聽該文件描述符的讀事件,當客戶端發送了命令,觸發了 AE_READABLE 事件,那么就會調用回調函數 readQueryFromClient() 來從文件描述符 fd 中讀發來的命令,并保存在輸入緩沖區中 querybuf。
readQueryFromClient 是請求處理的起點,解析并執行客戶端的請求命令。
// https://github.com/redis/redis/blob/5.0/src/networking.c#L1522
// 讀取client的輸入緩沖區的內容
void readQueryFromClient(aeEventLoop *el, int fd, void *privdata, int mask) {
client *c = (client*) privdata;
int nread, readlen;
size_t qblen;
UNUSED(el);
UNUSED(mask);
...
// 輸入緩沖區的長度
qblen = sdslen(c->querybuf);
// 更新緩沖區的峰值
if (c->querybuf_peak < qblen) c->querybuf_peak = qblen;
// 擴展緩沖區的大小
c->querybuf = sdsMakeRoomFor(c->querybuf, readlen);
// 調用read從描述符為fd的客戶端socket中讀取數據
nread = read(fd, c->querybuf+qblen, readlen);
...
// 處理讀取的內容
processInputBufferAndReplicate(c);
}
// https://github.com/redis/redis/blob/5.0/src/networking.c#L1507
void processInputBufferAndReplicate(client *c) {
// 當前客戶端不屬于主從復制中的Master
// 直接調用 processInputBuffer,對客戶端輸入緩沖區中的命令和參數進行解析
if (!(c->flags & CLIENT_MASTER)) {
processInputBuffer(c);
// 客戶端屬于主從復制中的Master
// 調用processInputBuffer函數,解析客戶端命令,
// 調用replicationFeedSlavesFromMasterStream 函數,將主節點接收到的命令同步給從節點
} else {
size_t prev_offset = c->reploff;
processInputBuffer(c);
size_t applied = c->reploff - prev_offset;
if (applied) {
replicationFeedSlavesFromMasterStream(server.slaves,
c->pending_querybuf, applied);
sdsrange(c->pending_querybuf,applied,-1);
}
}
}
// https://github.com/redis/redis/blob/5.0/src/networking.c#L1428
void processInputBuffer(client *c) {
server.current_client = c;
/* Keep processing while there is something in the input buffer */
// 持續讀取緩沖區的內容
while(c->qb_pos < sdslen(c->querybuf)) {
...
/* Multibulk processing could see a <= 0 length. */
// 如果參數為0,則重置client
if (c->argc == 0) {
resetClient(c);
} else {
/* Only reset the client when the command was executed. */
// 執行命令成功后重置client
if (processCommand(c) == C_OK) {
if (c->flags & CLIENT_MASTER && !(c->flags & CLIENT_MULTI)) {
/* Update the applied replication offset of our master. */
c->reploff = c->read_reploff - sdslen(c->querybuf) + c->qb_pos;
}
// 命令處于阻塞狀態中的客戶端,不需要進行重置
if (!(c->flags & CLIENT_BLOCKED) || c->btype != BLOCKED_MODULE)
resetClient(c);
}
/* freeMemoryIfNeeded may flush slave output buffers. This may
* result into a slave, that may be the active client, to be
* freed. */
if (server.current_client == NULL) break;
}
}
/* Trim to pos */
if (server.current_client != NULL && c->qb_pos) {
sdsrange(c->querybuf,c->qb_pos,-1);
c->qb_pos = 0;
}
server.current_client = NULL;
}1、readQueryFromClient(),從文件描述符 fd 中讀出數據到輸入緩沖區 querybuf 中;
2、使用 processInputBuffer 函數完成對命令的解析,在其中使用 processInlineBuffer 或者 processMultibulkBuffer 根據 Redis 協議解析命令;
3、完成對一個命令的解析,就使用 processCommand 對命令就行執行;
4、命令執行完成,最后調用 addReply 函數族的一系列函數將響應數據寫入到對應 client 的寫出緩沖區:client->buf 或者 client->reply ,client->buf 是首選的寫出緩沖區,固定大小 16KB,一般來說可以緩沖足夠多的響應數據,但是如果客戶端在時間窗口內需要響應的數據非常大,那么則會自動切換到 client->reply 鏈表上去,使用鏈表理論上能夠保存無限大的數據(受限于機器的物理內存),最后把 client 添加進一個 LIFO 隊列 clients_pending_write;
在 Redis 事件驅動框架每次循環進入事件處理函數前,來處理監聽到的已觸發事件或是到時的時間事件之前,都會調用 beforeSleep 函數,進行一些任務處理,這其中就包括了調用 handleClientsWithPendingWrites 函數,它會將 Redis sever 客戶端緩沖區中的數據寫回客戶端。
// https://github.com/redis/redis/blob/5.0/src/server.c#L1380
void beforeSleep(struct aeEventLoop *eventLoop) {
UNUSED(eventLoop);
...
// 將 Redis sever 客戶端緩沖區中的數據寫回客戶端
handleClientsWithPendingWrites();
...
}
// https://github.com/redis/redis/blob/5.0/src/networking.c#L1082
int handleClientsWithPendingWrites(void) {
listIter li;
listNode *ln;
// 遍歷 clients_pending_write 隊列,調用 writeToClient 把 client 的寫出緩沖區里的數據回寫到客戶端
int processed = listLength(server.clients_pending_write);
listRewind(server.clients_pending_write,&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_WRITE;
listDelNode(server.clients_pending_write,ln);
...
// 調用 writeToClient 函數,將客戶端輸出緩沖區中的數據寫回
if (writeToClient(c->fd,c,0) == C_ERR) continue;
// 如果輸出緩沖區的數據還沒有寫完,此時,handleClientsWithPendingWrites 函數就
// 會調用 aeCreateFileEvent 函數,創建可寫事件,并設置回調函數 sendReplyToClien
if (clientHasPendingReplies(c)) {
int ae_flags = AE_WRITABLE;
if (server.aof_state == AOF_ON &&
server.aof_fsync == AOF_FSYNC_ALWAYS)
{
ae_flags |= AE_BARRIER;
}
// 將文件描述符fd和AE_WRITABLE事件關聯起來,當客戶端可寫時,就會觸發事件,調用sendReplyToClient()函數,執行寫事件
if (aeCreateFileEvent(server.el, c->fd, ae_flags,
sendReplyToClient, c) == AE_ERR)
{
freeClientAsync(c);
}
}
}
return processed;
}
// https://github.com/redis/redis/blob/5.0/src/networking.c#L1072
// 寫事件處理程序,只是發送回復給client
void sendReplyToClient(aeEventLoop *el, int fd, void *privdata, int mask) {
UNUSED(el);
UNUSED(mask);
writeToClient(fd,privdata,1);
}
// https://github.com/redis/redis/blob/5.0/src/networking.c#L979
// 將輸出緩沖區的數據寫給client,如果client被釋放則返回C_ERR,沒被釋放則返回C_OK
int writeToClient(int fd, client *c, int handler_installed) {
ssize_t nwritten = 0, totwritten = 0;
size_t objlen;
clientReplyBlock *o;
// 如果指定的client的回復緩沖區中還有數據,則返回真,表示可以寫socket
while(clientHasPendingReplies(c)) {
// 固定緩沖區發送未完成
if (c->bufpos > 0) {
// 將緩沖區的數據寫到fd中
nwritten = write(fd,c->buf+c->sentlen,c->bufpos-c->sentlen);
...
// 如果發送的數據等于buf的偏移量,表示發送完成
if ((int)c->sentlen == c->bufpos) {
c->bufpos = 0;
c->sentlen = 0;
}
// 固定緩沖區發送完成,發送回復鏈表的內容
} else {
// 回復鏈表的第一條回復對象,和對象值的長度和所占的內存
o = listNodeValue(listFirst(c->reply));
objlen = o->used;
if (objlen == 0) {
c->reply_bytes -= o->size;
listDelNode(c->reply,listFirst(c->reply));
continue;
}
// 將當前節點的值寫到fd中
nwritten = write(fd, o->buf + c->sentlen, objlen - c->sentlen);
if (nwritten <= 0) break;
c->sentlen += nwritten;
totwritten += nwritten;
...
}
...
}
...
// 如果指定的client的回復緩沖區中已經沒有數據,發送完成
if (!clientHasPendingReplies(c)) {
c->sentlen = 0;
// 刪除當前client的可讀事件的監聽
if (handler_installed) aeDeleteFileEvent(server.el,c->fd,AE_WRITABLE);
/* Close connection after entire reply has been sent. */
// 如果指定了寫入按成之后立即關閉的標志,則釋放client
if (c->flags & CLIENT_CLOSE_AFTER_REPLY) {
freeClient(c);
return C_ERR;
}
}
return C_OK;
}1、beforeSleep 函數調用的 handleClientsWithPendingWrites 函數,會遍歷 clients_pending_write(待寫回數據的客戶端) 隊列,調用 writeToClient 把 client 的寫出緩沖區里的數據回寫到客戶端,然后調用 writeToClient 函數,將客戶端輸出緩沖區中的數據發送給客戶端;
2、如果輸出緩沖區的數據還沒有寫完,此時,handleClientsWithPendingWrites 函數就會調用 aeCreateFileEvent 函數,注冊 sendReplyToClient 到該連接的寫就緒事件,等待將后續將數據寫回給客戶端。
上面的執行流程總結下來就是
1、Redis Server 啟動后,主線程會啟動一個時間循環(Event Loop),持續監聽事件;
2、client 到 server 的新連接,會調用 acceptTcpHandler 函數,之后會注冊讀事件 readQueryFromClient 函數,client 發給 server 的數據,都會在這個函數處理,這個函數會解析 client 的數據,找到對應的 cmd 函數執行;
3、cmd 邏輯執行完成后,server 需要寫回數據給 client,調用 addReply 函數族的一系列函數將響應數據寫入到對應 client 的寫出緩沖區:client->buf 或者 client->reply ,client->buf 是首選的寫出緩沖區,固定大小 16KB,一般來說可以緩沖足夠多的響應數據,但是如果客戶端在時間窗口內需要響應的數據非常大,那么則會自動切換到 client->reply 鏈表上去,使用鏈表理論上能夠保存無限大的數據(受限于機器的物理內存),最后把 client 添加進一個 LIFO 隊列 clients_pending_write;
4、在 Redis 事件驅動框架每次循環進入事件處理函數前,來處理監聽到的已觸發事件或是到時的時間事件之前,都會調用 beforeSleep 函數,進行一些任務處理,這其中就包括了調用 handleClientsWithPendingWrites 函數,它會將 Redis sever 客戶端緩沖區中的數據寫回客戶端;
beforeSleep 函數調用的 handleClientsWithPendingWrites 函數,會遍歷 clients_pending_write(待寫回數據的客戶端) 隊列,調用 writeToClient 把 client 的寫出緩沖區里的數據回寫到客戶端,然后調用 writeToClient 函數,將客戶端輸出緩沖區中的數據發送給客戶端;
如果輸出緩沖區的數據還沒有寫完,此時,handleClientsWithPendingWrites 函數就會調用 aeCreateFileEvent 函數,注冊 sendReplyToClient 到該連接的寫就緒事件,等待將后續將數據寫回給客戶端。
在 Redis6.0 的版本中,引入了多線程來處理 IO 任務,多線程的引入,充分利用了當前服務器多核特性,使用多核運行多線程,讓多線程幫助加速數據讀取、命令解析以及數據寫回的速度,提升 Redis 整體性能。
Redis6.0 之前的版本用的是單線程 Reactor 模式,所有的操作都在一個線程中完成,6.0 之后的版本使用了主從 Reactor 模式。
由一個 mainReactor 線程接收連接,然后發送給多個 subReactor 線程處理,subReactor 負責處理具體的業務。
來看下 Redis 多IO線程的具體實現過程
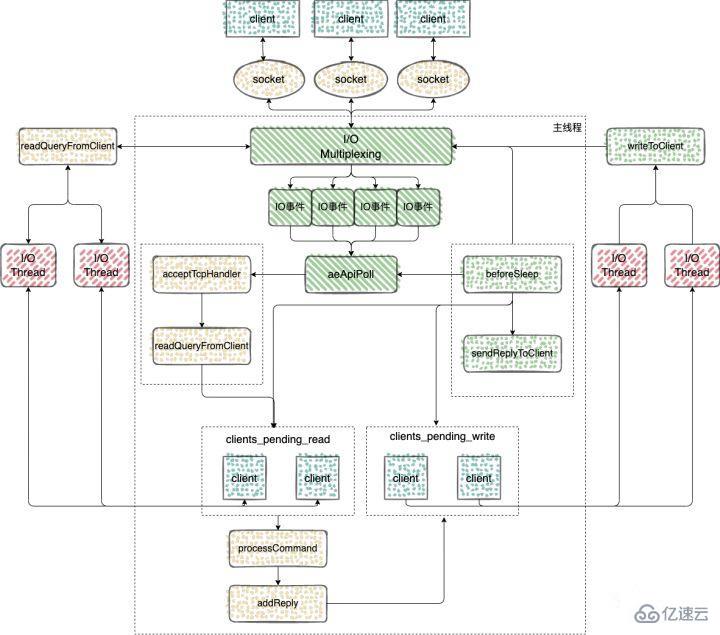
使用 initThreadedIO 函數來初始化多 IO 線程。
// https://github.com/redis/redis/blob/6.2/src/networking.c#L3573
void initThreadedIO(void) {
server.io_threads_active = 0; /* We start with threads not active. */
/* Don't spawn any thread if the user selected a single thread:
* we'll handle I/O directly from the main thread. */
// 如果用戶只配置了一個 I/O 線程,不需要創建新線程了,直接在主線程中處理
if (server.io_threads_num == 1) return;
if (server.io_threads_num > IO_THREADS_MAX_NUM) {
serverLog(LL_WARNING,"Fatal: too many I/O threads configured. "
"The maximum number is %d.", IO_THREADS_MAX_NUM);
exit(1);
}
/* Spawn and initialize the I/O threads. */
// 初始化線程
for (int i = 0; i < server.io_threads_num; i++) {
/* Things we do for all the threads including the main thread. */
io_threads_list[i] = listCreate();
// 編號為0是主線程
if (i == 0) continue; /* Thread 0 is the main thread. */
/* Things we do only for the additional threads. */
pthread_t tid;
// 初始化io_threads_mutex數組
pthread_mutex_init(&io_threads_mutex[i],NULL);
// 初始化io_threads_pending數組
setIOPendingCount(i, 0);
// 主線程在啟動 I/O 線程的時候會默認先鎖住它,直到有 I/O 任務才喚醒它。
pthread_mutex_lock(&io_threads_mutex[i]); /* Thread will be stopped. */
// 調用pthread_create函數創建IO線程,線程運行函數為IOThreadMain
if (pthread_create(&tid,NULL,IOThreadMain,(void*)(long)i) != 0) {
serverLog(LL_WARNING,"Fatal: Can't initialize IO thread.");
exit(1);
}
io_threads[i] = tid;
}
}可以看到在 initThreadedIO 中完成了對下面四個數組的初始化工作
io_threads_list 數組:保存了每個 IO 線程要處理的客戶端,將數組每個元素初始化為一個 List 類型的列表;
io_threads_pending 數組:保存等待每個 IO 線程處理的客戶端個數;
io_threads_mutex 數組:保存線程互斥鎖;
io_threads 數組:保存每個 IO 線程的描述符。
Redis server 在和一個客戶端建立連接后,就開始了監聽客戶端的可讀事件,處理可讀事件的回調函數就是 readQueryFromClient
// https://github.com/redis/redis/blob/6.2/src/networking.c#L2219
void readQueryFromClient(connection *conn) {
client *c = connGetPrivateData(conn);
int nread, readlen;
size_t qblen;
/* Check if we want to read from the client later when exiting from
* the event loop. This is the case if threaded I/O is enabled. */
// 判斷是否從客戶端延遲讀取數據
if (postponeClientRead(c)) return;
...
}
// https://github.com/redis/redis/blob/6.2/src/networking.c#L3746
int postponeClientRead(client *c) {
// 當多線程 I/O 模式開啟、主線程沒有在處理阻塞任務時,將 client 加入異步隊列。
if (server.io_threads_active &&
server.io_threads_do_reads &&
!ProcessingEventsWhileBlocked &&
!(c->flags & (CLIENT_MASTER|CLIENT_SLAVE|CLIENT_PENDING_READ|CLIENT_BLOCKED)))
{
// 給客戶端的flag添加CLIENT_PENDING_READ標記,表示推遲該客戶端的讀操作
c->flags |= CLIENT_PENDING_READ;
// 將可獲得加入clients_pending_write列表
listAddNodeHead(server.clients_pending_read,c);
return 1;
} else {
return 0;
}
}使用 clients_pending_read 保存了需要進行延遲讀操作的客戶端之后,這些客戶端又是如何分配給多 IO 線程執行的呢?
handleClientsWithPendingWritesUsingThreads 函數:該函數主要負責將 clients_pending_write 列表中的客戶端分配給 IO 線程進行處理。
看下如何實現
// https://github.com/redis/redis/blob/6.2/src/networking.c#L3766
int handleClientsWithPendingReadsUsingThreads(void) {
// 當多線程 I/O 模式開啟,才能執行下面的流程
if (!server.io_threads_active || !server.io_threads_do_reads) return 0;
int processed = listLength(server.clients_pending_read);
if (processed == 0) return 0;
// 遍歷待讀取的 client 隊列 clients_pending_read,
// 根據IO線程的數量,讓clients_pending_read中客戶端數量對IO線程進行取模運算
// 取模的結果就是客戶端分配給對應IO線程的編號
listIter li;
listNode *ln;
listRewind(server.clients_pending_read,&li);
int item_id = 0;
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c);
item_id++;
}
// 設置當前 I/O 操作為讀取操作,給每個 I/O 線程的計數器設置分配的任務數量,
// 讓 I/O 線程可以開始工作:只讀取和解析命令,不執行
io_threads_op = IO_THREADS_OP_READ;
for (int j = 1; j < server.io_threads_num; j++) {
int count = listLength(io_threads_list[j]);
setIOPendingCount(j, count);
}
// 主線程自己也會去執行讀取客戶端請求命令的任務,以達到最大限度利用 CPU。
listRewind(io_threads_list[0],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
readQueryFromClient(c->conn);
}
listEmpty(io_threads_list[0]);
// 忙輪詢,等待所有 IO 線程完成待讀客戶端的處理
while(1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++)
pending += getIOPendingCount(j);
if (pending == 0) break;
}
// 遍歷待讀取的 client 隊列,清除 CLIENT_PENDING_READ標記,
// 然后解析并執行所有 client 的命令。
while(listLength(server.clients_pending_read)) {
ln = listFirst(server.clients_pending_read);
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_READ;
listDelNode(server.clients_pending_read,ln);
serverAssert(!(c->flags & CLIENT_BLOCKED));
// client 的第一條命令已經被解析好了,直接嘗試執行。
if (processPendingCommandsAndResetClient(c) == C_ERR) {
/* If the client is no longer valid, we avoid
* processing the client later. So we just go
* to the next. */
continue;
}
// 解析并執行 client 命令
processInputBuffer(c);
// 命令執行完成之后,如果 client 中有響應數據需要回寫到客戶端,則將 client 加入到待寫出隊列 clients_pending_write
if (!(c->flags & CLIENT_PENDING_WRITE) && clientHasPendingReplies(c))
clientInstallWriteHandler(c);
}
/* Update processed count on server */
server.stat_io_reads_processed += processed;
return processed;
}1、當客戶端發送命令請求之后,會觸發 Redis 主線程的事件循環,命令處理器 readQueryFromClient 被回調,多線程模式下,則會把 client 加入到 clients_pending_read 任務隊列中去,后面主線程再分配到 I/O 線程去讀取客戶端請求命令;
2、主線程會根據 clients_pending_read 中客戶端數量對IO線程進行取模運算,取模的結果就是客戶端分配給對應IO線程的編號;
3、忙輪詢,等待所有的線程完成讀取客戶端命令的操作,這一步用到了多線程的請求;
4、遍歷 clients_pending_read,執行所有 client 的命令,這里就是在主線程中執行的,命令的執行是單線程的操作。
完成命令的讀取、解析以及執行之后,客戶端命令的響應數據已經存入 client->buf 或者 client->reply 中。
主循環在捕獲 IO 事件的時候,beforeSleep 函數會被調用,進而調用 handleClientsWithPendingWritesUsingThreads ,寫回響應數據給客戶端。
// https://github.com/redis/redis/blob/6.2/src/networking.c#L3662
int handleClientsWithPendingWritesUsingThreads(void) {
int processed = listLength(server.clients_pending_write);
if (processed == 0) return 0; /* Return ASAP if there are no clients. */
// 如果用戶設置的 I/O 線程數等于 1 或者當前 clients_pending_write 隊列中待寫出的 client
// 數量不足 I/O 線程數的兩倍,則不用多線程的邏輯,讓所有 I/O 線程進入休眠,
// 直接在主線程把所有 client 的相應數據回寫到客戶端。
if (server.io_threads_num == 1 || stopThreadedIOIfNeeded()) {
return handleClientsWithPendingWrites();
}
// 喚醒正在休眠的 I/O 線程(如果有的話)。
if (!server.io_threads_active) startThreadedIO();
/* Distribute the clients across N different lists. */
// 和上面的handleClientsWithPendingReadsUsingThreads中的操作一樣分配客戶端給IO線程
listIter li;
listNode *ln;
listRewind(server.clients_pending_write,&li);
int item_id = 0;
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_WRITE;
/* Remove clients from the list of pending writes since
* they are going to be closed ASAP. */
if (c->flags & CLIENT_CLOSE_ASAP) {
listDelNode(server.clients_pending_write, ln);
continue;
}
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c);
item_id++;
}
// 設置當前 I/O 操作為寫出操作,給每個 I/O 線程的計數器設置分配的任務數量,
// 讓 I/O 線程可以開始工作,把寫出緩沖區(client->buf 或 c->reply)中的響應數據回寫到客戶端。
// 可以看到寫回操作也是多線程執行的
io_threads_op = IO_THREADS_OP_WRITE;
for (int j = 1; j < server.io_threads_num; j++) {
int count = listLength(io_threads_list[j]);
setIOPendingCount(j, count);
}
// 主線程自己也會去執行讀取客戶端請求命令的任務,以達到最大限度利用 CPU。
listRewind(io_threads_list[0],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
writeToClient(c,0);
}
listEmpty(io_threads_list[0]);
/* Wait for all the other threads to end their work. */
// 等待所有的線程完成對應的工作
while(1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++)
pending += getIOPendingCount(j);
if (pending == 0) break;
}
// 最后再遍歷一次 clients_pending_write 隊列,檢查是否還有 client 的寫出緩沖區中有殘留數據,
// 如果有,那就為 client 注冊一個命令回復器 sendReplyToClient,等待客戶端寫就緒再繼續把數據回寫。
listRewind(server.clients_pending_write,&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
// 檢查 client 的寫出緩沖區是否還有遺留數據。
if (clientHasPendingReplies(c) &&
connSetWriteHandler(c->conn, sendReplyToClient) == AE_ERR)
{
freeClientAsync(c);
}
}
listEmpty(server.clients_pending_write);
/* Update processed count on server */
server.stat_io_writes_processed += processed;
return processed;
}1、也是會將 client 分配給所有的 IO 線程;
2、忙輪詢,等待所有的線程將緩存中的數據寫回給客戶端,這里寫回操作使用的多線程;
3、最后再遍歷 clients_pending_write,為那些還殘留有響應數據的 client 注冊命令回復處理器 sendReplyToClient,等待客戶端可寫之后在事件循環中繼續回寫殘余的響應數據。
通過上面的分析可以得出結論,Redis 多IO線程中多線程的應用
1、解析客戶端的命令的時候用到了多線程,但是對于客戶端命令的執行,使用的還是單線程;
2、給客戶端回復數據的時候,使用到了多線程。
來總結下 Redis 中多線程的執行過程
1、Redis Server 啟動后,主線程會啟動一個時間循環(Event Loop),持續監聽事件;
2、client 到 server 的新連接,會調用 acceptTcpHandler 函數,之后會注冊讀事件 readQueryFromClient 函數,client 發給 server 的數據,都會在這個函數處理;
3、客戶端發送給服務端的數據,不會類似 6.0 之前的版本使用 socket 直接去讀,而是會將 client 放入到 clients_pending_read 中,里面保存了需要進行延遲讀操作的客戶端;
4、處理 clients_pending_read 的函數 handleClientsWithPendingReadsUsingThreads,在每次事件循環的時候都會調用;
1、主線程會根據 clients_pending_read 中客戶端數量對IO線程進行取模運算,取模的結果就是客戶端分配給對應IO線程的編號;
2、忙輪詢,等待所有的線程完成讀取客戶端命令的操作,這一步用到了多線程的請求;
3、遍歷 clients_pending_read,執行所有 client 的命令,這里就是在主線程中執行的,命令的執行是單線程的操作。
5、命令執行完成以后,回復的內容還是會被寫入到 client 的緩存區中,這些 client 和6.0之前的版本處理方式一樣,也是會被放入到 clients_pending_write(待寫回數據的客戶端);
6、6.0 對于clients_pending_write 的處理使用到了多線程;
1、也是會將 client 分配給所有的 IO 線程;
2、忙輪詢,等待所有的線程將緩存中的數據寫回給客戶端,這里寫回操作使用的多線程;
3、最后再遍歷 clients_pending_write,為那些還殘留有響應數據的 client 注冊命令回復處理器 sendReplyToClient,等待客戶端可寫之后在事件循環中繼續回寫殘余的響應數據。
通過上面的分析,我們知道,Redis 的主線程是單線程執行的,所有 Redis 中的單命令,都是原子性的。
所以對于一些場景的操作盡量去使用 Redis 中單命令去完成,就能保證命令執行的原子性。
比如對于上面的讀取-修改-寫回操作可以使用 Redis 中的原子計數器, INCRBY(自增)、DECRBR(自減)、INCR(加1) 和 DECR(減1) 等命令。
這些命令可以直接幫助我們處理并發控制
127.0.0.1:6379> incr test-1 (integer) 1 127.0.0.1:6379> incr test-1 (integer) 2 127.0.0.1:6379> incr test-1 (integer) 3
分析下源碼,看看這個命令是如何實現的
// https://github.com/redis/redis/blob/6.2/src/t_string.c#L617
void incrCommand(client *c) {
incrDecrCommand(c,1);
}
void decrCommand(client *c) {
incrDecrCommand(c,-1);
}
void incrbyCommand(client *c) {
long long incr;
if (getLongLongFromObjectOrReply(c, c->argv[2], &incr, NULL) != C_OK) return;
incrDecrCommand(c,incr);
}
void decrbyCommand(client *c) {
long long incr;
if (getLongLongFromObjectOrReply(c, c->argv[2], &incr, NULL) != C_OK) return;
incrDecrCommand(c,-incr);
}可以看到 INCRBY(自增)、DECRBR(自減)、INCR(加1) 和 DECR(減1)這幾個命令最終都是調用的 incrDecrCommand
// https://github.com/redis/redis/blob/6.2/src/t_string.c#L579
void incrDecrCommand(client *c, long long incr) {
long long value, oldvalue;
robj *o, *new;
// 查找有沒有對應的鍵值
o = lookupKeyWrite(c->db,c->argv[1]);
// 判斷類型,如果value對象不是字符串類型,直接返回
if (checkType(c,o,OBJ_STRING)) return;
// 將字符串類型的value轉換為longlong類型保存在value中
if (getLongLongFromObjectOrReply(c,o,&value,NULL) != C_OK) return;
// 備份舊的value
oldvalue = value;
// 判斷 incr 的值是否超過longlong類型所能表示的范圍
// 長度的范圍,十進制 64 位有符號整數
if ((incr < 0 && oldvalue < 0 && incr < (LLONG_MIN-oldvalue)) ||
(incr > 0 && oldvalue > 0 && incr > (LLONG_MAX-oldvalue))) {
addReplyError(c,"increment or decrement would overflow");
return;
}
// 計算新的 value值
value += incr;
if (o && o->refcount == 1 && o->encoding == OBJ_ENCODING_INT &&
(value < 0 || value >= OBJ_SHARED_INTEGERS) &&
value >= LONG_MIN && value <= LONG_MAX)
{
new = o;
o->ptr = (void*)((long)value);
} else {
new = createStringObjectFromLongLongForValue(value);
// 如果之前的 value 對象存在
if (o) {
// 重寫為 new 的值
dbOverwrite(c->db,c->argv[1],new);
} else {
// 如果之前沒有對應的 value,新設置 value 的值
dbAdd(c->db,c->argv[1],new);
}
}
// 進行通知
signalModifiedKey(c,c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_STRING,"incrby",c->argv[1],c->db->id);
server.dirty++;
addReply(c,shared.colon);
addReply(c,new);
addReply(c,shared.crlf);
}感謝各位的閱讀,以上就是“Redis中命令的原子性是什么”的內容了,經過本文的學習后,相信大家對Redis中命令的原子性是什么這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





