溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“怎么查看正則表達式的AST”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“怎么查看正則表達式的AST”這篇文章吧。
字符串的處理基本都會用正則表達式,用它來做字符串的匹配、提取、替換等很方便。
但是正則表達式的學習還是有些難度的,比如貪婪匹配、非貪婪匹配、捕獲子組、非捕獲子組等概念,不止初學者難理解,有很多工作幾年的人都不理解。
那正則表達式怎么學比較好?怎么快速掌握正則表達式呢?
正則表達式的匹配原理是把模式串 parse 成 AST,然后通過這個 AST 去匹配目標字符串。
模式串中的各種信息在 parse 之后都會保存在 AST 里面。AST 是 abstract syntax tree,抽象語法樹的意思,顧名思義,是按照語法結構組織的一棵樹,那么從 AST 的結構上自然可以輕易的知道正則表達式支持的語法。
怎么查看正則表達式的 AST 呢?
可以通過 astexplorer.net 這個網站來可視化的查看:
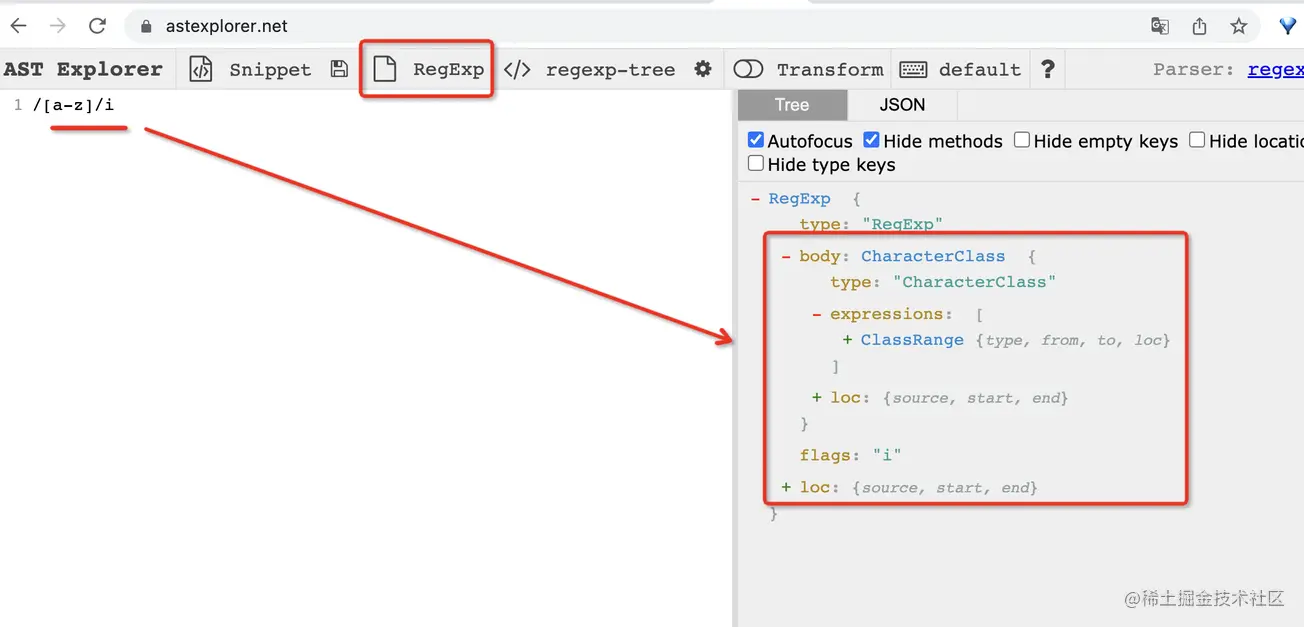
切換 parse 的語言為 RegExp,就可以做正則表達式的 AST 的可視化。
就像前面所說,AST 是按照語法來組織的一棵樹,那么從它的結構上自然能容易地理清各種語法。
那么我們就從 AST 的角度來學習下各種語法吧:
先從簡單的開始,/abc/ 這樣一個正則就可以匹配 'abc' 的字符串,它的 AST 是這樣的:
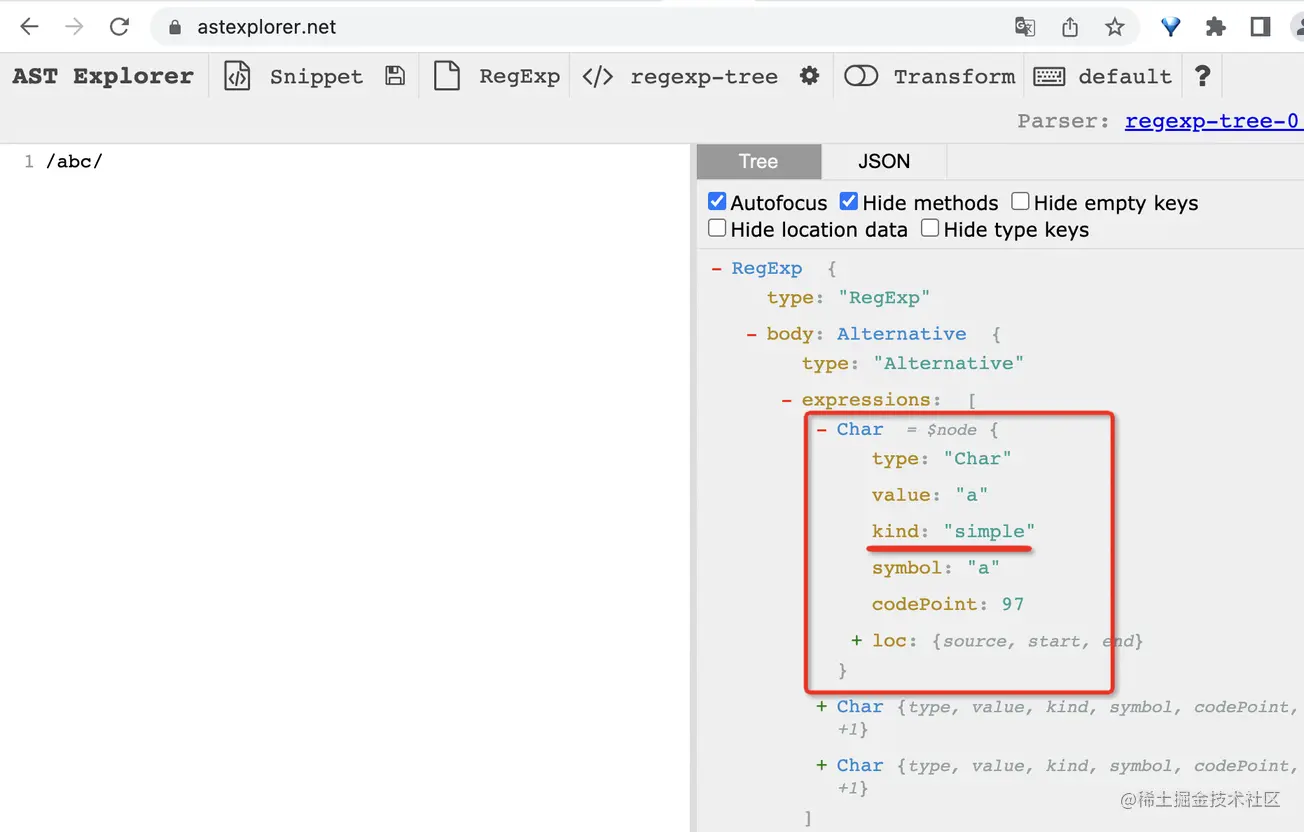
3 個 Char,值分別是 a、b、c,類型是 simple。那之后的匹配就是遍歷 AST,分別匹配這三個字符了。
我們用 exec 的 api 測試了下:

第 0 個元素是匹配的字符串,index 是匹配字符串的開始下標。input 是輸入的字符串。
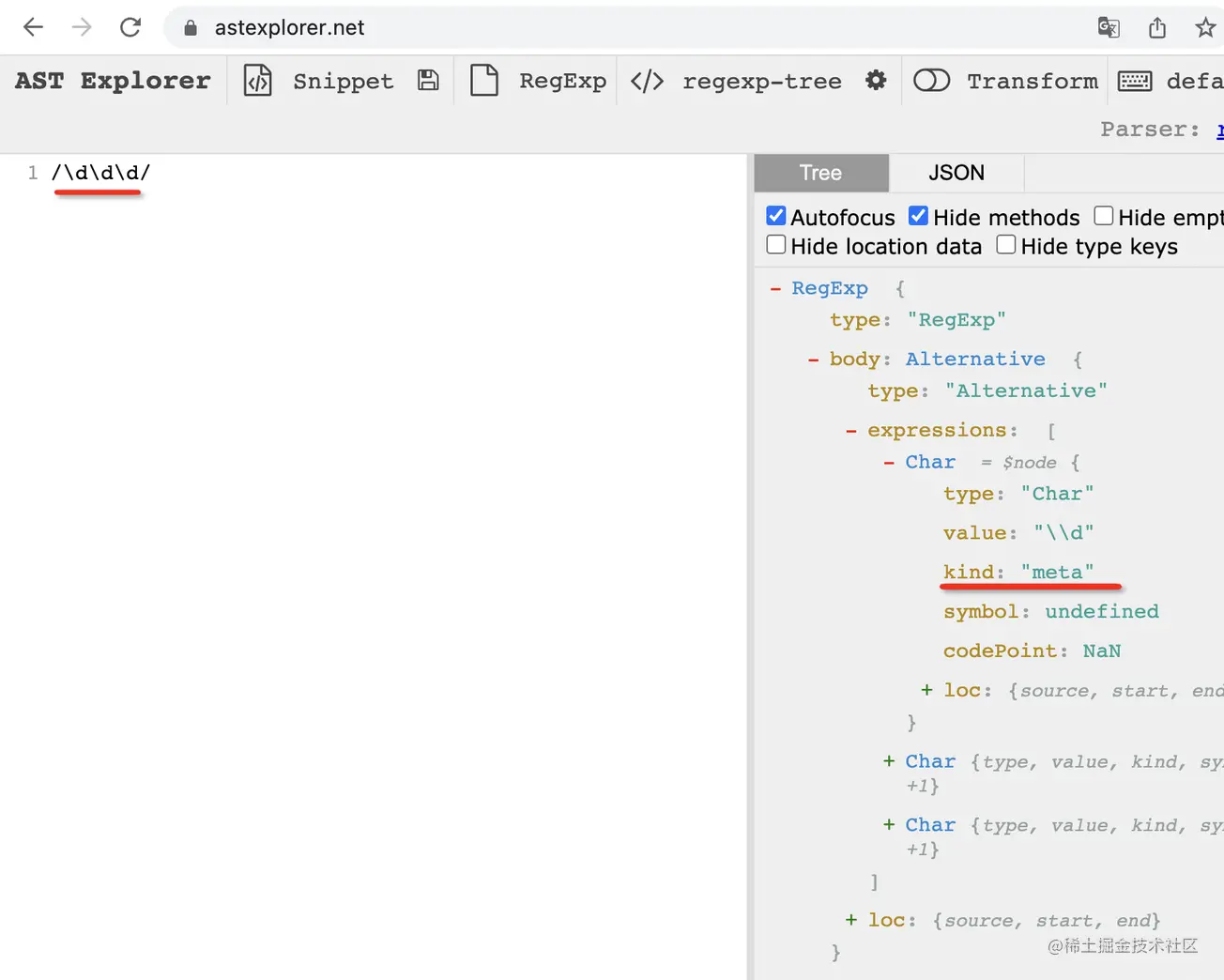
再來試下特殊的字符:
/\d\d\d/ 是匹配三個數字的意思,\d 是正則支持的有特殊含義的元字符(meta char)。
通過 AST 我們也可以看出來,它們雖然也是 Char,但類型確是 meta:
可以通過 \d 的元字符來匹配任意數字:

哪些是 meta char 哪些是 simple char,通過 AST 來看一目了然。
正則支持通過 [] 的方式來指定一組字符,也就是說匹配其中任意一種字符都行。
通過 AST 我們也可以看出來,它被包裹了一層 CharacterClass,就是字符類的意思,也就是匹配它包含的任意一種字符都行。
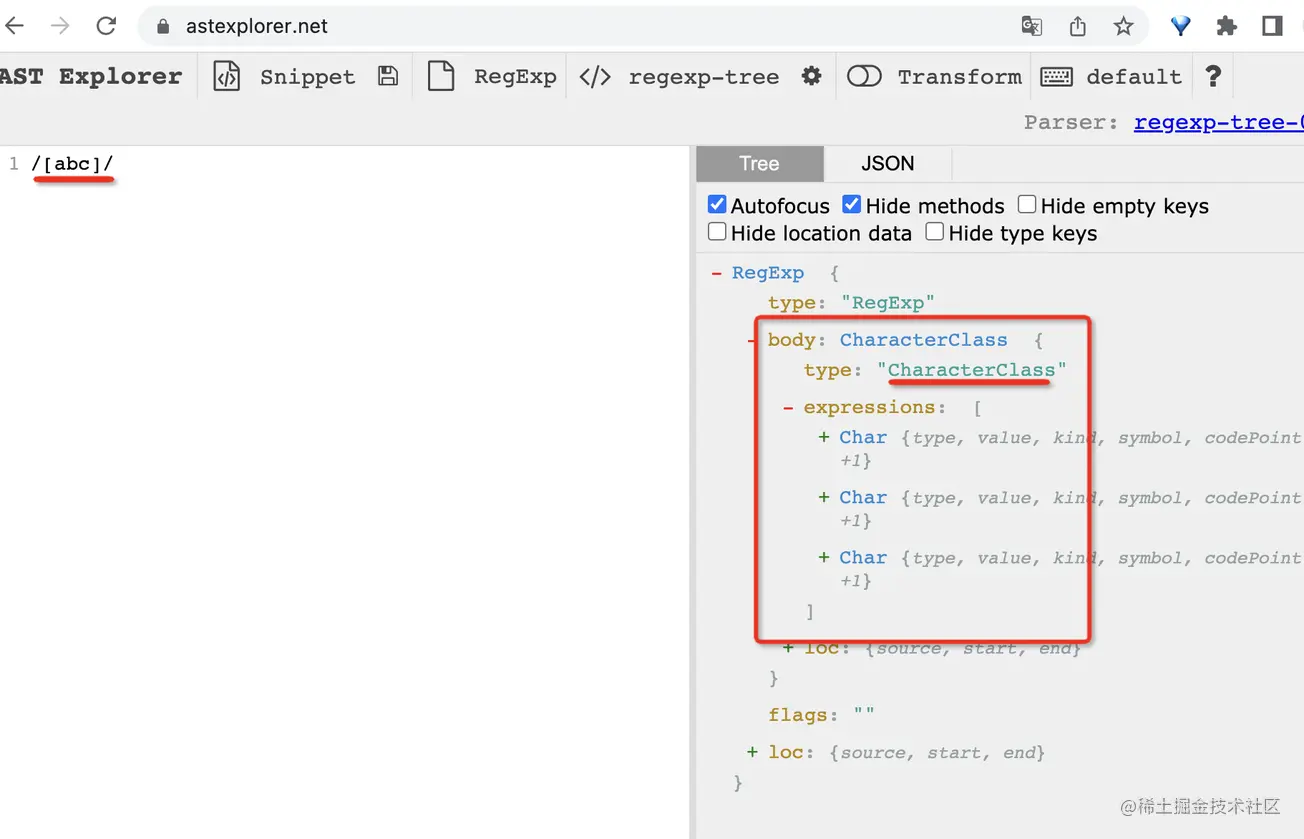
測試下也確實是這樣:

正則表達式支持指定某個字符重復多少次,用 {from,to} 的形式,
比如 /b{1,3}/ 表示字符 b 重復 1 到 3 次,/[abc]{1,3}/ 表示這個 a/b/c 字符類重復 1 到 3 次。
通過 AST 可以看出來,這種語法叫做 Repetition(重復):
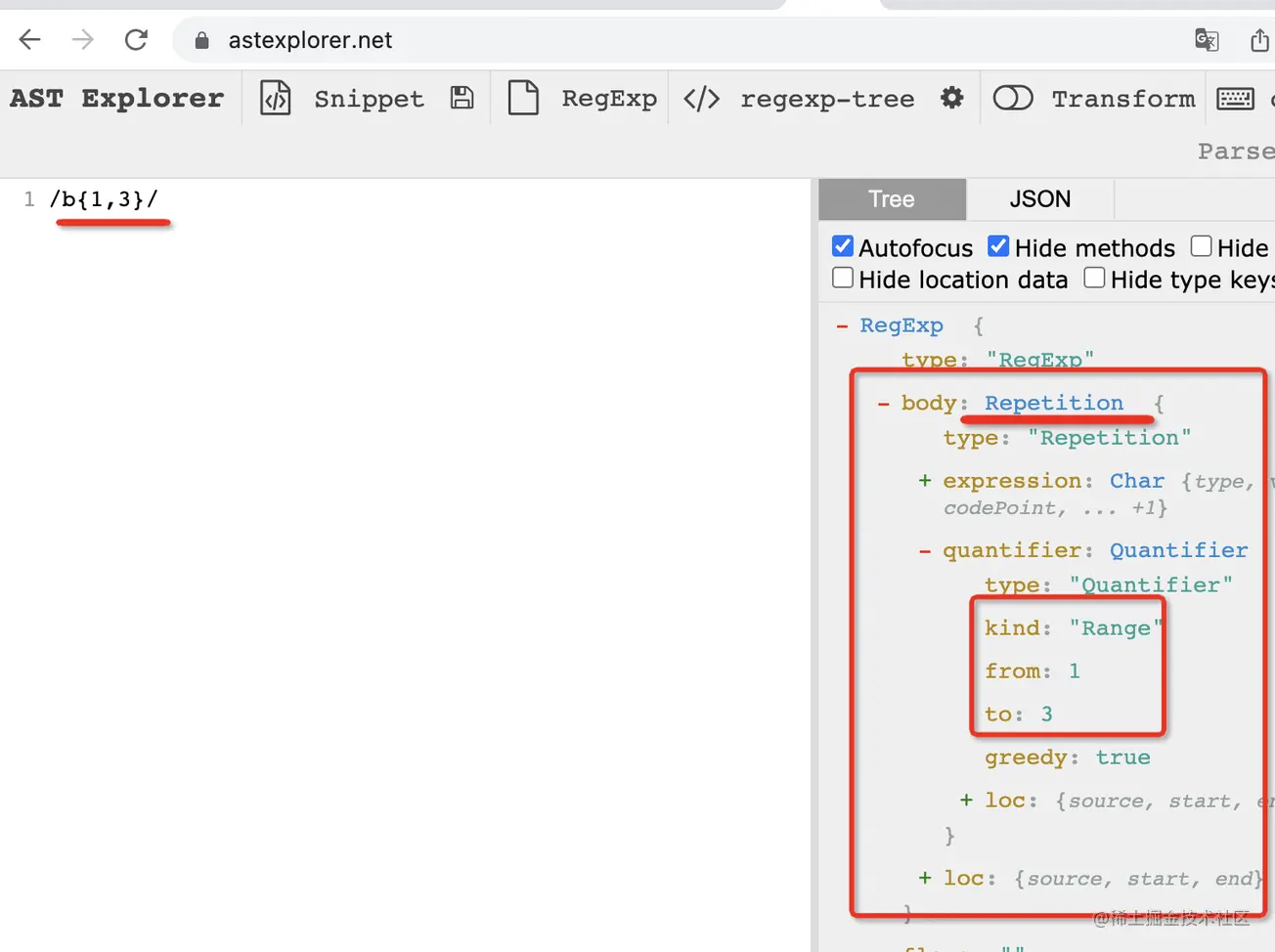
他有個 quantifier 的屬性表示量詞,這里的類型是 range,從 1 到 3。
正則也支持一些量詞的簡寫,比如 + 表示 1 到無數次、* 表示 0 到無數次、? 表示 0 或 1 次。
分別是不同類型的量詞:
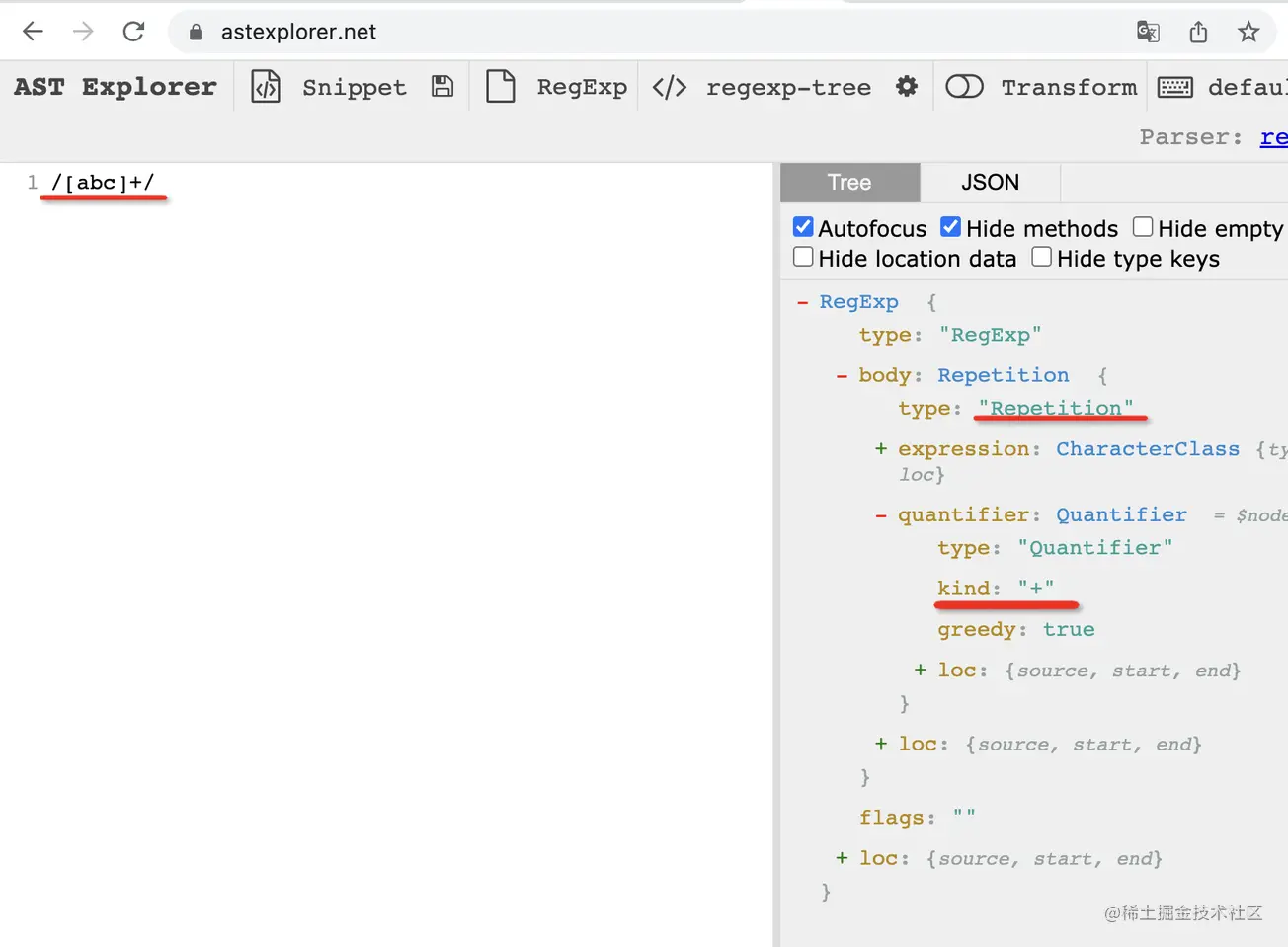
有同學可能會問,這里的 greedy 屬性是啥意思呢?

greedy 是貪婪的意思,這個屬性就表示這個 Repetition 是貪婪匹配還是非貪婪匹配。
如果在量詞后加個 ?,你就會發現 greedy 變成 false 了,也就是切換到了非貪婪匹配:
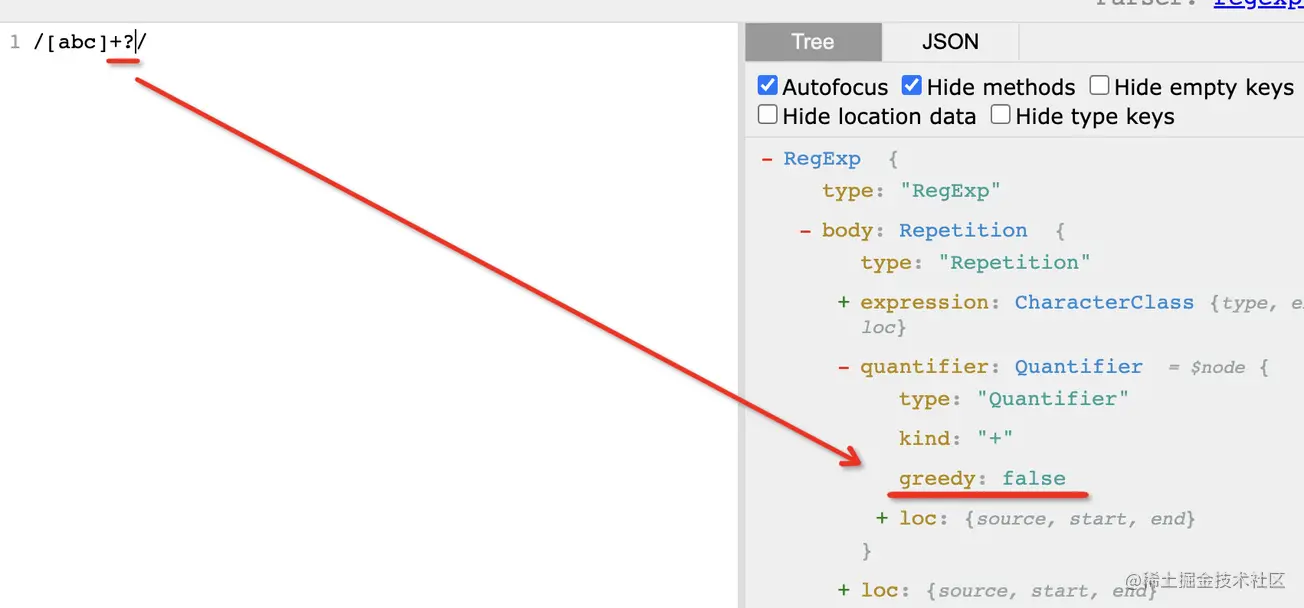
那貪婪和非貪婪是指啥呢?
我們看個例子就知道了。
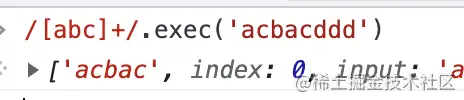
默認 Repetition 的匹配是貪婪的,只要滿足條件就一直匹配下去,所以這里 acbac 都能匹配到。
量詞后加個 ? 就切換到了非貪婪,就只會匹配第一個了:
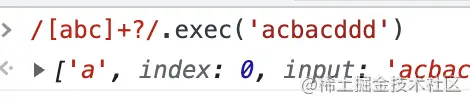
這就是貪婪匹配和非貪婪匹配,通過 AST 我們能夠清楚的知道貪婪和非貪婪是針對重復語法來說的,默認是貪婪匹配,在量詞后加個 ? 就可以切換到非貪婪。
正則表達式支持通過()把匹配到的一部分字符串放到子組里返回。
通過 AST 看一下:
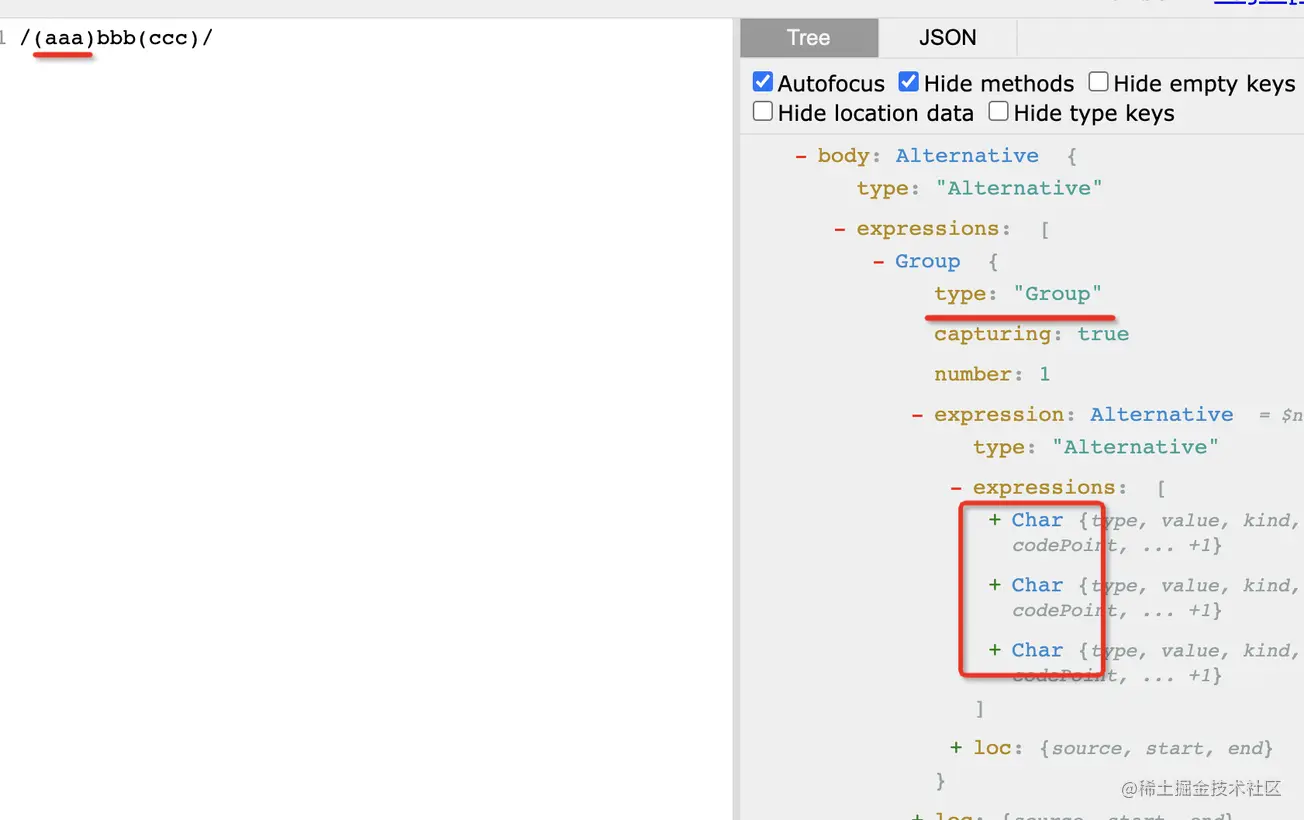
對應的 AST 就叫做 Group。
而且你會發現它有個 capturing 的屬性,默認是 true:

這是啥意思呢?
這就是子組捕獲的語法。
如果不想捕獲子組,可以這樣寫 (?:aaa)

看,capturing 變為 false 了。
那捕獲和非捕獲有什么區別呢?
我們試一下:
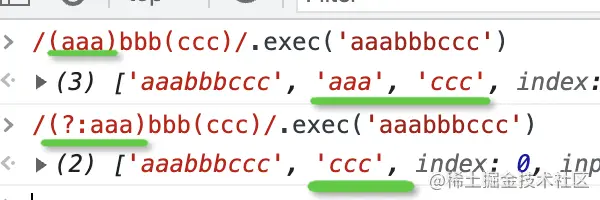
哦,原來 Group 的 capturing 屬性代表的是是否提取的意思啊。
我們通過 AST 可以看出來,捕獲是針對子組來說的,默認是捕獲,也就是提取子組的內容,可以通過 ?: 切換到非捕獲,就不會提取子組的內容了。
我們對用 AST 來了解正則語法已經輕車熟路了,那來看點難的:
正則表達式支持通過 (?=xxx) 的語法來表示先行斷言,用來判斷某個字符串是否前面是某個字符串。
通過 AST 可以看到這種語法叫做 Assertion,并且類型為 lookahead,也就是往前看,只匹配前面的意思:
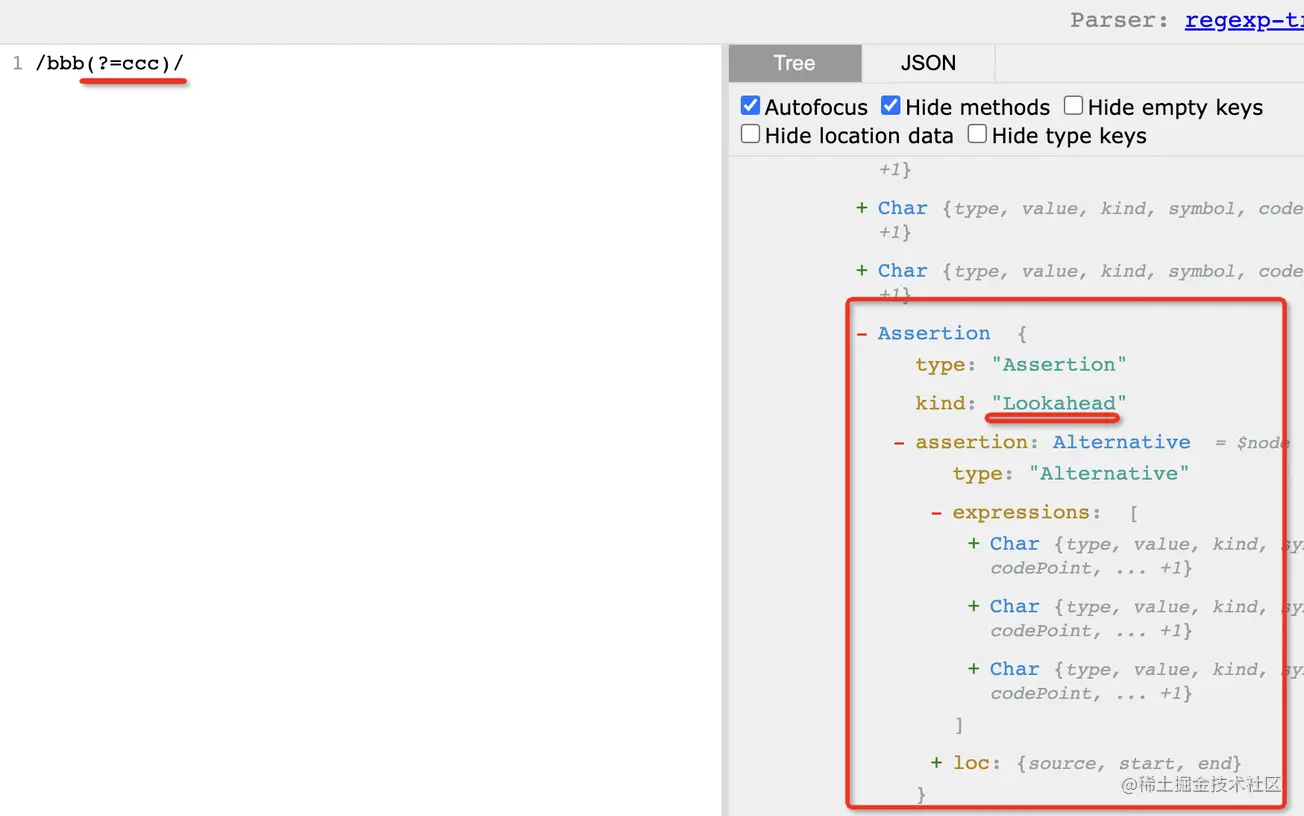
這是啥意思呢?為啥要這么寫?和 /bbb(ccc)/ 還有 /bbb(?:ccc)/有啥區別呢?
我們試一下:
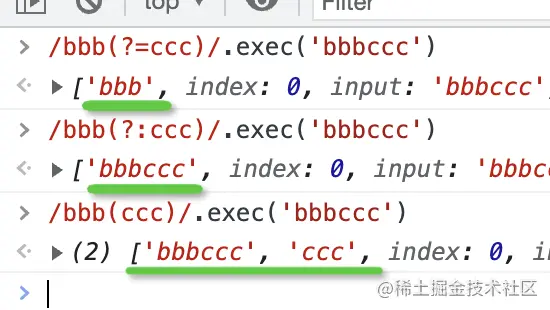
從結果可以看出來:
/bbb(ccc)/ 匹配了 ccc 的子組并且提取出來了這個子組,因為默認子組是捕獲的。
/bbb(?:ccc)/ 匹配了 ccc 的子組但沒有提取出來,因為我們通過 ?: 設置了子組不捕獲。
/bbb(?=ccc)/ 匹配了 ccc 的子組也沒有提取出子組,說明也是非捕獲的。它和 ?: 的區別是 ccc 沒有出現在匹配結果里。
這就是先行斷言(lookahead assertion)的性質:先行斷言代表某段字符串前面是某段字符串,對應的子組是非捕獲的,而且斷言的字符串不會出現在匹配結果中。
如果后面不是跟著那段字符串就不匹配:
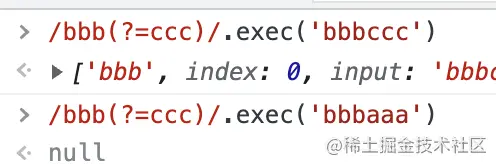
把 ?= 改成 ?! 之后意思就變了,通過 AST 看一下:
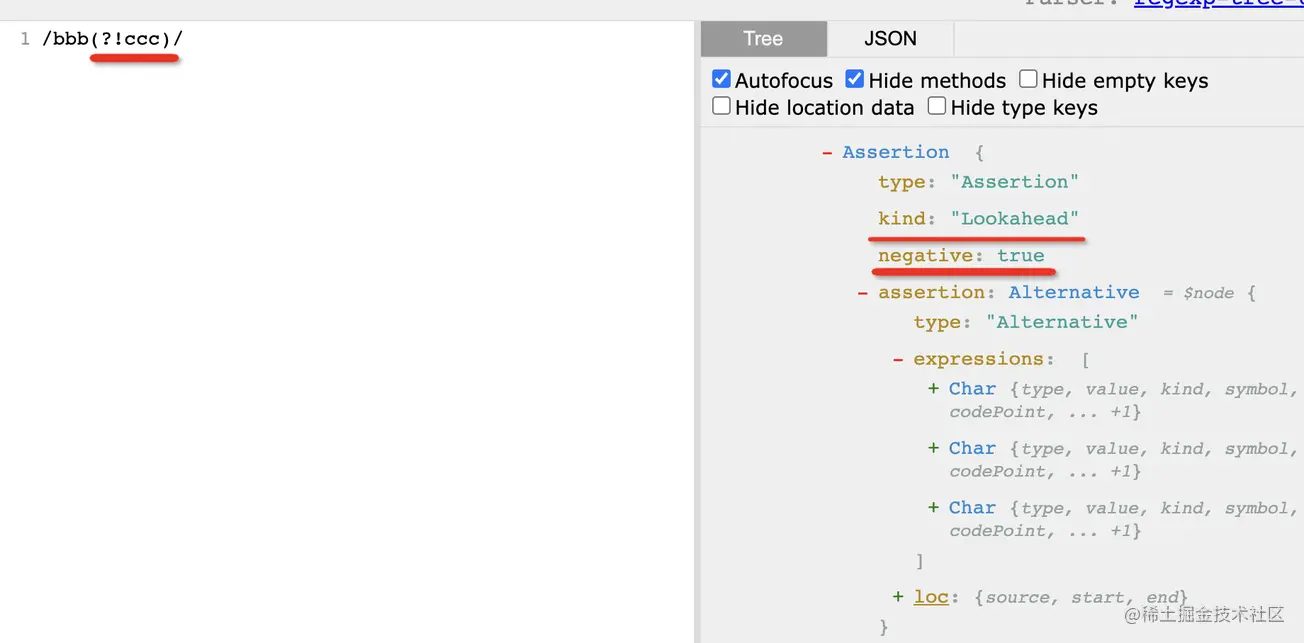
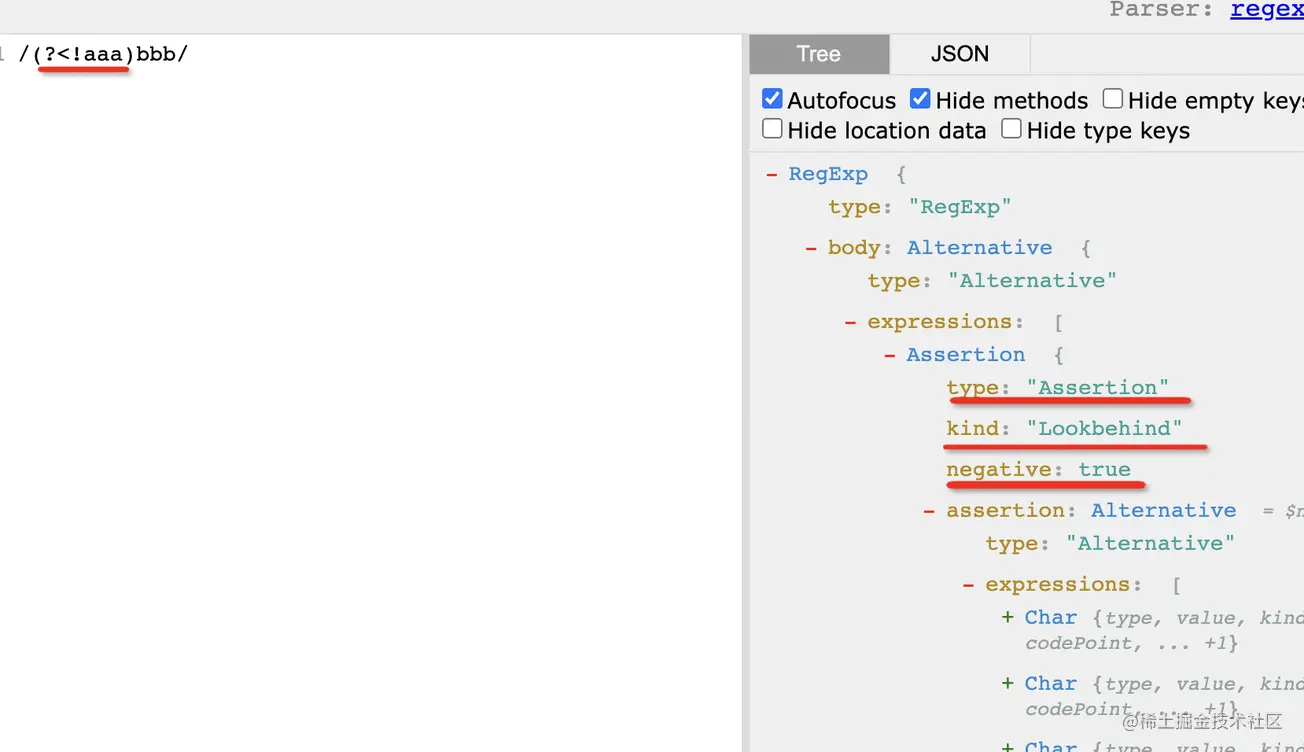
雖然還是先行斷言 lookahead assertion,但是多了個 negative 為 true 的屬性。
這個意思很明顯,本來是前面是某段字符串,否定之后就是前面不是某段字符串。
那匹配結果正好就反過來了:
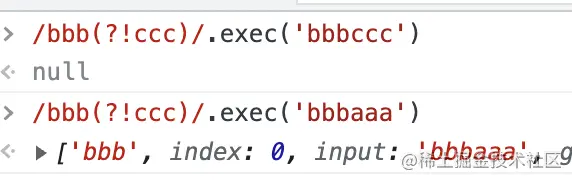
現在前面不是某段字符串的話才匹配了,這就是否定先行斷言。
有先行斷言自然也有后行斷言,也就是后面是某段字符串才匹配。

同理,也可以否定:
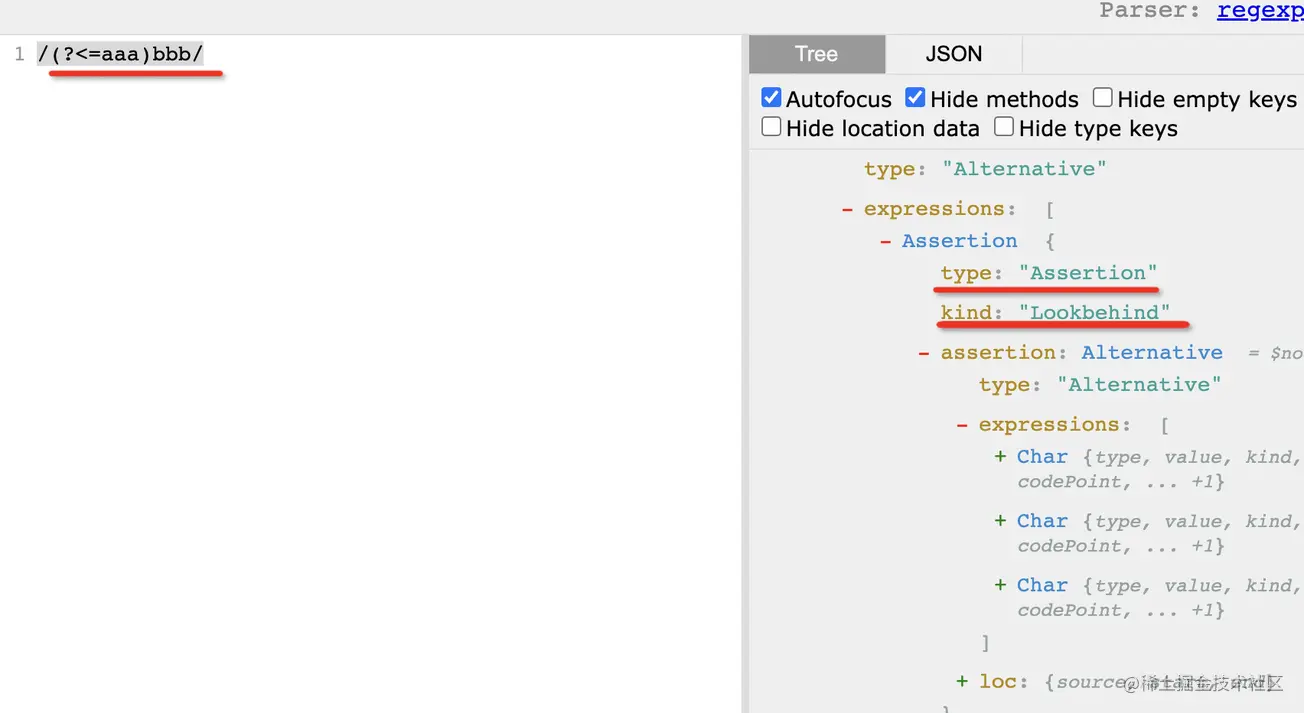
(?<=aaa)對應的 AST 很容易想到,就是 lookbehind assertion:
(?<!aaa)對應的 AST 就是加個 negative 屬性:
以上是“怎么查看正則表達式的AST”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





