溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“C++ 引用與內聯函數實例分析”,在日常操作中,相信很多人在C++ 引用與內聯函數實例分析問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”C++ 引用與內聯函數實例分析”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
引用是C++的特性的之一,不過C++沒有沒有給引用特意出一個關鍵字,使用了操作符的重載。引用在C++中很常見,常見就意味著它很重要。我們分兩個境界來談談引用,初階是我們能在書上看到的.
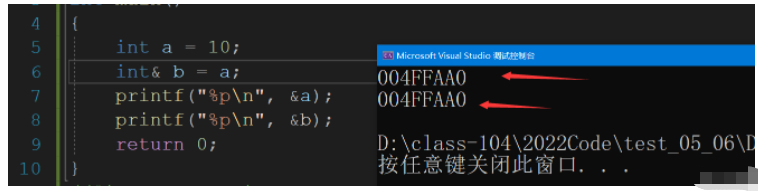
引用不是新定義一個變量,而是給已存在變量取了一個別名,編譯器不會為引用變量開辟內存空間,它和它引用的變量共用同一塊內存空間 .所謂的取別名,就是取外號,張三在朋友面前可能叫三子,在長輩面前可能叫三兒,但是無論是叫三子還是三兒,他們叫的就是張三,這是無可否認的.引用的符號&和我們取地址的&操作符一樣的,后面我們就會知道這是操作符構成重載的原因.
我們可以理解所謂的引用.
#include <stdio.h>
int main()
{
int a = 10;
int& b = a; // b 是 a的一個別名
printf("%p\n", &a);
printf("%p\n", &b);
return 0;
}
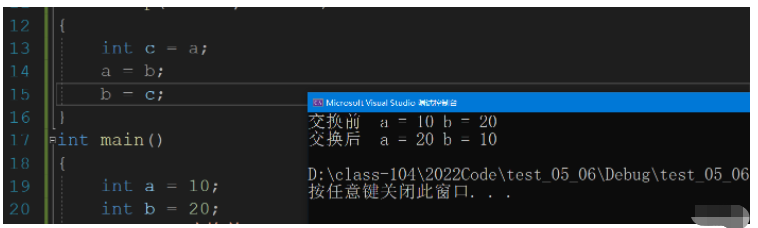
引用有很多優點,其中有一個就是可以簡化代碼,我們在C語言中寫過如何交換兩個整型數據,需要借助一維指針,但是這有一點麻煩,使用引用就可以很好的解決這個問題.
#include <stdio.h>
void swap(int& a, int& b)
{
int c = a;
a = b;
b = c;
}
int main()
{
int a = 10;
int b = 20;
printf("交換前 a = %d b = %d\n", a, b);
swap(a, b);
printf("交換后 a = %d b = %d\n", a, b);
return 0;
}
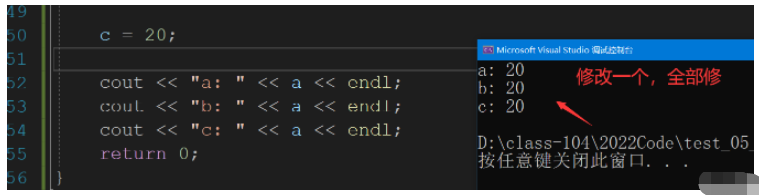
我們無論給變量取多少外號,但是這些外號所指向的空間是一樣的,我們只要修改一個外號的空間,就會導致其他外號值得修改.
#include <iostream>
using namespace std;
int main()
{
int a = 10;
int& b = a; //b 是 a 的別名
int& c = b; //還可以對c取別名
return 0;
}
int main()
{
int a = 10;
int& b = a; //b 是 a 的別名
int& c = b; //還可以對c取別名
c = 20;
cout << "a: " << a << endl;
cout << "b: " << a << endl;
cout << "c: " << a << endl;
return 0;
}
即使引用很好使用,但是我們還要關注他們的一些特性.
這個要求很嚴格,我們必須在引用的時候給他初始化,否則就會報錯.
#include <iostream>
using namespace std;
int main()
{
int a = 10;
int& b;
return 0;
}
這個特性我們前面和大家分享過了,我們可以對一個變量多次取外號,每一個外號都是是這個變量的別名,我們甚至可以對外號取外號,不過我們一般不這么干.
這個特性完美的闡釋了引用的專一性,一旦我們給某一個變量起了一個別名,這個別名就會跟著這個變量一輩子,絕對不會在成為其他的變量的別名.這個也是和指針很大的區別,指針比較花心.
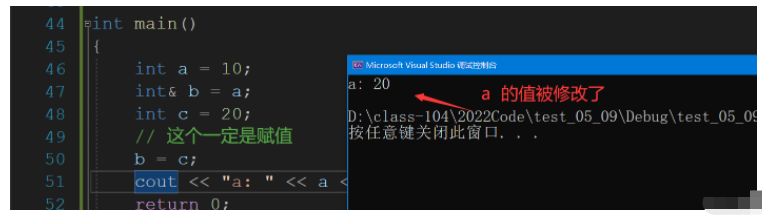
這個我們就不通過代碼打印各個變量的地址了.,我們觀看另外一種現象,通過觀察我們看到a的值也被修改了,可以確定 b 仍舊a的別名.
int main()
{
int a = 10;
int& b = a;
int c = 20;
// 這個一定是賦值
b = c;
cout << "a: " << a << endl;
return 0;
}
我們已經看到引用的優點,但是這是引用的基礎用法,要是到那里,我們一般看書都可以做到,現在要看看引用更加詳細的知識.
我們在C語言中,專門分享過const相關的知識,那么我們如何對const修飾的變量取別名呢?這是一個小問題.
const int a = 10;
我們看看下面的方法.
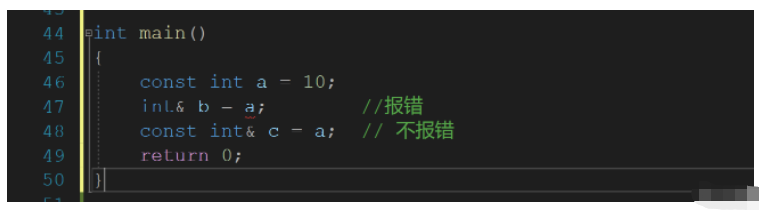
int main()
{
const int a = 10;
int& b = a; //報錯
const int& c = a; // 不報錯
return 0;
}
到這里我們就可以發現,我們取別名的時候也用const修飾就可以了,這是我們從現象中的得出的結論,但是這又是因為什么呢?我們需要知道他們的原理.
不知道大家有沒有在學習中看到過這樣一種現象,對于一個文件,我們可能存在僅僅閱讀的權限,自己無法修改,但是其他的人有可能有資格修改,這就是權限的能力,const修飾變量后,使得變量的加密程度更加高了,我們取別名的時候,總不能把這個權限給過擴大了,編譯器這是不允許的,也就是說我們取別名的時候,權限只能往低了走,絕對不能比原來的高.
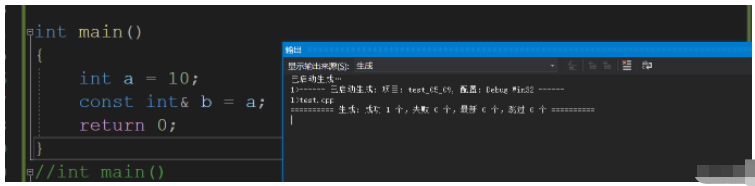
下面就是把權限往縮小了給
int main()
{
int a = 10;
const int& b = a;
return 0;
}
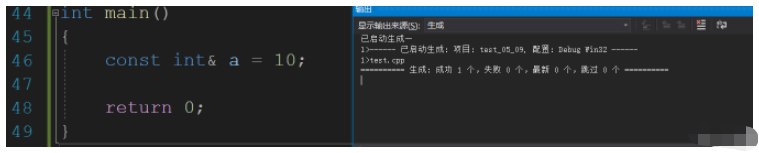
給常量取別名必須要是const修飾的,因為常量不能修改.
int main()
{
const int& a = 10;
return 0;
}
這個是語法的一個知識點,我們記住就可以了,現在我們就要看看為什么這個代碼會可以運行.
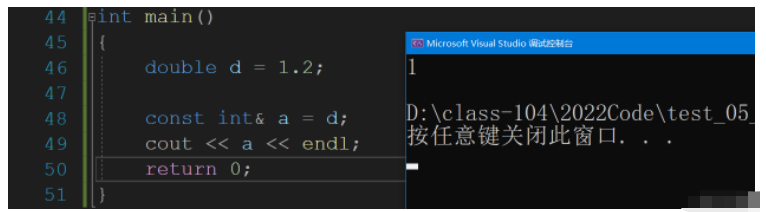
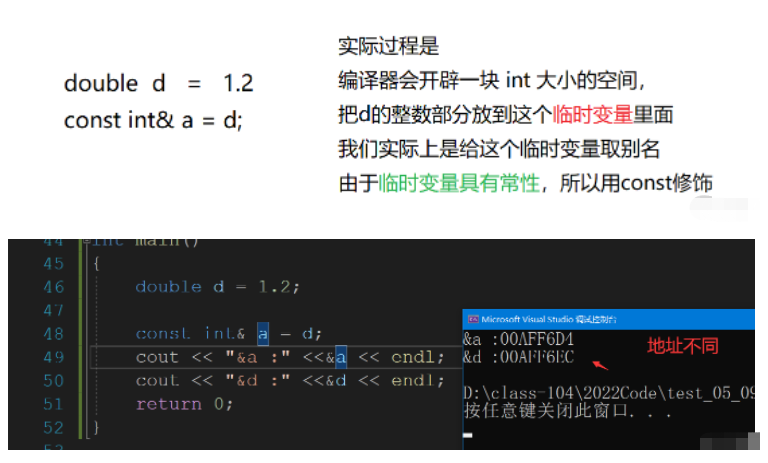
我們常引用 還有最后一個問題,如果我們是double類型的變量,如何給取一個int類型的別名?
需要用const修飾,而且會發生截斷,
int main()
{
double d = 1.2;
const int& a = d; //需要用const修飾
cout << a << endl;
return 0;
}
它的本質不是取別名,而類似于給常量取別名,而且還會發生截斷.這個說截斷也不太合適,這會產生一個臨時變量,我把原理圖放在下面.
int main()
{
double d = 1.2;
const int& a = d;
cout << "&a :" <<&a << endl;
cout << "&d :" <<&d << endl;
return 0;
}
我們需要來看看引用的使用場景,它主要有兩大作用.
做參數
做返回值
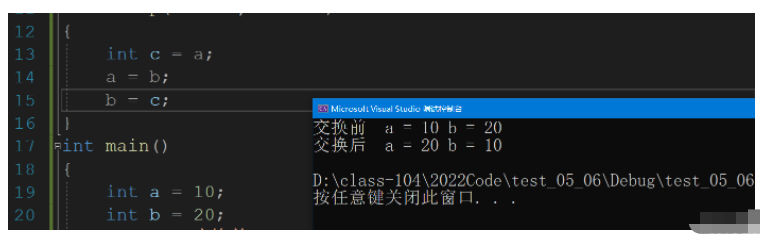
我們可以使用引用來交換兩個整型數據.
#include <stdio.h>
void swap(int& a, int& b)
{
int c = a;
a = b;
b = c;
}
int main()
{
int a = 10;
int b = 20;
printf("交換前 a = %d b = %d\n", a, b);
swap(a, b);
printf("交換后 a = %d b = %d\n", a, b);
return 0;
}
但是使用引用作為參數可能會出現權限不太匹配的錯誤,所以說我們需要const修飾.
下面就是由于權限問題,我們沒有辦法來給常量卻別名,這就需要const修飾.
void func(int& a)
{
}
int main()
{
int a = 10;
double b = 10.2;
func(a);
func(10);
func(b);
return 0;
}
我們先看看返回值的原理,再說說引用做返回值.
返回值的原理:
我們需要談談編譯器是如何使用返回值的,以下面的代碼為例.
int func()
{
int n = 1;
n++;
return n;
}
int main()
{
int ret = func();
return 0;
}編譯器會看這個返回值的空間大不大,如果不大,就把的數據放到一個寄存器中,如果很大,看編譯器的機制,有的編譯器甚至可能在main函數中開辟這個空間來臨時保存數據.
這是由于當函數結束后,函數棧幀會銷毀,n的空間也會被釋放,所以要有一個寄存器來保存數據.
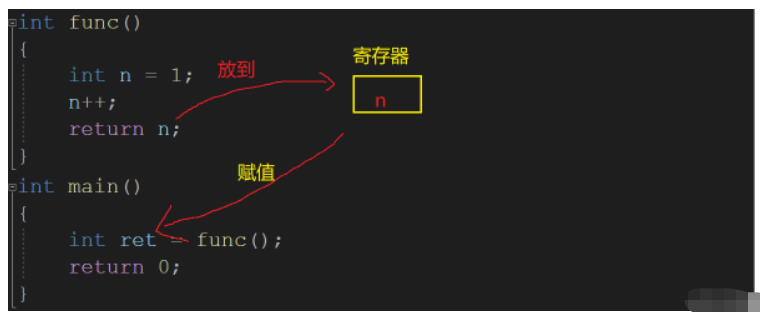
下面的代碼就可以表現出來:
int main()
{
int& ret = func();
return 0;
}
引用做返回值會有很大的要求,這個和我們普通的返回值可不一樣.說實話,我不想和大家分享的那么深,但是已經到這里了,只能這樣了.
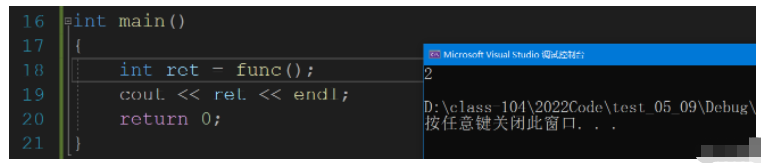
下面的代碼,我們可以理解,就是給靜態變量n取一個別名,我們把它返回到了ret.
int& func()
{
static int n = 1;
n++;
return n;
}
int main()
{
int ret = func();
cout << ret << endl;
return 0;
}
也就是說我們n取一個別名,把這個別名作為返回值返回給函數調用者.
int& func()
{
static int n = 1;
n++;
cout << &n << endl;
return n;
}
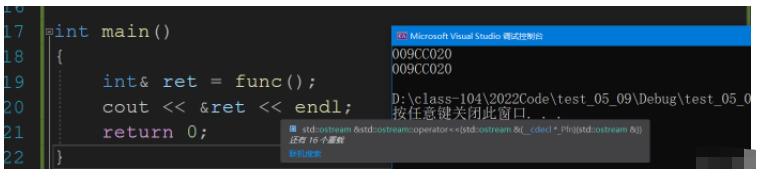
int main()
{
int& ret = func(); // 注意 是 int&
cout << &ret << endl;
return 0;
}
注意事項:
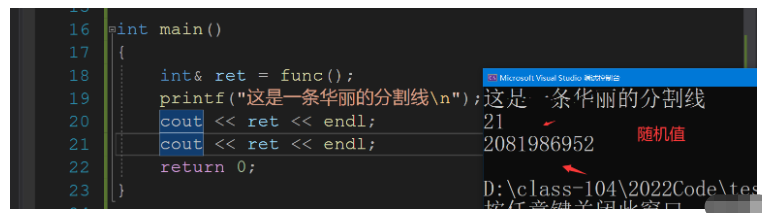
到這里我們就可以看看引用做返回值的注意事項了,我們一定要保證做返回值得引用得數據在函數棧幀銷毀后空間不被釋放,否則就會發生下面得事情.
我們得到的是一個隨機值,我們拿到了變量 n 的別名,但是在func結束后空間就被釋放了,下一次函數的調用函數棧幀會覆這篇空間,運氣好的話,我們有可能拿到準確值,但是無論如何訪問都越界了.
int& func()
{
int n = 1;
n++;
return n;
}
int main()
{
int& ret = func();
printf("這是一條華麗的分割線\n");
cout << ret << endl;
cout << ret << endl;
return 0;
}
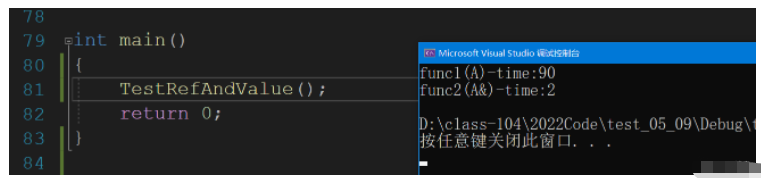
前面我們說了傳參需要有一定的要求,但是這不是說引用做參數不行,我們使用引用傳參不會發生拷貝,這極大的提高了代碼的效率.
我們定義一個大點的結構體,來看看拷貝傳參和引用傳參的效率.一般情況下相差大概20倍左右.
typedef struct A
{
int arr[10000];
} A;
void func1(A a)
{
}
void func2(A& a)
{
}
void TestRefAndValue()
{
A a;
// 以值作為函數參數
size_t begin1 = clock();
for (size_t i = 0; i < 100000; ++i)
func1(a);
size_t end1 = clock();
// 以引用作為函數參數
size_t begin2 = clock();
for (size_t i = 0; i < 100000; ++i)
func2(a);
size_t end2 = clock();
// 分別計算兩個函數運行結束后的時間
cout << "func1(A)-time:" << end1 - begin1 << endl;
cout << "func2(A&)-time:" << end2 - begin2 << endl;
}
int main()
{
TestRefAndValue();
return 0;
}
它們有一個本質的區別,在語法概念上引用就是一個別名,沒有獨立空間,和其引用實體共用同一塊空間 ,但是引用的底層還是開辟空間的,因為引用是按照指針方式來實現.我們看看匯編代碼.
引用不會開辟空間,但是指針會開辟相應的空間.
底層引用和指針是一樣的.
int main()
{
int a = 10;
//語法沒有開辟空間 底層開辟了
int& b = a;
b = 20;
//語法開辟空間 底層也開辟了
int* pa = &a;
*pa = 20;
return 0;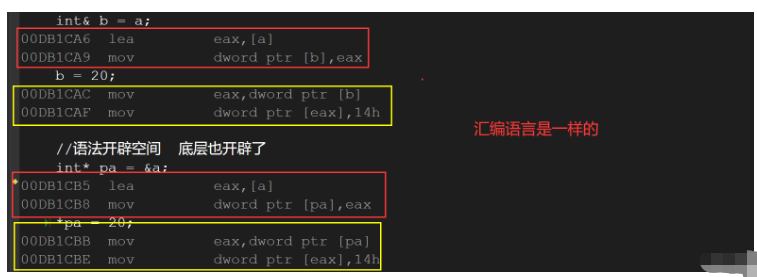
我們來看看它們其他的比較小的區別,我就不詳細舉例了.
引用在定義時必須初始化,指針沒有要求
引用在初始化時引用一個實體后,就不能再引用其他實體,而指針可以在任何時候指向任何一個同類型實體
沒有NULL引用,但有NULL指針
在sizeof中含義不同:引用結果為引用類型的大小,但指針始終是地址空間所占字節個數(32位平臺下占4個字節)
引用自加即引用的實體增加1,指針自加即指針向后偏移一個類型的大小
有多級指針,但是沒有多級引用
訪問實體方式不同,指針需要顯式解引用,引用編譯器自己處理
引用比指針使用起來相對更安全
以inline修飾的函數叫做內聯函數,編譯時C++編譯器會在調用內聯函數的地方展開,沒有函數壓棧的開銷,內聯函數提升程序運行的效率,本質來說就和我們的宏比較相似.
記住我們不關心他們在那個過程中展開,只需要記住他會展開就可以了.我么看看內聯函數的知識點.
對于一些比較小的函數,我們總是調用函數開銷比較的,我們是不是存在一個方法減少這個開銷呢?C語言通過宏來實現,C++支持C語言,所以我們可以通過行來實現,那么你給我寫一個兩數現相加的宏,要是你寫的和下面的不一樣,就代表你忘記了一部分知識點.
#define ADD(x,y) ((x) + (y)) //不帶 ; 括號要帶
我們就可以理解了,宏很好,但是寫出一個正確的宏很困難,但是寫一個函數就不一樣了,所以一些大佬就發明了內斂函數,用來替代宏的部分功能.
函數內聯不內聯不是你說了算,我們用inline修飾就是告訴編譯器這個函數可以展開,至于是否展開還是看編譯器,一般之后展開比較短小的函數,較大的函數不會展開,像遞歸的那些也不可以.
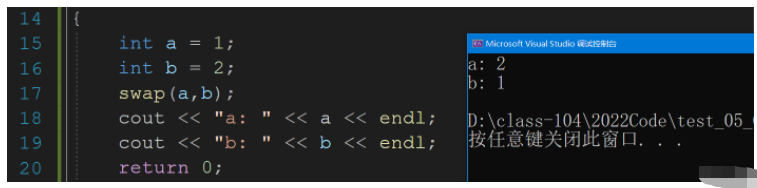
inline void swap(int& x, int& y)
{
int ret = x;
x = y;
y = ret;
}
int main()
{
int a = 1;
int b = 2;
swap(a,b);
cout << "a: " << a << endl;
cout << "b: " << b << endl;
return 0;
}
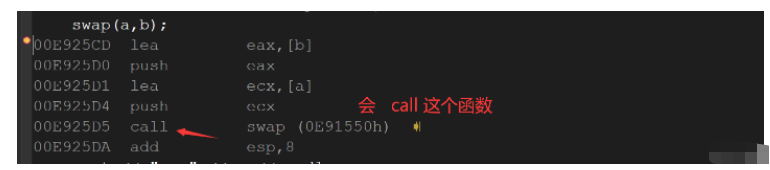
我們來看看內聯函數,如果函數不是內聯了的,匯編語言會call
void swap(int& x, int& y)
{
int ret = x;
x = y;
y = ret;
}
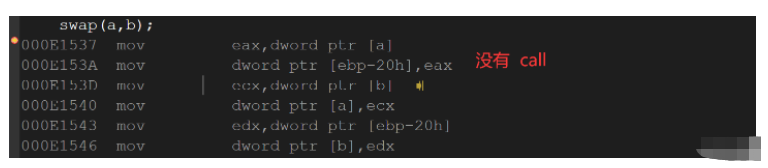
如果在上述函數前增加inline關鍵字將其改成內聯函數,在編譯期間編譯器會用函數體替換函數的調用.
由于我們使用的是VS編譯器,這里需要看看內聯函數的匯編語言.
在release模式下,查看編譯器生成的匯編代碼中是否存在call swap,但是編譯器會發生優化,我們通過debug模式下,但是需要設置.
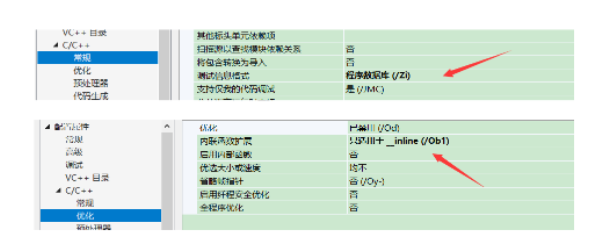
inline修飾的較短函數展開了,沒有call
inline void swap(int& x, int& y)
{
int ret = x;
x = y;
y = ret;
}
我們需要來看看函數的基本的特性
inline是一種以空間換時間的做法,省去調用函數額開銷。所以代碼很長或者有循環 / 遞歸的函數不適宜使用作為內聯函數。
inline 對于編譯器而言只是一個建議,編譯器會自動優化,如果定義為inline的函數體內有循環/遞歸等,編譯器優化時會忽略內聯。
inline不建議聲明和定義分離,分離會導致鏈接錯誤。因為inline被展開,就沒有函數地址了,鏈接就會找不到。
編譯器會自動判別這個函數給不該內聯,要是一個函數比較大,里面存在遞歸,那么還不如不展開呢.一般是10行為依據.
inline void f()
{
cout << "hello" << endl;
cout << "hello" << endl;
cout << "hello" << endl;
cout << "hello" << endl;
cout << "hello" << endl;
cout << "hello" << endl;
cout << "hello" << endl;
cout << "hello" << endl;
cout << "hello" << endl;
cout << "hello" << endl;
cout << "hello" << endl;
cout << "hello" << endl;
cout << "hello" << endl;
cout << "hello" << endl;
cout << "hello" << endl;
cout << "hello" << endl;
cout << "hello" << endl;
cout << "hello" << endl;
}
int main()
{
f();
return 0;
}
如果我們聲明和定義的分離,運行時編譯器會找不到這個函數的地址的.
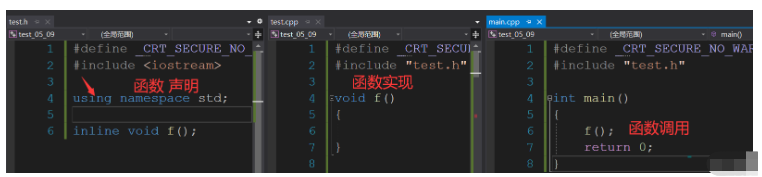

這里我么建議直接把內聯函數直接放到自定義的頭文件中
inline void f()
{
}
到此,關于“C++ 引用與內聯函數實例分析”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





