溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天小編給大家分享一下python怎么使用OpenCV進行曝光融合的相關知識點,內容詳細,邏輯清晰,相信大部分人都還太了解這方面的知識,所以分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后有所收獲,下面我們一起來了解一下吧。
曝光融合是一種將使用不同曝光設置拍攝的圖像合成為一張看起來像色調映射的高動態范圍(HDR)圖像的圖像的方法。當我們使用相機拍攝照片時,每個顏色通道只有8位來表示場景的亮度。然而,我們周圍世界的亮度理論上可以從0(黑色)到幾乎無限(直視太陽)。因此,傻瓜相機或移動相機根據場景決定曝光設置,以便使用相機的動態范圍(0-255值)來表示圖像中最有趣的部分。例如,在許多相機中,使用面部檢測來查找面部并設置曝光,使得面部看起來很好。這引出了一個問題-我們可以在不同的曝光設置下拍攝多張照片并拍攝更大范圍的場景亮度嗎?答案是肯定的。傳統上使用HDR成像然后進行色調映射的方式。具體見上篇文章:
HDR成像要求我們知道精確的曝光時間。HDR圖像本身看起來很暗,看起來不太漂亮。DR圖像中的最小強度為0,但理論上沒有最大值。所以我們需要將其值映射到0到255之間,以便我們可以顯示它。將HDR圖像映射到常規的每通道8位彩色圖像的過程稱為色調映射。如您所見,組裝HDR圖像和色調映射有點麻煩。我們不能不使用HDR就使用多個圖像創建色調映射圖像。結果證明我們可以用曝光融合來實現。
應用曝光融合的步驟如下所述:
使用不同曝光拍攝多張圖像

首先,我們需要在不移動相機的情況下捕獲同一場景的一系列圖像。如上所示,序列中的圖像具有不同的曝光。這是通過改變相機的快門速度來實現的。通常,我們選擇一些曝光不足的圖像,一些曝光過度的圖像和一個正確曝光的圖像。
在“正確”曝光的圖像中,選擇快門速度(由相機或攝影師自動選擇),以便每通道8位動態范圍用于表示圖像中最有趣的部分。太暗的區域被剪切為0,而太亮的區域被飽和到255。
在曝光不足的圖像中,快門速度很快,圖像很暗。因此,圖像的8位用于捕獲亮區域,而暗區域被剪切為0。在曝光過度的圖像中,快門速度較慢,因此傳感器捕獲的光線更多,因此圖像更亮。傳感器的8位用于捕獲暗區域的強度,而亮區域飽和到255的值。大多數單反相機都有一個稱為自動曝光包圍(AEB)的功能,只需按一下按鈕,我們就可以在不同曝光下拍攝多張照片。當我們在iPhone中使用HDR模式時,它需要三張照片(安卓可以下載超級相機這個軟件)。
圖像對齊:
即使使用三腳架獲取序列中的圖像也需要對齊,因為即使較小的相機抖動也會降低最終圖像的質量。OpenCV提供了一種使用對齊這些圖像的簡便方法AlignMTB。該算法將所有圖像轉換為中值閾值位圖(MTB)。通過將值1分配給比中值亮度更亮的像素來計算圖像的MTB,否則為0。MTB 對曝光時間不變。因此,可以對準MTB而無需我們指定曝光時間。
圖像融合:
具有不同曝光的圖像捕獲不同范圍的場景亮度。根據Tom Mertens,Jan Kautz和Frank Van Reeth 題為Exposure Fusion的論文。論文見:曝光融合通過僅保留多重曝光圖像序列中的“最佳”部分來計算所需圖像。
作者提出了三個質量指標:
1曝光良好:如果序列中的圖像中的像素接近零或接近255,則不應使用該圖像來查找最終像素值。其值接近中間強度(128)的像素是比較合適的。
2對比度:高對比度通常意味著高品質。因此,對于該像素,給予特定像素的對比度值高的圖像具有更高的權重。
3飽和度:類似地,更飽和的顏色更少被淘汰并且代表更高質量的像素。因此,特定像素的飽和度高的圖像被賦予該像素的更高權重。
三種質量度量用于創建權重圖 該權重圖表示
該權重圖表示 , 圖像在位置處的像素的最終強度中的貢獻
, 圖像在位置處的像素的最終強度中的貢獻 , 對權重圖
, 對權重圖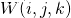 ,進行歸一化,使得對于任何像素
,進行歸一化,使得對于任何像素 所以所有圖像的貢獻總計為1。
所以所有圖像的貢獻總計為1。
結合權重圖使用以下等式組合圖像是很有效的:
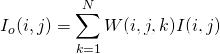
其中,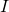 ,是原始圖像,
,是原始圖像,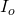 , 是輸出圖像。問題在于,由于像素是從不同曝光的圖像中拍攝的,因此
, 是輸出圖像。問題在于,由于像素是從不同曝光的圖像中拍攝的,因此
使用上述等式獲得的輸出圖像將顯示許多裂縫。該論文的作者使用拉普拉斯金字塔來混合圖像。我們將在以后的文章中介紹這項技術的細節。
幸運的是使用OpenCV,這種圖像曝光融合合并只是使用MergeMertens該類的兩行代碼。請注意,這個名字取決于Exposure Fusion論文的第一作者Tom Mertens 。
代碼地址:
C++:
#include "pch.h"
#include <iostream>
#include <opencv2/opencv.hpp>
#include <vector>
#include <fstream>
using namespace cv;
using namespace std;
// Read Images
void readImages(vector<Mat> &images)
{
int numImages = 16;
static const char* filenames[] =
{
"image/memorial0061.jpg",
"image/memorial0062.jpg",
"image/memorial0063.jpg",
"image/memorial0064.jpg",
"image/memorial0065.jpg",
"image/memorial0066.jpg",
"image/memorial0067.jpg",
"image/memorial0068.jpg",
"image/memorial0069.jpg",
"image/memorial0070.jpg",
"image/memorial0071.jpg",
"image/memorial0072.jpg",
"image/memorial0073.jpg",
"image/memorial0074.jpg",
"image/memorial0075.jpg",
"image/memorial0076.jpg"
};
//讀圖
for (int i = 0; i < numImages; i++)
{
Mat im = imread(filenames[i]);
images.push_back(im);
}
}
int main()
{
// Read images 讀取圖像
cout << "Reading images ... " << endl;
vector<Mat> images;
//是否圖像映射
bool needsAlignment = true;
// Read example images 讀取例子圖像
readImages(images);
//needsAlignment = false;
// Align input images
if (needsAlignment)
{
cout << "Aligning images ... " << endl;
Ptr<AlignMTB> alignMTB = createAlignMTB();
alignMTB->process(images, images);
}
else
{
cout << "Skipping alignment ... " << endl;
}
// Merge using Exposure Fusion 圖像融合
cout << "Merging using Exposure Fusion ... " << endl;
Mat exposureFusion;
Ptr<MergeMertens> mergeMertens = createMergeMertens();
mergeMertens->process(images, exposureFusion);
// Save output image 圖像保存
cout << "Saving output ... exposure-fusion.jpg" << endl;
imwrite("exposure-fusion.jpg", exposureFusion * 255);
return 0;
}Python:
import cv2
import numpy as np
import sys
def readImagesAndTimes():
filenames = [
"image/memorial0061.jpg",
"image/memorial0062.jpg",
"image/memorial0063.jpg",
"image/memorial0064.jpg",
"image/memorial0065.jpg",
"image/memorial0066.jpg",
"image/memorial0067.jpg",
"image/memorial0068.jpg",
"image/memorial0069.jpg",
"image/memorial0070.jpg",
"image/memorial0071.jpg",
"image/memorial0072.jpg",
"image/memorial0073.jpg",
"image/memorial0074.jpg",
"image/memorial0075.jpg",
"image/memorial0076.jpg"
]
images = []
for filename in filenames:
im = cv2.imread(filename)
images.append(im)
return images
if __name__ == '__main__':
# Read images
print("Reading images ... ")
if len(sys.argv) > 1:
# Read images from the command line
images = []
for filename in sys.argv[1:]:
im = cv2.imread(filename)
images.append(im)
needsAlignment = False
else :
# Read example images
images = readImagesAndTimes()
needsAlignment = False
# Align input images
if needsAlignment:
print("Aligning images ... ")
alignMTB = cv2.createAlignMTB()
alignMTB.process(images, images)
else :
print("Skipping alignment ... ")
# Merge using Exposure Fusion
print("Merging using Exposure Fusion ... ");
mergeMertens = cv2.createMergeMertens()
exposureFusion = mergeMertens.process(images)
# Save output image
print("Saving output ... exposure-fusion.jpg")
cv2.imwrite("exposure-fusion.jpg", exposureFusion * 255)本文第一張圖獲得的不同曝光的圖像,通過這種方法所得結果如下:

在輸入圖像中,我們可以獲得過度曝光圖像中光線昏暗區域和曝光不足圖像中明亮區域的細節。但是,在合并的輸出圖像中,像素在圖像的每個部分都具有明亮的細節。我們還可以在之前的帖子中看到我們用于HDR成像的圖像的這種效果。用于產生最終輸出的四個圖像顯示在左側,輸出圖像顯示在右側。結果如下圖所示:

正如您在本文中所看到的,Exposure Fusion允許我們在不明確計算HDR圖像的情況下實現類似于HDR + Tonemapping的效果。因此,我們不需要知道每張圖像的曝光時間,但我們能夠獲得非常合理的結果。那么,為什么要費心去做HDR呢?好吧,在很多情況下,Exposure Fusion產生的輸出可能不符合您的喜好。沒有旋鈕可以調整以使其變得不同或更好。另一方面,HDR圖像捕獲場景的原始亮度。如果您不喜歡色調映射的HDR圖像,請嘗試使用不同的色調映射算法。總之,Exposure Fusion代表了一種權衡。在速度和不太嚴格的要求下使得算法更加靈活(例如,不需要暴露時間)
以上就是“python怎么使用OpenCV進行曝光融合”這篇文章的所有內容,感謝各位的閱讀!相信大家閱讀完這篇文章都有很大的收獲,小編每天都會為大家更新不同的知識,如果還想學習更多的知識,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





