溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天小編給大家分享一下怎么用Python對Word文件內容進行讀取的相關知識點,內容詳細,邏輯清晰,相信大部分人都還太了解這方面的知識,所以分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后有所收獲,下面我們一起來了解一下吧。
python-docx 是用于創建可修改 微軟 Word 的一個 python 庫,提供全套的 Word 操作,是最常用的 Word 工具。
使用前,先了解幾個概念:
Document:是一個 Word 文檔 對象,不同于 VBA 中 Worksheet 的概念,Document 是獨立的,打開不同的 Word 文檔,就會有不同的 Document 對象,相互之間沒有影響
Paragraph:是段落,一個 Word 文檔由多個段落組成,當在文檔中輸入一個回車鍵,就會成為新的段落,輸入 shift + 回車,不會分段
Run 表示一個節段,每個段落由多個 節段 組成,一個段落中具有相同樣式的連續文本,組成一個節段,所以一個 段落 對象有個 Run 列表。
例如下圖的 word 文檔示意圖:
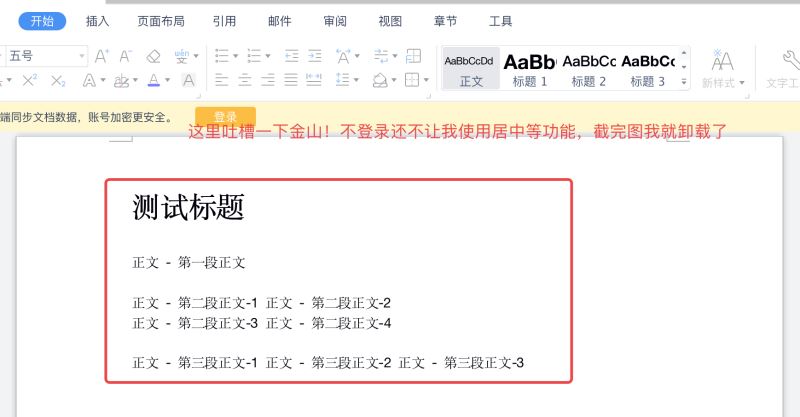
word 文檔結構劃分如下:

安裝:
pip install python-docx 如果安裝速度太慢的話,可以換一個國內的源地址(如下)
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple python-docx
導入:
import docx
from docx import …
導入包與模塊:
from docx import Document
使用方法:
Document(word文件地址)
返回值:
word文件對象
實際上要想讀取一個 word 文檔,主要就是讀取它的段落以及它的表格。無論是段落還是表格,它的內部都是字符串,我們的目的就是讀取這些字符串的內容。
先看一下段落內容的讀取方式:
來源:
document_obj.paragraphs 通過 document 對象的 paragraphs 函數返回一個段落的列表;如果 word 文件存在多個段落,就會有多個段落對象。
使用方法:
通過循環獲取每個段落對象,并調用 text
演示案例腳本如下:
# coding:utf-8
import os
from docx import Document
path = os.path.join(os.getcwd(), 'test_file/文本.docx')
print("\'文本.docx\' 的路徑為:", path) # 調試路徑
doc = Document(path)
for p in doc.paragraphs:
print(p.text)運行結果如下:(PS:文本只是演示,本人非培訓機構的!)


接下來我們看一下如何讀取 word 文件中的表格內容:
來源:
document_obj.tables 通過 document 對象的 paragraphs 函數返回一個表格的列表;里面是一個一個的表格的對象。
使用方法:
同樣通過循環,獲取行與列的內容
返回值:
每個表格字段(字符串)
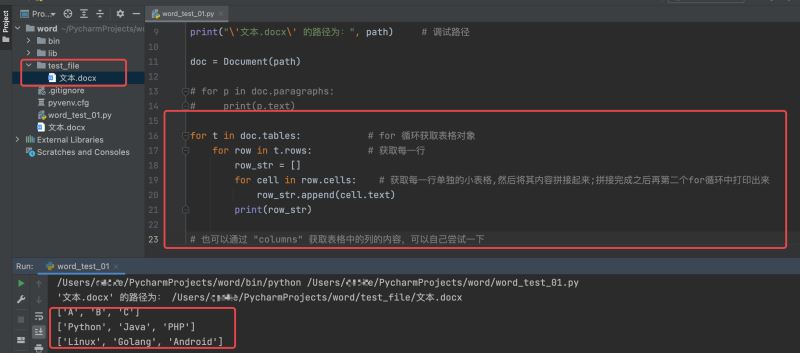
演示案例代碼如下:
# coding:utf-8
import os
from docx import Document
path = os.path.join(os.getcwd(), 'test_file/文本.docx')
print("\'文本.docx\' 的路徑為:", path) # 調試路徑
doc = Document(path)
# for p in doc.paragraphs:
# print(p.text)
for t in doc.tables: # for 循環獲取表格對象
for row in t.rows: # 獲取每一行
row_str = []
for cell in row.cells: # 獲取每一行單獨的小表格,然后將其內容拼接起來;拼接完成之后再第二個for循環中打印出來
row_str.append(cell.text)
print(row_str)
# 也可以通過 "columns" 獲取表格中的列的內容,可以自己嘗試一下運行結果如下:
以上就是“怎么用Python對Word文件內容進行讀取”這篇文章的所有內容,感謝各位的閱讀!相信大家閱讀完這篇文章都有很大的收獲,小編每天都會為大家更新不同的知識,如果還想學習更多的知識,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





