溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇“SQL Server中的聚合函數怎么使用”文章的知識點大部分人都不太理解,所以小編給大家總結了以下內容,內容詳細,步驟清晰,具有一定的借鑒價值,希望大家閱讀完這篇文章能有所收獲,下面我們一起來看看這篇“SQL Server中的聚合函數怎么使用”文章吧。
?聚合函數對一組值執行計算,并返回單個值。
除了 COUNT 外,聚合函數都會忽略 Null 值。 聚合函數經常與 SELECT 語句的 GROUP BY 子句一起使用。
OVER 子句可以跟在除 STRING_AGG、GROUPING 或 GROUPING_ID 函數以外的所有聚合函數后面。
只能在以下位置將聚合函數作為表達式使用:
SELECT 語句的選擇列表(子查詢或外部查詢)。
HAVING 子句。
T-SQL提供的聚合函數一共有13個之多。
avg( [ all | distinct ] expression )
AVG函數用于計算精確型或近似型數據類型的平均值,bit類型除外,忽略null值。AVG函數計算時將計算一組數的總和,然后除以為null的個數,得到平均值
select avg(distinct age) from person -- 查詢person表里的年齡的平均值,相同值只計算一次
MIN函數用于計算最小值,MIN函數可以適用于numeric、char、varchar或datetime、money或smallmoney列,但不能用于bit列。不允許使用聚合函數和子查詢,忽略null值。
MAX函數用于計算最大值,忽略null值。max函數可以使用于numeric、char、varchar、money、smallmoney、或datetime列,但不能用于bit列。不允許使用聚合函數和子查詢。
SUM函數用于求和,只能用于精確或近似數字類型列(bit類型除外),忽略null值,不允許使用聚合函數和子查詢。
count函數用于計算滿足條件的數據項數,返回int數據類型的值。這里的表達式是除text、image或ntext以外任何數據類型的表達式。但不允許使用聚合函數和子查詢。
count(*) : 返回所有的項數,包括null值和重復項。而除了count(*)外,其他任何形式的count()函數都會忽略Null行。
count(all 表達式):返回非空的項數。
count(distinct 表達式):返回唯一非空的項數
注意:count(字段名),如果字段名為NULL,則count函數不會統計。例如count(name),如果name為空,則不會統計到結果
select count(distinct age) from person -- 查詢person表里的年齡唯一且非空的項數
返回組中的項數。 COUNT_BIG 的用法與 COUNT 函數類似。 兩個函數唯一的差別是它們的返回值。 COUNT_BIG 始終返回 bigint 數據類型值。 COUNT 始終返回 int 數據類型值。
這里的expression必須是一個數值表達式,不允許使用聚合函數和子查詢。表達式的值是精確或近似數值類型,但不包括bit數據類型。將忽略null值。
返回指定表達式中所有值的總體標準偏差。
VAR函數用于計算指定表達式中所有值的方差。 這里的expression表達式必須是一個數值表達式,不允許使用聚合函數和子查詢。表達式的值是精確或近似數值類型,但不包括bit數據類型,將忽略null值。
返回指定表達式中所有值的總體統計方差。
返回組中各值的校驗和。 將忽略 Null 值。CHECKSUM_AGG 可用于檢測表中的更改。表中行的順序不影響 CHECKSUM_AGG 的結果。此外,CHECKSUM_AGG 函數還可與 DISTINCT 關鍵字和 GROUP BY 子句一起使用。如果表達式列表中的某個值發生更改,則列表的校驗和通常也會更改。但只在極少數情況下,校驗值會保持不變。
CHECKSUM_AGG ( [ ALL | DISTINCT ] expression )
參數說明:
ALL:對所有的值進行聚合函數運算。 ALL 為默認值。
DISTINCT :指定 CHECKSUM_AGG 返回唯一校驗值。
expression :一個整數表達式。 不允許使用聚合函數和子查詢。
SELECT CHECKSUM_AGG(Account_Age) FROM Account GO UPDATE Account SET Account_Age = 30 WHERE Account_Id = 6 GO SELECT CHECKSUM_AGG(Account_Age) FROM Account
顯示結果如下:
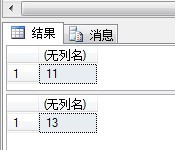
可見隨著表的更改,該系統函數返回的值也變了。此函數的作用正在于此,檢測表的更改。
MS SQL Server的2017新增了STRING_AGG()是一個聚合函數,它將由指定的分隔符分隔將字符串行連接成一個字符串。 它不會在結果字符串的末尾添加分隔符。
以下是STRING_AGG()函數的語法:
STRING_AGG ( input_string, separator ) [ order_clause ]
在這個語法中:
input_string是串聯時可以轉換為VARCHAR和NVARCHAR的類型。
separator是結果字符串的分隔符。它可以是文字或變量。
order_clause使用WITHIN GROUP子句指定連接結果的排序順序:
WITHIN GROUP ( ORDER BY expression [ ASC | DESC ] )
STRING_AGG()忽略NULL,并且在執行連接時不會為NULL添加分隔符。
下面將使用示例數據庫中的sales.customers表進行演示:
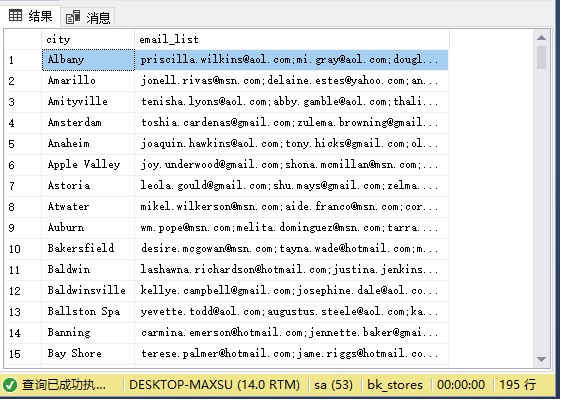
此示例使用STRING_AGG()函數生成城市客戶的電子郵件列表:
SELECT city, STRING_AGG(email,';') email_list FROM sales.customers GROUP BY city;
執行上面查詢語句,得到以下結果:
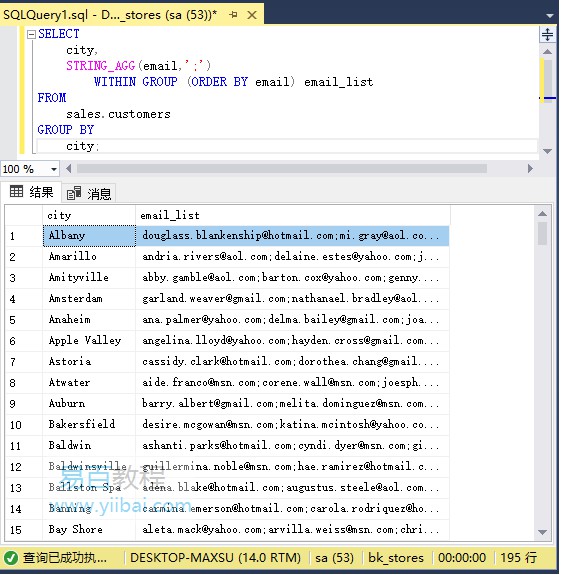
要對email列表進行排序,請使用WITHIN GROUP子句:
SELECT city, STRING_AGG(email,';') WITHIN GROUP (ORDER BY email) email_list FROM sales.customers GROUP BY city;
執行上面查詢語句,得到以下結果:
注意:STRING_SPLIT()函數:一個表值函數,它根據指定的分隔符將字符串拆分為子字符串行。
SELECT value FROM STRING_SPLIT('Lorem ipsum dolor sit amet.', ' ');SQL Server 2019引入了新函數Approx_Count_distinct以提供行的近似計數。Count(distinct())函數提供實際的行數。
該函數APPROX_COUNT_DISTINCT應該使用較少的內存和CPU資源,以便可以獲取數據結果而不會出現任何問題,例如溢出到磁盤或CPU峰值。這對于數十億行的需求很有用。
CUBE 生成的結果集顯示了所選列中值的所有組合的聚合。
ROLLUP 生成的結果集顯示了所選列中值的某一層次結構的聚合。
查詢出插入的全部數據:
select * from dbo.PeopleInfo
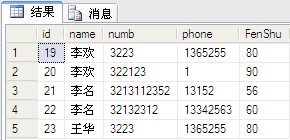
select [name],numb,sum(fenshu) from dbo.PeopleInfo group by [name],numb //用group by select [name],numb,sum(fenshu) from dbo.PeopleInfo group by [name],numb with cube; //用with cube select [name],numb,sum(fenshu) from dbo.PeopleInfo group by [name],numb with rollup //用with rollup
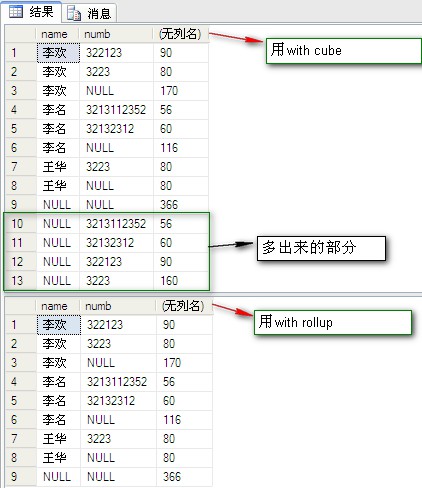
當行由 CUBE 或 ROLLUP 運算符添加時,該函數將導致附加列的輸出值為 1;當行不由 CUBE 或 ROLLUP 運算符添加時,該函數將導致附加列的輸出值為 0。
僅在與包含 CUBE 或 ROLLUP 運算符的 GROUP BY 子句相關聯的選擇列表中才允許分組。
select [name],numb,grouping(numb) from dbo.PeopleInfo group by [name],numb with rollup
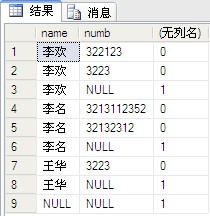
僅當指定了 GROUP BY 時,GROUPING_ID 才能在 SELECT 列表、HAVING 或 ORDER BY 子句中使用。 使用 GROUPING_ID 標識分組級別下面的示例返回按 AdventureWorks2012 數據庫的 Name 和 Title 匯總的雇員計數以及 Name, 和公司總計。 GROUPING_ID() 用于為 Title 列中的每行創建一個值以標識聚合級別。
SELECT D.Name ,CASE WHEN GROUPING_ID(D.Name, E.JobTitle) = 0 THEN E.JobTitle WHEN GROUPING_ID(D.Name, E.JobTitle) = 1 THEN N'Total: ' + D.Name WHEN GROUPING_ID(D.Name, E.JobTitle) = 3 THEN N'Company Total:' ELSE N'Unknown' END AS N'Job Title' ,COUNT(E.BusinessEntityID) AS N'Employee Count' FROM HumanResources.Employee E INNER JOIN HumanResources.EmployeeDepartmentHistory DH ON E.BusinessEntityID = DH.BusinessEntityID INNER JOIN HumanResources.Department D ON D.DepartmentID = DH.DepartmentID WHERE DH.EndDate IS NULL AND D.DepartmentID IN (12,14) GROUP BY ROLLUP(D.Name, E.JobTitle);
很多聚合函數都可以用作窗口函數的運算,如SUM,AVG,MAX,MIN。聚合開窗函數只能使用PARTITION BY子句或都不帶任何語句,ORDER BY不能與聚合開窗函數一同使用。例如,查詢雇員的定單總數及定單信息。
WITH OrderInfo AS ( SELECT COUNT(OrderID) OVER(PARTITION BY EmployeeID) AS TotalCount,OrderID,CustomerID, EmployeeID,OrderDate FROM Orders (NOLOCK) ) SELECT OrderID,CustomerID, EmployeeID ,OrderDate,TotalCount From OrderInfo ORDER BY EmployeeID
如果窗口函數不使用PARTITION BY 語句的話,那么就是不對數據進行分組,聚合函數計算所有的行的值。
WITH OrderInfo AS ( SELECT COUNT(OrderID) OVER() AS Count,OrderID,CustomerID, EmployeeID,OrderDate FROM Orders (NOLOCK) )
以上就是關于“SQL Server中的聚合函數怎么使用”這篇文章的內容,相信大家都有了一定的了解,希望小編分享的內容對大家有幫助,若想了解更多相關的知識內容,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





