溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Redis熱點數據問題怎么解決”,在日常操作中,相信很多人在Redis熱點數據問題怎么解決問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Redis熱點數據問題怎么解決”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!

問題分析:上次聽群里大佬面試阿里 p7 就被問到這個問題,難度指數五顆星,對我等小白著實是加分項。
答:關于熱點數據問題我有話要說,這個問題我早在剛剛學習使用 Redis 時就從已經意識到了,所以在使用時會刻意避免,堅決不會給自己挖坑,熱點數據最大的問題會造成 Reids 集群負載不均衡(也就是數據傾斜)導致的故障,這些問題對于 Redis 集群都是致命打擊。
先說說造成 Reids 集群負載不均衡故障的主要原因:
高訪問量的 Key,也就是熱 key,根據過去的維護經驗一個 key 訪問的 QPS 超過 1000 就要高度關注了,比如熱門商品,熱門話題等。
大 Value,有些 key 訪問 QPS 雖然不高,但是由于 value 很大,造成網卡負載較大,網卡流量被打滿,單臺機器可能出現千兆 / 秒,IO 故障。
熱點 Key + 大 Value 同時存在,服務器殺手。
那么熱點 key 或大 Value 會造成哪些故障呢:
數據傾斜問題:大 Value 會導致集群不同節點數據分布不均勻,造成數據傾斜問題,大量讀寫比例非常高的請求都會落到同一個 redis server 上,該 redis 的負載就會嚴重升高,容易打掛。
QPS 傾斜:分片上的 QPS 不均。
大 Value 會導致 Redis 服務器緩沖區不足,造成 get 超時。
由于 Value 過大,導致機房網卡流量不足。
Redis 緩存失效導致數據庫層被擊穿的連鎖反應。
答:這個問題的解決辦法比較寬泛,要具體看不同業務場景,比如公司組織促銷活動,那參加促銷的商品肯定是有辦法提前統計的,這種場景就可以通過預估法。對于突發事件,不確定因素,Redis 會自己監控熱點數據。大概歸納下:
提前獲知法:
根據業務,人肉統計 or 系統統計可能會成為熱點的數據,如,促銷活動商品,熱門話題,節假日話題,紀念日活動等。
Redis 客戶端收集法:
調用端通過計數的方式統計 key 的請求次數,但是無法預知 key 的個數,代碼侵入性強。
public Connection sendCommand(final ProtocolCommand cmd, final byte[]... args) {
//從參數中獲取key
String key = analysis(args);
//計數
counterKey(key);
//ignore
}Redis 集群代理層統計:
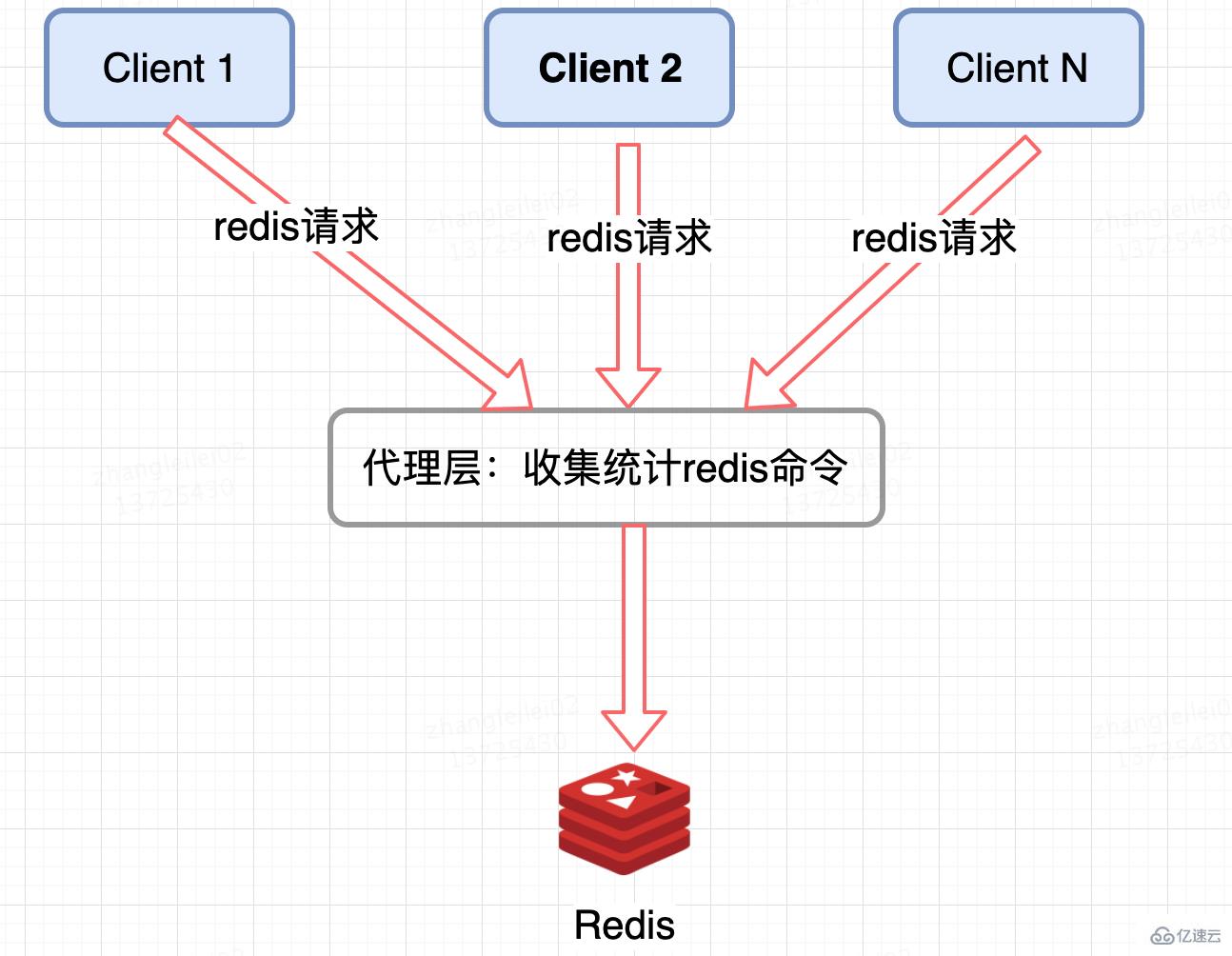
像 Twemproxy,codis 這些基于代理的 Redis 分布式架構,統一的入口,可以在 Proxy 層做收集上報,但是缺點很明顯,并非所有的 Redis 集群架構都有 proxy。
Redis 服務端收集:
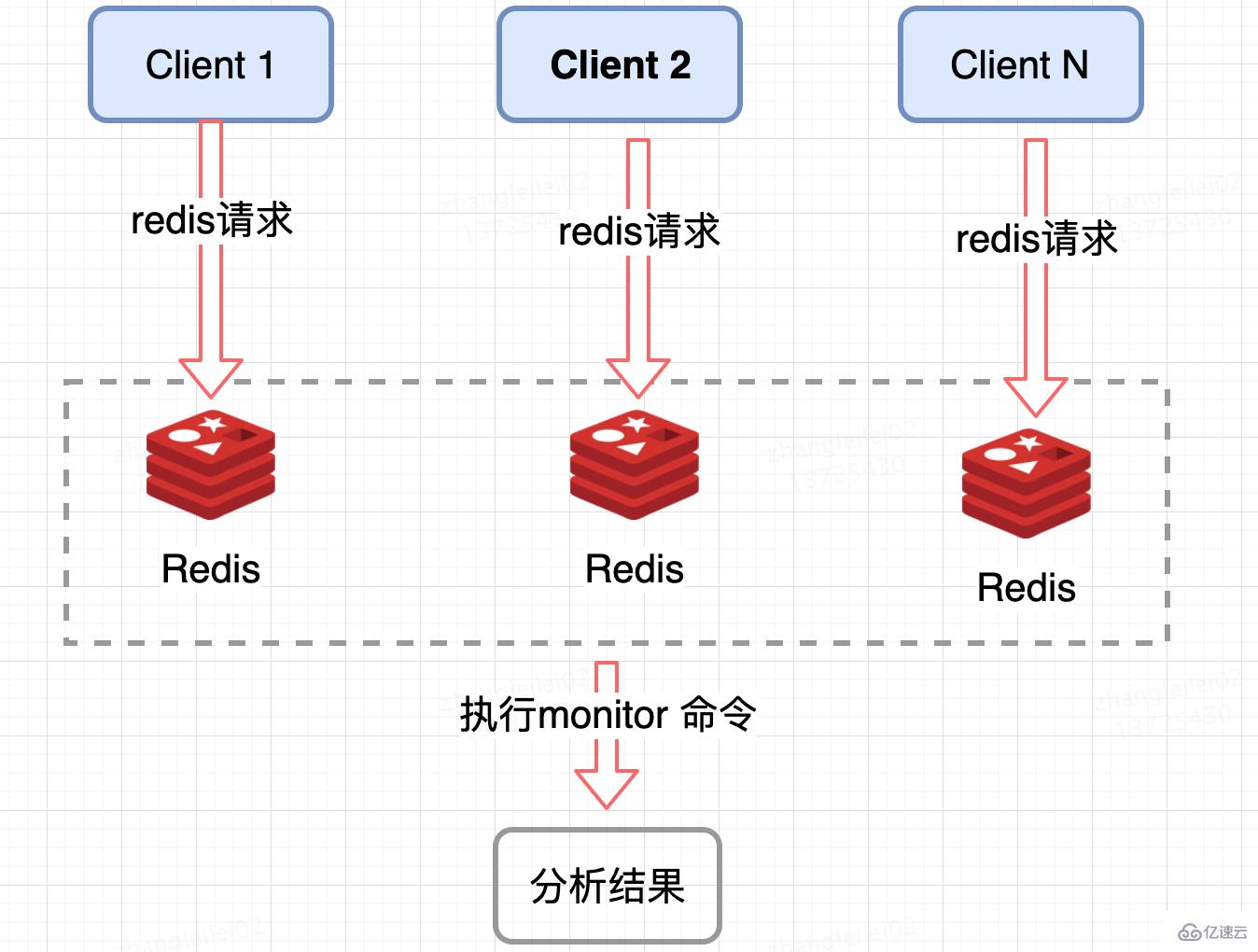
監控 Redis 單個分片的 QPS,發現 QPS 傾斜到一定程度的節點進行 monitor,獲取熱點 key, Redis 提供了 monitor 命令,可以統計出一段時間內的某 Redis 節點上的所有命令,分析熱點 key,在高并發條件下,會存在內存暴漲和 Redis 性能的隱患,所以此種方法適合在短時間內使用;同樣只能統計一個 Redis 節點的熱點 key,對于集群需要匯總統計,業務角度講稍微麻煩一點。
以上為說的這 4 個方法都是現在業界比較常用的,方法,我通過學習 Redis 源碼還有一個新的想法。第 5 種:修改 Redis 源碼。
修改 Redis 源代碼:(從讀源碼中想到的思路)
我發現 Redis4.0 為我們帶來了許多新特性,其中便包括基于 LFU 的熱點 key 發現機制,有了這個新特性,我們就可以在此基礎上實現熱點 key 的統計,這個只是我的個人思路。
面試官心理:小伙子還挺有想法,思路挺開闊,還打起了修改源碼的注意,我都沒這個野心。團隊里就需要這樣的人。
(發現問題,分析問題,解決問題,不等面試官發問,直接講述如何解決熱點數據問題,這才是核心內容)
答:關于如何治理熱點數據問題,解決這個問題主要從兩個方面考慮,第一是數據分片,讓壓力均攤到集群的多個分片上,防止單個機器打掛,第二是遷移隔離。
概括總結:
key 拆分:
如果當前 key 的類型是一個二級數據結構,例如哈希類型。如果該哈希元素個數較多,可以考慮將當前 hash 進行拆分,這樣該熱點 key 可以拆分為若干個新的 key 分布到不同 Redis 節點上,從而減輕壓力
遷移熱點 key:
以 Redis Cluster 為例,可以將熱點 key 所在的 slot 單獨遷移到一個新的 Redis 節點上,這樣這個熱點 key 即使 QPS 很高,也不會影響到整個集群的其他業務,還可以定制化開發,熱點 key 自動遷移到獨立節點上,這種方案也較多副本。
熱點 key 限流:
對于讀命令我們可以通過遷移熱點 key 然后添加從節點來解決,對于寫命令我們可以通過單獨針對這個熱點 key 來限流。
增加本地緩存:
對于數據一致性不是那么高的業務,可以將熱點 key 緩存到業務機器的本地緩存中,因為是業務端的本地內存中,省去了一次遠程的 IO 調用。但是當數據更新時,可能會造成業務和 Redis 數據不一致。
面試官:你回答得很好,考慮得很全面。
問題分析:相比熱點 key 大概念,大 Value 的概念比好好理解,由于 Redis 是單線程運行的,如果一次操作的 value 很大會對整個 redis 的響應時間造成負面影響,因為 Redis 是 Key - Value 結構數據庫,大 value 就是單個 value 占用內存較大,對 Redis 集群造成最直接的影響就是數據傾斜。
答:(想難倒我?我可是有備而來。)
我先說說多大的 Value 算大,根據公司基礎架構給出的經驗值可做以下劃分:
注:(經驗值不是標準,都是根據集群運維人員長期觀察線上 case 總結出來的)
大:string 類型 value > 10K,set、list、hash、zset 等集合數據類型中的元素個數 > 1000。
超大: string 類型 value > 100K,set、list、hash、zset 等集合數據類型中的元素個數 > 10000。
由于 Redis 是單線程運行的,如果一次操作的 value 很大會對整個 redis 的響應時間造成負面影響,所以,業務上能拆則拆,下面舉幾個典型的分拆方案:
一個較大的 key-value 拆分成幾個 key-value ,將操作壓力平攤到多個 redis 實例中,降低對單個 redis 的 IO 影響
將分拆后的幾個 key-value 存儲在一個 hash 中,每個 field 代表一個具體的屬性,使用 hget,hmget 來獲取部分的 value,使用 hset,hmset 來更新部分屬性。
hash、set、zset、list 中存儲過多的元素
類似于場景一中的第一個做法,可以將這些元素分拆。
以 hash 為例,原先的正常存取流程是:
hget(hashKey, field); hset(hashKey, field, value)
現在,固定一個桶的數量,比如 10000,每次存取的時候,先在本地計算 field 的 hash 值,模除 10000,確定該 field 落在哪個 key 上,核心思想就是將 value 打散,每次只 get 你需要的。
newHashKey = hashKey + (hash(field) % 10000); hset(newHashKey, field, value); hget(newHashKey, field)
到此,關于“Redis熱點數據問題怎么解決”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





