溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“python beautifulsoup4模塊怎么用”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“python beautifulsoup4模塊怎么用”吧!
BeautifulSoup4 是一款 python 解析庫,主要用于解析 HTML 和 XML,在爬蟲知識體系中解析 HTML 會比較多一些,
該庫安裝命令如下:
pip install beautifulsoup4
BeautifulSoup 在解析數據時,需依賴第三方解析器,常用解析器與優勢如下所示:
python 標準庫 html.parser:python 內置標準庫,容錯能力強;
lxml 解析器:速度快,容錯能力強;
html5lib:容錯性最強,解析方式與瀏覽器一致。
接下來用一段自定義的 HTML 代碼來演示 beautifulsoup4 庫的基本使用,測試代碼如下:
<html> <head> <title>測試bs4模塊腳本</title> </head> <body> <h2>橡皮擦的爬蟲課</h2> <p>用一段自定義的 HTML 代碼來演示</p> </body> </html>
使用 BeautifulSoup 對其進行簡單的操作,包含實例化 BS 對象,輸出頁面標簽等內容。
from bs4 import BeautifulSoup
text_str = """<html>
<head>
<title>測試bs4模塊腳本</title>
</head>
<body>
<h2>橡皮擦的爬蟲課</h2>
<p>用1段自定義的 HTML 代碼來演示</p>
<p>用2段自定義的 HTML 代碼來演示</p>
</body>
</html>
"""
# 實例化 Beautiful Soup 對象
soup = BeautifulSoup(text_str, "html.parser")
# 上述是將字符串格式化為 Beautiful Soup 對象,你可以從一個文件進行格式化
# soup = BeautifulSoup(open('test.html'))
print(soup)
# 輸入網頁標題 title 標簽
print(soup.title)
# 輸入網頁 head 標簽
print(soup.head)
# 測試輸入段落標簽 p
print(soup.p) # 默認獲取第一個我們可以通過 BeautifulSoup 對象,直接調用網頁標簽,這里存在一個問題,通過 BS 對象調用標簽只能獲取排在第一位置上的標簽,如上述代碼中,只獲取到了一個 p 標簽,如果想要獲取更多內容,請繼續閱讀。
學習到這里,我們需要了解 BeautifulSoup 中的 4 個內置對象:
BeautifulSoup:基本對象,整個 HTML 對象,一般當做 Tag 對象看即可;
Tag:標簽對象,標簽就是網頁中的各個節點,例如 title,head,p;
NavigableString:標簽內部字符串;
Comment:注釋對象,爬蟲里面使用場景不多。
下述代碼為你演示這幾種對象出現的場景,注意代碼中的相關注釋:
from bs4 import BeautifulSoup
text_str = """<html>
<head>
<title>測試bs4模塊腳本</title>
</head>
<body>
<h2>橡皮擦的爬蟲課</h2>
<p>用1段自定義的 HTML 代碼來演示</p>
<p>用2段自定義的 HTML 代碼來演示</p>
</body>
</html>
"""
# 實例化 Beautiful Soup 對象
soup = BeautifulSoup(text_str, "html.parser")
# 上述是將字符串格式化為 Beautiful Soup 對象,你可以從一個文件進行格式化
# soup = BeautifulSoup(open('test.html'))
print(soup)
print(type(soup)) # <class 'bs4.BeautifulSoup'>
# 輸入網頁標題 title 標簽
print(soup.title)
print(type(soup.title)) # <class 'bs4.element.Tag'>
print(type(soup.title.string)) # <class 'bs4.element.NavigableString'>
# 輸入網頁 head 標簽
print(soup.head)對于 Tag 對象,有兩個重要的屬性,是 name 和 attrs
from bs4 import BeautifulSoup text_str = """<html> <head> <title>測試bs4模塊腳本</title> </head> <body> <h2>橡皮擦的爬蟲課</h2> <p>用1段自定義的 HTML 代碼來演示</p> <p>用2段自定義的 HTML 代碼來演示</p> <a href="http://www.csdn.net" rel="external nofollow" rel="external nofollow" >CSDN 網站</a> </body> </html> """ # 實例化 Beautiful Soup 對象 soup = BeautifulSoup(text_str, "html.parser") print(soup.name) # [document] print(soup.title.name) # 獲取標簽名 title print(soup.html.body.a) # 可以通過標簽層級獲取下層標簽 print(soup.body.a) # html 作為一個特殊的根標簽,可以省略 print(soup.p.a) # 無法獲取到 a 標簽 print(soup.a.attrs) # 獲取屬性
上述代碼演示了獲取 name 屬性和 attrs 屬性的用法,其中 attrs 屬性得到的是一個字典,可以通過鍵獲取對應的值。
獲取標簽的屬性值,在 BeautifulSoup 中,還可以使用如下方法:
print(soup.a["href"])
print(soup.a.get("href"))獲取 NavigableString 對象 獲取了網頁標簽之后,就要獲取標簽內文本了,通過下述代碼進行。
print(soup.a.string)
除此之外,你還可以使用 text 屬性和 get_text() 方法獲取標簽內容。
print(soup.a.string) print(soup.a.text) print(soup.a.get_text())
還可以獲取標簽內所有文本,使用 strings 和 stripped_strings 即可。
print(list(soup.body.strings)) # 獲取到空格或者換行 print(list(soup.body.stripped_strings)) # 去除空格或者換行
擴展標簽/節點選擇器之遍歷文檔樹
直接子節點
標簽(Tag)對象的直接子元素,可以使用 contents 和 children 屬性獲取。
from bs4 import BeautifulSoup text_str = """<html> <head> <title>測試bs4模塊腳本</title> </head> <body> <div id="content"> <h2>橡皮擦的爬蟲課<span>最棒</span></h2> <p>用1段自定義的 HTML 代碼來演示</p> <p>用2段自定義的 HTML 代碼來演示</p> <a href="http://www.csdn.net" rel="external nofollow" rel="external nofollow" >CSDN 網站</a> </div> <ul class="nav"> <li>首頁</li> <li>博客</li> <li>專欄課程</li> </ul> </body> </html> """ # 實例化 Beautiful Soup 對象 soup = BeautifulSoup(text_str, "html.parser") # contents 屬性獲取節點的直接子節點,以列表的形式返回內容 print(soup.div.contents) # 返回列表 # children 屬性獲取的也是節點的直接子節點,以生成器的類型返回 print(soup.div.children) # 返回 <list_iterator object at 0x00000111EE9B6340>
請注意以上兩個屬性獲取的都是直接子節點,例如 h2 標簽內的后代標簽 span ,不會單獨獲取到。
如果希望將所有的標簽都獲取到,使用 descendants 屬性,它返回的是一個生成器,所有標簽包括標簽內的文本都會單獨獲取。
print(list(soup.div.descendants))
其它節點的獲取(了解即可,即查即用)
parent 和 parents:直接父節點和所有父節點;
next_sibling,next_siblings,previous_sibling,previous_siblings:分別表示下一個兄弟節點、下面所有兄弟節點、上一個兄弟節點、上面所有兄弟節點,由于換行符也是一個節點,所有在使用這幾個屬性時,要注意一下換行符;
next_element,next_elements,previous_element,previous_elements:這幾個屬性分別表示上一個節點或者下一個節點,注意它們不分層次,而是針對所有節點,例如上述代碼中 div 節點的下一個節點是 h2,而 div 節點的兄弟節點是 ul。
文檔樹搜索相關函數
第一個要學習的函數就是 find_all() 函數,原型如下所示:
find_all(name,attrs,recursive,text,limit=None,**kwargs)
name:該參數為 tag 標簽的名字,例如 find_all('p') 是查找所有的 p 標簽,可接受標簽名字符串、正則表達式與列表;
attrs:傳入的屬性,該參數可以字典的形式傳入,例如 attrs={'class': 'nav'},返回的結果是 tag 類型的列表;
上述兩個參數的用法示例如下:
print(soup.find_all('li')) # 獲取所有的 li
print(soup.find_all(attrs={'class': 'nav'})) # 傳入 attrs 屬性
print(soup.find_all(re.compile("p"))) # 傳遞正則,實測效果不理想
print(soup.find_all(['a','p'])) # 傳遞列表recursive:調用 find_all () 方法時,BeautifulSoup 會檢索當前 tag 的所有子孫節點,如果只想搜索 tag 的直接子節點,可以使用參數 recursive=False,測試代碼如下:
print(soup.body.div.find_all(['a','p'],recursive=False)) # 傳遞列表
text:可以檢索文檔中的文本字符串內容,與 name 參數的可選值一樣,text 參數接受標簽名字符串、正則表達式、 列表;
print(soup.find_all(text='首頁')) # ['首頁']
print(soup.find_all(text=re.compile("^首"))) # ['首頁']
print(soup.find_all(text=["首頁",re.compile('課')])) # ['橡皮擦的爬蟲課', '首頁', '專欄課程']limit:可以用來限制返回結果的數量;
kwargs:如果一個指定名字的參數不是搜索內置的參數名,搜索時會把該參數當作 tag 的屬性來搜索。這里要按 class 屬性搜索,因為 class 是 python 的保留字,需要寫作 class_,按 class_ 查找時,只要一個 CSS 類名滿足即可,如需多個 CSS 名稱,填寫順序需要與標簽一致。
print(soup.find_all(class_ = 'nav')) print(soup.find_all(class_ = 'nav li'))
還需要注意網頁節點中,有些屬性在搜索中不能作為kwargs參數使用,比如html5 中的 data-*屬性,需要通過attrs參數進行匹配。
與
find_all()方法用戶基本一致的其它方法清單如下:
find():函數原型find( name , attrs , recursive , text , **kwargs ),返回一個匹配元素;
find_parents(),find_parent():函數原型 find_parent(self, name=None, attrs={}, **kwargs),返回當前節點的父級節點;
find_next_siblings(),find_next_sibling():函數原型 find_next_sibling(self, name=None, attrs={}, text=None, **kwargs),返回當前節點的下一兄弟節點;
find_previous_siblings(),find_previous_sibling():同上,返回當前的節點的上一兄弟節點;
find_all_next(),find_next(),find_all_previous () ,find_previous ():函數原型 find_all_next(self, name=None, attrs={}, text=None, limit=None, **kwargs),檢索當前節點的后代節點。
CSS 選擇器 該小節的知識點與pyquery有點撞車,核心使用select()方法即可實現,返回數據是列表元組。
通過標簽名查找,soup.select("title");
通過類名查找,soup.select(".nav");
通過 id 名查找,soup.select("#content");
通過組合查找,soup.select("div#content");
通過屬性查找,soup.select("div[id='content'"),soup.select("a[href]");
在通過屬性查找時,還有一些技巧可以使用,例如:
^=:可以獲取以 XX 開頭的節點:
print(soup.select('ul[class^="na"]'))*=:獲取屬性包含指定字符的節點:
print(soup.select('ul[class*="li"]'))BeautifulSoup 的基礎知識掌握之后,在進行爬蟲案例的編寫,就非常簡單了,本次要采集的目標網站 ,該目標網站有大量的藝術二維碼,可以供設計大哥做參考。
下述應用到了 BeautifulSoup 模塊的標簽檢索與屬性檢索,完整代碼如下:
from bs4 import BeautifulSoup
import requests
import logging
logging.basicConfig(level=logging.NOTSET)
def get_html(url, headers) -> None:
try:
res = requests.get(url=url, headers=headers, timeout=3)
except Exception as e:
logging.debug("采集異常", e)
if res is not None:
html_str = res.text
soup = BeautifulSoup(html_str, "html.parser")
imgs = soup.find_all(attrs={'class': 'lazy'})
print("獲取到的數據量是", len(imgs))
datas = []
for item in imgs:
name = item.get('alt')
src = item["src"]
logging.info(f"{name},{src}")
# 獲取拼接數據
datas.append((name, src))
save(datas, headers)
def save(datas, headers) -> None:
if datas is not None:
for item in datas:
try:
# 抓取圖片
res = requests.get(url=item[1], headers=headers, timeout=5)
except Exception as e:
logging.debug(e)
if res is not None:
img_data = res.content
with open("./imgs/{}.jpg".format(item[0]), "wb+") as f:
f.write(img_data)
else:
return None
if __name__ == '__main__':
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36"
}
url_format = "http://www.9thws.com/#p{}"
urls = [url_format.format(i) for i in range(1, 2)]
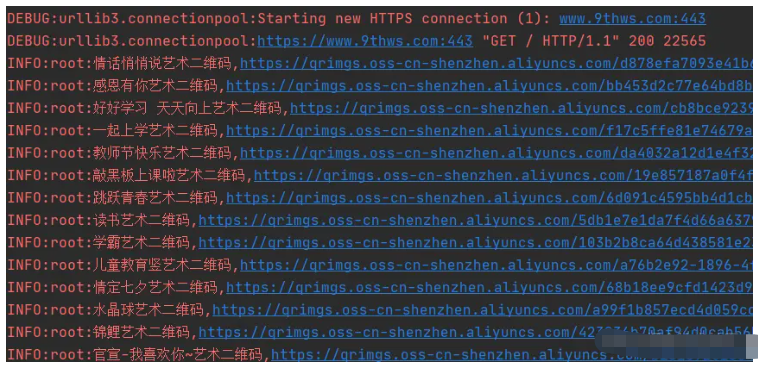
get_html(urls[0], headers)本次代碼測試輸出采用的 logging 模塊實現,效果如下圖所示。 測試僅采集了 1 頁數據,如需擴大采集范圍,只需要修改 main 函數內頁碼規則即可。 ==代碼編寫過程中,發現數據請求是類型是 POST,數據返回格式是 JSON,所以本案例僅作為 BeautifulSoup 的上手案例吧==
到此,相信大家對“python beautifulsoup4模塊怎么用”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





