溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天小編給大家分享一下Python錯位鍵盤、單詞長度、字母重排的方法的相關知識點,內容詳細,邏輯清晰,相信大部分人都還太了解這方面的知識,所以分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后有所收獲,下面我們一起來了解一下吧。
在我們打字的時候,往往會因為手誤將A敲成S,將S敲成D
現在有一位程序員由于手誤輸入了一行字符串 請憑借你聰明的大腦將其還原 (鍵盤上的字符順序:"`1234567890-=QWERTYUIOP[]\ASDFGHJKL;'ZXCVBNM,./")
樣例輸入:O S, GOMR YPFSU/
樣例輸出:I AM FINE TODAY
這類的問題有事后想到的就是進行字符的替換,但是一個鍵盤上字符那么多逐個替換的話非常的費時費力于是我們可以進行一個下標數組的編排,用于記錄字符在字符串中的位置,而為了不必要的轉換我們不妨將下標數組開辟到255個這樣每一種字符的ASCII值就可以直接作為下標數組的下標拿到他在原來字符串的索引。
然后根據輸入可以知道,輸入的有空格,給定的鍵盤內沒有空格,所以需要進行分詞處理。在Python中分詞有極為簡便的方法,在C語言中可以開辟一個字符型指針數組,用于存儲每一段單詞,處理方式與單詞的平均長度無異。可以先往下看看。分完詞之后可以迭字符型指針數組。然后按序列輸出。輸出的時候先拿字符做下標取原字符串中的索引,然后再拿索引-1去原字符中取字符。注意輸出時候的格式。
老規矩先上運行結果:

代碼如下:
import sys
s=sys.stdin.readline().strip().split()
indexarr=[0]*255
# 將所有數據存放進一個數組,將鍵盤上相鄰的兩個字母在數組中以索引的形式相連
mystr="`1234567890-=QWERTYUIOP[]\\ASDFGHJKL;'ZXCVBNM,./"
# 將每一位字母的索引存儲起來。供以后遍歷輸入的數據使用
for i in range(len(mystr)):
indexarr[ord(mystr[i])]=i
flag=True
#遍歷輸入的n段字符串
for line in s:
if flag:
flag=False
for i in line:
print(mystr[indexarr[ord(i)]-1],end="")
else:
print(" ",end="")
for i in line:
print(mystr[indexarr[ord(i)]-1],end="")使用c語言做的話先進行空格統計,如果空格后面不為空格就進行單詞數加1
如果空格后面依舊是空格向下遍歷,如果一個位置不為空格就進行字母數加1
最終要將單詞數額外加1,因為首尾單詞循環的時候只統計進去了一個。
輸入若干個單詞,單詞只包含字母,每個單詞由一個或多個空格組成
輸出單詞的平均長度
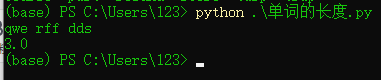
樣例輸入:qwe qwe qwe
樣例輸出:3.0
對字符串進行分詞,然后求每一個字串的長度,再將長度和除以單詞的個數
老規矩先上運行結果:
代碼如下:
import sys num=0 n=0 # 這里使用strip()去除輸入的末尾換行符 # 使用split()進行字符串分段最后得到的是一個列表形式 mystr=sys.stdin.readline().strip().split() for i in mystr: num+=len(i) n+=1 print(num/n)
輸入一個字典(*****結尾),然后再輸入若干單詞。每輸入一個單詞w,你都需要 在字典中找出所有可以用w的字母重排后得到的單詞,并按照字典序從小到大的順序在一 行中輸出(如果不存在,輸出:0。輸入單詞之間用空格或空行隔開,且所有輸入單詞都由 不超過6個小寫字母組成。注意,字典中的單詞不一定按字典序排列。
樣例輸入:
第一行 tarp given score refund only trap work earn course pepper part
第二行 resco nfudre aptr sett oresuc
樣例輸出:
course part refund score tarp trap
給出一個字典,所以我們在進行查找的時候可以先將字典進行處理,然后依照字典的標準進行查詞
這里我們可以先對字典進行排序得到首字母有序的字典,然后對字典中每一個元素進行排序。 對要查詢的子串進行排序,然后遍歷有序字典進行查找,找到直接輸出(也就是說將標準的字典按 一定的方式處理,然后將所要查的詞經過相同的轉換后與字典進行比對)
老規矩先上運行結果:

代碼如下:
import sys
# 元字典序字符串
mydic=list(sys.stdin.readline().strip().split())
mydic=sorted(mydic)
words=sys.stdin.readline().strip().split()
# 排序后的字符串
newdic=[]
newwords=[]
for i in mydic:
# 字符串不可以直接排序,先轉換成字典,然后進行排序
newdic.append("".join(sorted(i)))
for i in words:
newwords.append("".join(sorted(i)))
flag=False
i=0
while i<len(newdic):
if newdic[i] in newwords:
if not flag:
print(mydic[i],end="")
flag=True
else:
print(" ",mydic[i],end="")
i+=1
if not flag:
print(0)有一篇文章,在撰稿的時候,沒有按照指定格式編排,現在需要將包含'' 的標點符號轉換成為 只有中文雙引號的文章“”
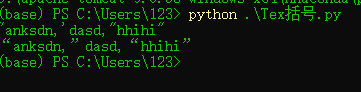
樣例輸入:"anksdn,'dasd,“hhihi”
樣例輸出:“anksdn,”dasd,“hhihi”
這里與前面提到的燈光模擬非常的類似,只需要記性標記位的整頓就好
可以設計一個標記flag,當flag為True時遇見"進行左引號“的輸出然后
立即將標記變為與其相反的值當flag為false時遇見"立即進行右引號輸出。
然后將flag標記為True
老規矩先上運行結果:
代碼如下:
import sys
s=sys.stdin.readline().strip()
flag=True
for i in s:
if i=="'" or i=="\"":
if flag:
print("“",end="")
else:
print("”",end="")
flag=not flag
continue
print(i,end="")以上就是“Python錯位鍵盤、單詞長度、字母重排的方法”這篇文章的所有內容,感謝各位的閱讀!相信大家閱讀完這篇文章都有很大的收獲,小編每天都會為大家更新不同的知識,如果還想學習更多的知識,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





