溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“MySQL臨時表可以重名的原因是什么”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“MySQL臨時表可以重名的原因是什么”這篇文章吧。
今天我們就從這個問題說起:臨時表有哪些特征,適合哪些場景?
這里,我需要先幫你厘清一個容易誤解的問題:有的人可能會認為,臨時表就是內存表。但是,這兩個概念可是完全不同的。
內存表,指的是使用Memory引擎的表,建表語法是create table …engine=memory。**這種表的數據都保存在內存里,系統重啟的時候會被清空,但是表結構還在。**除了這兩個特性看上去比較“奇怪”外,從其他的特征上看,它就是一個正常的表。
臨時表,可以使用各種引擎類型。如果是使用InnoDB引擎或者MyISAM引擎的臨時表,寫數據的時候是寫到磁盤上的。當然,臨時表也可以使用Memory引擎。
弄清楚了內存表和臨時表的區別以后,我們再來看看臨時表有哪些特征。
為了便于理解,我們來看下下面這個操作序列:

可以看到,臨時表在使用上有以下幾個特點:
建表語法是create temporary table …。
一個臨時表只能被創建它的session訪問,對其他線程不可見。所以,圖中session A創建的臨時表t,對于session B就是不可見的。
臨時表可以與普通表同名。
session A內有同名的臨時表和普通表的時候,showcreate語句,以及增刪改查語句訪問的是臨時表。
showtables命令不顯示臨時表。
由于臨時表只能被創建它的session訪問,所以在這個session結束的時候,會自動刪除臨時表。
也正是由于這個特性,臨時表就特別適合上篇文章中join優化這種場景。為什么呢? 原因主要包括以下兩個方面:
不同session的臨時表是可以重名的,如果有多個session同時執行join優化,不需要擔心表名重復導致建表失敗的問題。
不需要擔心數據刪除問題。如果使用普通表,在流程執行過程中客戶端發生了異常斷開,或者數據庫發生異常重啟,還需要專門來清理中間過程中生成的數據表。而臨時表由于會自動回收,所以不需要這個額外的操作。
由于不用擔心線程之間的重名沖突,臨時表經常會被用在復雜查詢的優化過程中。其中,分庫分表系統的跨庫查詢就是一個典型的使用場景。
一般分庫分表的場景,就是要把一個邏輯上的大表分散到不同的數據庫實例上。比如。將一個大表ht,按照字段f,拆分成1024個分表,然后分布到32個數據庫實例上。如下圖所示:
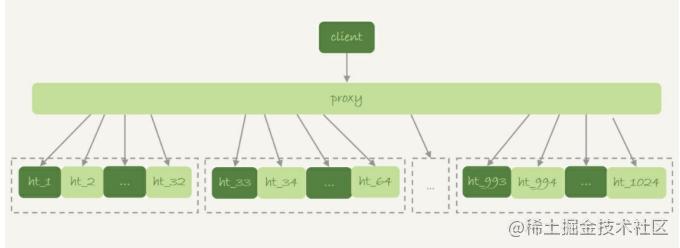
一般情況下,這種分庫分表系統都有一個中間層proxy。不過,也有一些方案會讓客戶端直接連接數據庫,也就是沒有proxy這一層。
在這個架構中,分區key的選擇是以“減少跨庫和跨表查詢”為依據的。如果大部分的語句都會包含f的等值條件,那么就要用f做分區鍵。這樣,在proxy這一層解析完SQL語句以后,就能確定將這條語句路由到哪個分表做查詢。
比如下面這條語句:
select v from ht where f=N;
這時,我們就可以通過分表規則(比如,N%1024)來確認需要的數據被放在了哪個分表上。這種語句只需要訪問一個分表,是分庫分表方案最歡迎的語句形式了。
但是,如果這個表上還有另外一個索引k,并且查詢語句是這樣的:
select v from ht where k >= M order by t_modified desc limit 100;
這時候,由于查詢條件里面沒有用到分區字段f,只能到所有的分區中去查找滿足條件的所有行,然后統一做order by的操作。這種情況下,有兩種比較常用的思路。
第一種思路是,在proxy層的進程代碼中實現排序。 這種方式的優勢是處理速度快,拿到分庫的數據以后,直接在內存中參與計算。不過,這個方案的缺點也比較明顯:
需要的開發工作量比較大。我們舉例的這條語句還算是比較簡單的,如果涉及到復雜的操作,比如group by,甚至join這樣的操作,對中間層的開發能力要求比較高;
對proxy端的壓力比較大,尤其是很容易出現內存不夠用和CPU瓶頸的問題。
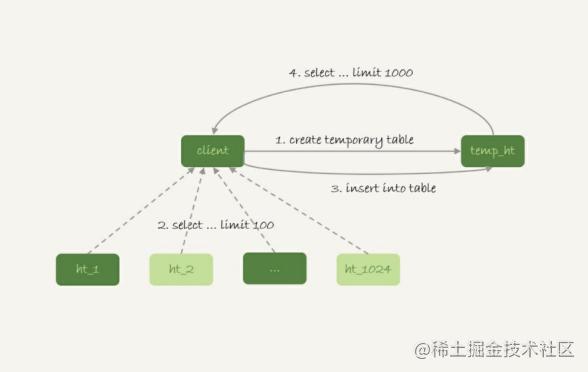
另一種思路就是,把各個分庫拿到的數據,匯總到一個MySQL實例的一個表中,然后在這個匯總實例上做邏輯操作。
比如上面這條語句,執行流程可以類似這樣:
在匯總庫上創建一個臨時表temp_ht,表里包含三個字段v、k、t_modified;
在各個分庫上執行select v,k,t_modified from ht_x where k >= M order by t_modified desc limit 100;
把分庫執行的結果插入到temp_ht表中;
執行select v from temp_ht order by t_modified desc limit 100;
得到結果。 這個過程對應的流程圖如下所示:
在實踐中,我們往往會發現每個分庫的計算量都不飽和,所以會直接把臨時表temp_ht放到32個分庫中的某一個上。
你可能會問,不同線程可以創建同名的臨時表,這是怎么做到的呢?
我們在執行
create temporary table temp_t(id int primary key)engine=innodb;
這個語句的時候,MySQL要給這個InnoDB表創建一個frm文件保存表結構定義,還要有地方保存表數據。
這個frm文件放在臨時文件目錄下,文件名的后綴是.frm,前綴是“#sql{進程id}_ {線程id}_ 序列號”。
從文件名的前綴規則,我們可以看到,其實創建一個叫作t1的InnoDB臨時表,MySQL在存儲上認為我們創建的表名跟普通表t1是不同的,因此同一個庫下面已經有普通表t1的情況下,還是可以再創建一個臨時表t1的。
先來舉一個例子。

這個進程的進程號是1234,session A的線程id是4,session B的線程id是5。所以你看到了,session A和session B創建的臨時表,在磁盤上的文件不會重名。
MySQL維護數據表,除了物理上要有文件外,內存里面也有一套機制區別不同的表,每個表都對應一個table_def_key。
一個普通表的table_def_key的值是由“庫名+表名”得到的,所以如果你要在同一個庫下創建兩個同名的普通表,創建第二個表的過程中就會發現table_def_key已經存在了。
而對于臨時表,table_def_key在“庫名+表名”基礎上,又加入了“server_id+thread_id”。
也就是說,session A和session B創建的兩個臨時表t1,它們的table_def_key不同,磁盤文件名也不同,因此可以并存。
在實現上,每個線程都維護了自己的臨時表鏈表。這樣每次session內操作表的時候,先遍歷鏈表,檢查是否有這個名字的臨時表,如果有就優先操作臨時表,如果沒有再操作普通表;在session結束的時候,對鏈表里的每個臨時表,執行 “DROPTEMPORARY TABLE +表名”操作。
這時候你會發現,binlog中也記錄了DROPTEMPORARY TABLE這條命令。你一定會覺得奇怪,臨時表只在線程內自己可以訪問,為什么需要寫到binlog里面?這,就需要說到主備復制了。
既然寫binlog,就意味著備庫需要。 你可以設想一下,在主庫上執行下面這個語句序列:
create table t_normal(id int primary key, c int)engine=innodb;/*Q1*/ create temporary table temp_t like t_normal;/*Q2*/ insert into temp_t values(1,1);/*Q3*/ insert into t_normal select * from temp_t;/*Q4*/
如果關于臨時表的操作都不記錄,那么在備庫就只有create table t_normal表和insert intot_normal select * fromtemp_t這兩個語句的binlog日志,備庫在執行到insert into t_normal的時候,就會報錯“表temp_t不存在”。
你可能會說,如果把binlog設置為row格式就好了吧?因為binlog是row格式時,在記錄insert intot_normal的binlog時,記錄的是這個操作的數據,即:write_rowevent里面記錄的邏輯是“插入一行數據(1,1)”。
確實是這樣。如果當前的binlog_format=row,那么跟臨時表有關的語句,就不會記錄到binlog里。也就是說,只在binlog_format=statment/mixed的時候,binlog中才會記錄臨時表的操作。
這種情況下,創建臨時表的語句會傳到備庫執行,因此備庫的同步線程就會創建這個臨時表。主庫在線程退出的時候,會自動刪除臨時表,但是備庫同步線程是持續在運行的。所以,這時候我們就需要在主庫上再寫一個DROPTEMPORARY TABLE傳給備庫執行。
現在,我給你舉個例子,下面的序列中實例S是M的備庫。

主庫M上的兩個session創建了同名的臨時表t1,這兩個create temporary table t1 語句都會被傳到備庫S上。
但是,備庫的應用日志線程是共用的,也就是說要在應用線程里面先后執行這個create 語句兩次。(即使開了多線程復制,也可能被分配到從庫的同一個worker中執行)。那么,這會不會導致同步線程報錯?
顯然是不會的,否則臨時表就是一個bug了。也就是說,備庫線程在執行的時候,要把這兩個t1表當做兩個不同的臨時表來處理。這,又是怎么實現的呢? MySQL在記錄binlog的時候,會把主庫執行這個語句的線程id寫到binlog中。這樣,在備庫的應用線程就能夠知道執行每個語句的主庫線程id,并利用這個線程id來構造臨時表的table_def_key:
session A的臨時表t1,在備庫的table_def_key就是:庫名+t1+“M的serverid”+“session A的thread_id”;
session B的臨時表t1,在備庫的table_def_key就是 :庫名+t1+“M的serverid”+“session B的thread_id”。
由于table_def_key不同,所以這兩個表在備庫的應用線程里面是不會沖突的。
以上是“MySQL臨時表可以重名的原因是什么”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





