溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文小編為大家詳細介紹“kafka中的消息分區分配算法怎么用”,內容詳細,步驟清晰,細節處理妥當,希望這篇“kafka中的消息分區分配算法怎么用”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。
kafka有分區機制,一個主題topic在創建的時候,會設置分區。如果只有一個分區,那所有的消費者都訂閱的是這一個分區消息;如果有多個分區的話,那消費者之間又是如何分配的呢?
分配算法
Kafka默認采?RangeAssignor的分配算法。
RangeAssignor策略的原理是按照消費者總數和分區總數進?整除運算來獲得?個跨度,然 后將分區按照跨度進?平均分配,以保證分區盡可能均勻地分配給所有的消費者。對于每?個 Topic,RangeAssignor策略會將消費組內所有訂閱這個Topic的消費者按照名稱的字典序排序,然 后為每個消費者劃分固定的分區范圍,如果不夠平均分配,那么字典序靠前的消費者會被多分配 ?個分區。
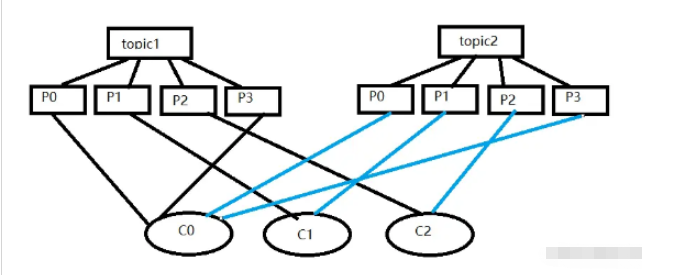
這種分配?式明顯的?個問題是隨著消費者訂閱的Topic的數量的增加,不均衡的問題會越來 越嚴重,?如上圖中4個分區3個消費者的場景,C0會多分配?個分區。如果此時再訂閱?個分區 數為4的Topic,那么C0?會?C1、C2多分配?個分區,這樣C0總共就?C1、C2多分配兩個分區 了,?且隨著Topic的增加,這個情況會越來越嚴重。
public class RangeAssignor extends AbstractPartitionAssignor {
....
@Override
public Map> assign(Map partitionsPerTopic, Map subscriptions) {
// 1. 獲取每個topic被多少個consumer訂閱了
Map<String,List<String>> consumersPerTopic = consumersPerTopic(subscriptions);
// 2. 存儲最終的分配?案
Map<String,List<String>> assignment = new HashMap<>();
for (String memberId : subscriptions.keySet())
assignment.put(memberId, new ArrayList());
for (Map.Entry> topicEntry : consumersPerTopic.entrySet()) {
String topic = topicEntry.getKey();
List consumersForTopic = topicEntry.getValue();
// 3. 每個topic的partition數量
Integer numPartitionsForTopic = partitionsPerTopic.get(topic);
if (numPartitionsForTopic == null)
continue;
Collections.sort(consumersForTopic);
// 4. 表示平均每個consumer會分配到多少個partition
int numPartitionsPerConsumer = numPartitionsForTopic / consumersForTopic.size();
// 5. 平均分配后還剩下多少個partition未被分配
int consumersWithExtraPartition = numPartitionsForTopic % consumersForTopic.size();
List partitions = AbstractPartitionAssignor.partitions(topic, numPartitionsForTopic);
// 6. 這?是關鍵點,分配原則是將未能被平均分配的partition分配到前 consumersWithExtraPartition個consumer
for (int i = 0, n = consumersForTopic.size(); i < n; i++) {
int start = numPartitionsPerConsumer * i + Math.min(i, consumersWithExtraPartition);
int length = numPartitionsPerConsumer + (i + 1 > consumersWithExtraPartition ? 0 : 1); assignment.get(consumersForTopic.get(i)).addAll(partitions.subList(start, start + length));
}
}
return assignment;
}
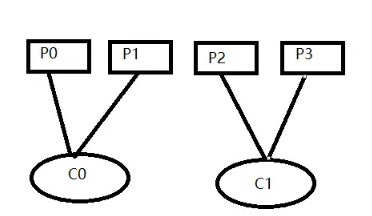
}可以完全平均分配
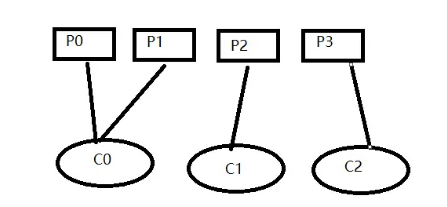
無法完全平均分配,排序靠前分的更多
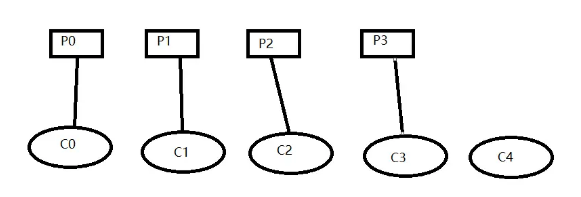
消費者數量大于分區數量,排名靠前先分得,排名靠后未分得分區
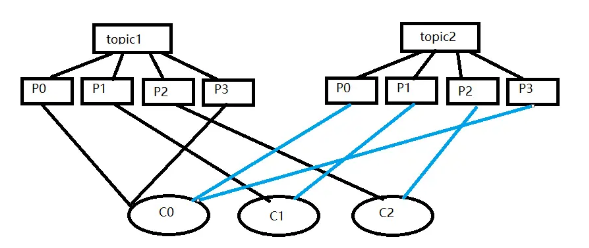
RoundRobinAssignor的分配策略是將消費組內訂閱的所有Topic的分區及所有消費者進?排序后盡 量均衡的分配(RangeAssignor是針對單個Topic的分區進?排序分配的)。如果消費組內,消費者訂閱 的Topic列表是相同的(每個消費者都訂閱了相同的Topic),那么分配結果是盡量均衡的(消費者之間 分配到的分區數的差值不會超過1)。
package org.apache.kafka.clients.consumer;
public class RoundRobinAssignor extends AbstractPartitionAssignor {
@Override
public Map> assign(Map partitionsPerTopic, Map subscriptions) {
<Map> assignment = new HashMap<>();
for (String memberId : subscriptions.keySet()) assignment.put(memberId, new ArrayList()); // 1. 環狀鏈表,存儲所有的consumer,?次迭代完之后?會回到原點
CircularIterator assigner = new CircularIterator<> (Utils.sorted(subscriptions.keySet())); // 2. 獲取所有訂閱的topic的partition總數 for (TopicPartition partition : allPartitionsSorted(partitionsPerTopic, subscriptions)) {
final String topic = partition.topic();
while (!subscriptions.get(assigner.peek()).topics().contains(topic))
assigner.next();
assignment.get(assigner.next()).add(partition);
}
return assignment;
}
.... }無法完全平均分配,排序靠前分的更多
盡管RoundRobinAssignor已經在RangeAssignor上做了?些優化來更均衡的分配分區,但是在?些情況下依舊會產?嚴重的分配偏差,從字?意義上看,Sticky是“粘性的”,可以理解為分配結果是帶“粘性的”——每?次分配變更相對 上?次分配做最少的變動(上?次的結果是有粘性的) 其?標有兩點:
分區的分配盡量的均衡
每?次重分配的結果盡量與上?次分配結果保持?致
讀到這里,這篇“kafka中的消息分區分配算法怎么用”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





