溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關MySQL8.0中的窗口函數是什么的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
在以前的MySQL版本中是沒有窗口函數的,直到MySQL8.0才引入了窗口函數。窗口函數是對查詢中的每一條記錄執行一個計算,并且這個計算結果是用與該條記錄相關的多條記錄得到的。
窗口函數與聚合函數很像,他們都是在一組記錄而不是整張表上執行的。但是,一個聚合函數在一組記錄執行后只返回一條結果而窗口函卻會對改分組內的每行記錄都返回一個結果。
MySQL8.0中定義的窗口函數主要有以下幾種:
| 函數名 | 參數 | 描述 |
| cume_dist() | 否 | 累計分布值。即分組值小于等于當前值的行數與分組總行數的比值。取值范圍為(0,1]。 |
| dense_rank() | 否 | 不間斷的組內排序。使用這個函數時,可以出現1,1,2,2這種形式的分組。 |
| first_value() | 是;first_value(expr) | 返回分組內截止當前行的第一個值。 |
| lag() | 是;lag(expr,[N,[default]]) | 從當前行開始往前取第N行,如果N缺失默認為1。若沒有沒有,則默認返回default。default默認值為NULL |
| last_value() | 是;last_value(expr) | 返回分組內截止當前行的最后一個值。 |
| lead() | 是;lead(expr,[N,[default]]) | 從當前行開始往后取第N行。函數功能與lag()相反,其余與lag()相同。 |
| nth_value() | 是;nth_value(expr,N) | 返回分組內截止當前行的第N行。first_value\last_value\nth_value函數功能相似,只是返回分組內截止當前行的不同行號的數據。 |
| ntile() | 是;ntile(N) | 返回當前行在分組內的分桶號。在計算時要先將改分組內的所有數據劃分成N個桶,之后返回每個記錄所在的分桶號。返回范圍從1到N |
| percent_rank() | 否 | 累計百分比。該函數的計算結果為:小于該條記錄值的所有記錄的行數/該分組的總行數-1. 所以改記錄的返回值為[0,1] |
| rank() | 否 | 間斷的組內排序。其排序結果可能出現如下結果:1,1,3,4,4,6 |
| row_number() | 否 | 當前行在其分組內的序號。不管其排序結果中是否出現重復值,其排序結果都為:1,2,3,4,5 |
注:‘參數’列說明該函數是否可以加參數。“否”說明該函數的括號內不可以加參數。expr即可以代表字段,也可以代表在字段上的計算,比如sum(col)等。以下相同。
over子句可以指定如何將記錄劃分分區以供窗口函數處理。如果over()為空,則是將整個查詢記錄作為一個分組。如果over子句不為空,則其可以指定查詢記錄劃分分組的方式以及記錄在分組內部的排序方式。除此之外,over子句也可以和聚合函數一起用。如果聚合函數后出現over子句,那么這些聚合函數也就變成了窗口函數。如果沒有over子句,則他們仍然是聚合函數。可以使用over子句的聚合函數主要有以下幾種:
avg()、bit_and()、bit_or()、bit_xor()、count()、max()、min()、stddev_pop()、stddev()、std()、stddev_samp()、sum()、var_pop()、variance()、var_samp()
而對于前一部分中介紹的窗口函數來說,over()子句是強制必須要有的。
over子句中常見的語法形式為:
over_clause:
{OVER (window_spec) | OVER window_name}
其中:
window_spec:
[window_name] [partition_clause] [order_clause] [frame_clause]
window_name: 是指在查詢語句定義的window子句。如果遇到group by、having子句order by子句,那么window子句要放到having子句和order by子句中間。其語法如下:
WINDOW window_name AS (window_spec)
[, window_name AS (window_spec)] ...
而
window_spec:
[window_name] [partition_clause] [order_clause] [frame_clause]
從語法結構可以看出來window子句其實只是把放在over()括號中的內容單獨抽出來。
partition_clause:即parittion by expr子句。用來指定記錄分組方式。語法中的expr不僅可以是字段本身,也可以是計算表達式。比如,記錄中有個timestramp類型的字段 ts,在MySQL中,partition by ts 和partition by hour(ts)都是有效的。
order_clause: 即 order by expr desc|asc,expr desc|asc。 用來指定分組內的排序方式。
frame_clause: 用來指定當前分組中的子集劃分方式。frame可以在依據當前行的位置在每個分組內移動。使用frame來計算流水流水總和(從分區開始到當前行)及滾動平均(rolling averages)。
其語法結構如下:
frame_clause:
frame_units frame_extent
frame_units:
{ROWS | RANGE}
frame_extent:
{frame_start | frame_between}
frame_between:
BETWEEN frame_start AND frame_end
frame_start, frame_end:
{ CURRENT ROW
| UNBOUNDED PRECEDING
| UNBOUNDED FOLLOWING
|expr PRECEDING
| expr FOLLOWING
}其中:
frame_units用來指示當前行和frame的關系
ROWS: 用來定義frame的開始行和結束行(偏移量依據的是位置);RANGE: 定義frame的區間。(偏移量的基準為當前行的值)
frame_entent用來指示frame的開始行和結束行。一種是通過指定start和end(frame_start,frame_end。frame_end可以不指定,沒有明確給出的話當前行默認為結束行),另一種使用between(frame_between)。frame_between的語法很簡單。下面來看frame_start和frame_end。
current row:和rows一起用時,邊界就是當前行。和range一起用時,邊界是當前行的對等點(個人理解,這里所說的對等點應為與當前行的值相等的所有記錄)。
unbounded precceding:使用它時,每個分區的第一行即為邊界。
unbounded following:使用它時,每個分區的第一行即為邊界。
expr preceding\expr following: 可以由expr個性化的設置向上(preceding)向下(following)的偏移量。
表結構如下:
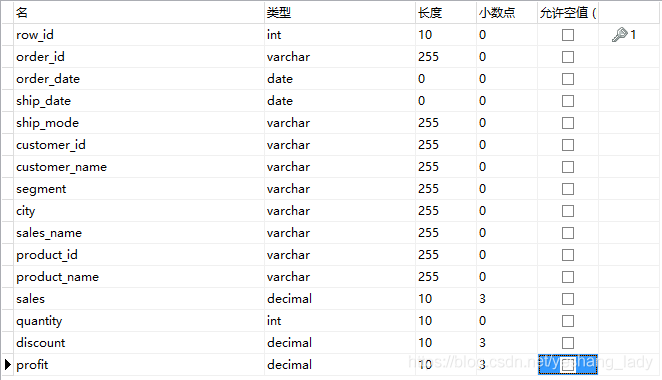
select order_date,sum(quantity) as quantity, rank()over(ORDER BY sum(quantity) desc) as rank_result, dense_rank()over(ORDER BY sum(quantity) desc) as dense_result, row_number()over(ORDER BY sum(quantity) desc) as row_result from spm_order group by order_date -- 限定一部分數據,沒有實際意義,能展示出這三個函數的區別就可以了 having quantity>=98 order by quantity desc
運行結果如下:
從上面結果看出:
rank()函數一旦遇到重復值,序號會斷。比如2個7之后下個出現的序號是9。
dense_rank()函數中即使有重復值,但是序號是連續的。2個7之后下個出現的序號是8。
row_number()不會出現相同的序號。
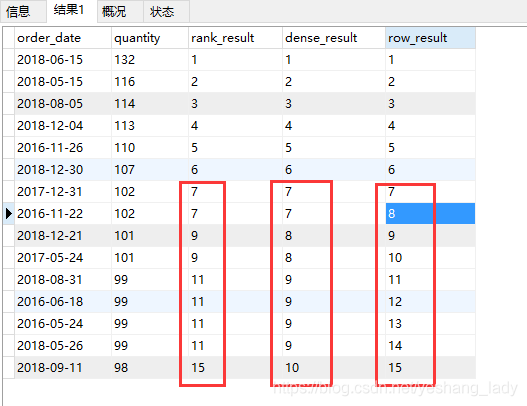
select order_date,num, cume_dist()over(order by num asc) as cume_result, percent_rank()over(order by num asc) as percent_result from (select order_date,count(1) as num from spm_order group by order_date having num>=27)a order by num asc
代碼運行結果如下
分析如下:
cume_dist():首先總的記錄有10條。當num=27時,num小于等于27的值共有5個,所以其cume_dist()值為0.5;當num=28時,小于等于28的值共有7個,所以cume_dist()值為0.7; 以此類推。
percent_rank().當num=27時,num小于27的記錄數為0,所以percent_rank()為0;當num=28時,num<28的記錄數共有5個,所以percent_rank()的值為5/9; 而當num=29時,其cume_dist()=7/9;以此類推,直到最大值36對應的值為1.
這兩個函數的作用有點像計算中位數。
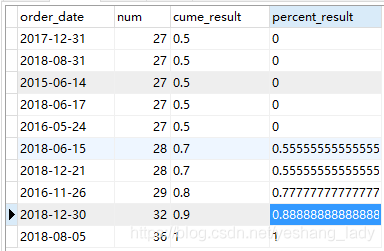
select sales_name,year_date,num,
first_value(num)over(PARTITION by sales_name order by year_date asc) as first_result,
last_value(num)over(PARTITION by sales_name order by year_date asc) as last_result,
nth_value(num,2)over(PARTITION by sales_name order by year_date asc) as nth_result
from (select sales_name,year(order_date)as year_date,count(1) as num
from spm_order
where sales_name in ('楊健','楚杰','洪光')
group by year(order_date),sales_name
order by sales_name asc,year_date asc)a代碼運行結果如下(要注意,這三個函數計算結果都是截止當前行)
select sales_name,year_date,num,
ntile(8)over(order by num asc) as n_bin
from (select sales_name,year(order_date)as year_date,count(1) as num
from spm_order
where sales_name in ('楊健','楚杰','洪光')
group by year(order_date),sales_name
order by sales_name asc,year_date asc)a代碼運行結果如下:
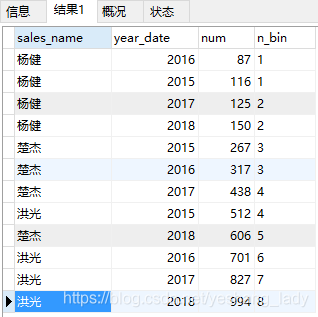
從結果上進行分析:
首先,分桶號從1到N,都會出現;
其次,關于每個桶應該有多少條記錄。可以假設有N個桶,m個球(球數為總記錄數),標號從1到N,依次往1號桶到N號桶里投球,每次只投1個球。循環往復,直到m個球全都投入到N個桶中。最后每個桶里有多少球,現在每個桶里就有多少條記錄。
select sales_name,year_date,num,
lag(num,2)over(PARTITION by sales_name order by year_date asc) as lag_result,
lead(num,2)over(PARTITION BY sales_name order by year_date asc) as lead_result
from (select sales_name,year(order_date)as year_date,count(1) as num
from spm_order
where sales_name in ('楊健','楚杰','洪光')
group by year(order_date),sales_name
order by sales_name asc,year_date asc)a代碼運行結果如下:
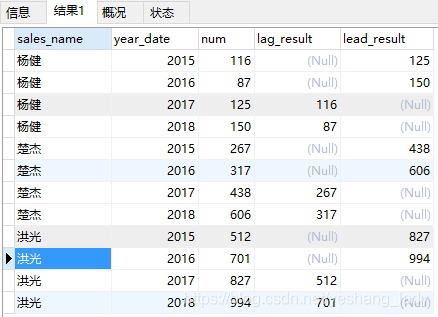
注意,lag()和lead()函數中出現的字段可以與over()子句中order by中出現的字段不一致。在代碼lag(num,2)中2代表的想要取數的那一行相比當前行的偏移量(lead中也類似)。
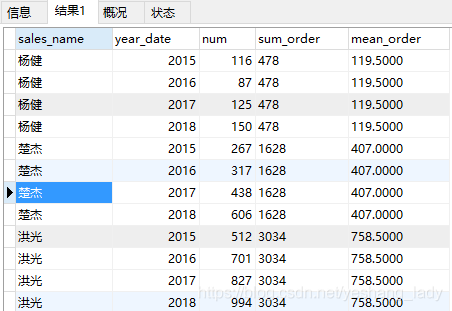
select sales_name,year_date,num,
sum(num)over(PARTITION by sales_name) as sum_order,
avg(num)over(PARTITION by sales_name) as mean_order
from (select sales_name,year(order_date)as year_date,count(1) as num
from spm_order
where sales_name in ('楊健','楚杰','洪光')
group by year(order_date),sales_name
order by sales_name asc,year_date asc)a代碼運行結果如下:
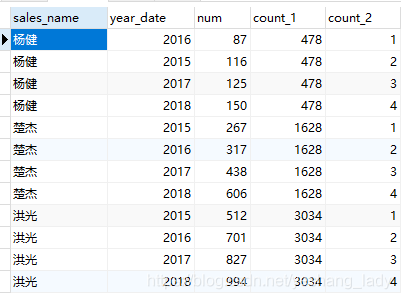
select sales_name,year_date,num,
sum(num)over(partition by sales_name) as count_1,
count(num)over(partition by sales_name order by num) as count_2
from (select sales_name,year(order_date)as year_date,count(1) as num
from spm_order
where sales_name in ('楊健','楚杰','洪光')
group by year(order_date),sales_name
order by sales_name asc,year_date asc)a代碼運行結果如下:
當frame_clause不存在的時候,默認的frame與order by子句是否存在有關:
如果有order by子句,則默認的frame是從當前分區第一行到當前行。即在此種情況下,默認的frame為 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
如果沒有order by子句,則默認的frame是指該分區。如果此時也沒有partition by子句,則相當于全部數據。
select sales_name,year(order_date) as year_1,count(1) as num,
sum(count(1)) over w as sales_order,
sum(count(1)) over (w_1) as year_order,
rank()over(w order by count(1) desc) as rank_order
-- 三種寫法都是符合語法規范的
from spm_order
where sales_name in ('楊健','楚杰','洪光')
group by sales_name,year(order_date)
window w as (PARTITION by sales_name),
w_1 as (PARTITION by year(order_date))
order by sales_order代碼運行結果如下:
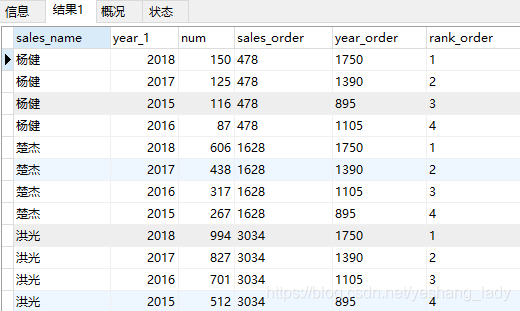
rows和range是不能單獨使用的,但是因為實在不理解這兩個用法上的區別,所以就進行了單獨的驗證。
select sales_name,month_1,rn_1,num,
sum(num)over(order by month_1 rows between 2 preceding and 1 preceding) as month_row,
sum(num)over(order by month_1 range between 2 preceding and 1 preceding) as month_range,
sum(num)over(order by rn_1 range between 2 preceding and 1 preceding) as rn_range
from (SELECT sales_name,month(order_date) as month_1,count(1) as num,
-- 由于rank()over()返回的是unsigned,當相減結果為負時(between子句會用到減法)會報錯,所以這里轉成signed類型
cast(rank()over(order by month(order_date)) as signed) as rn_1
from spm_order
where sales_name in ('洪光','范彩')
group by sales_name,month(order_date))a
order by month_1 asc代碼運行結果如下:
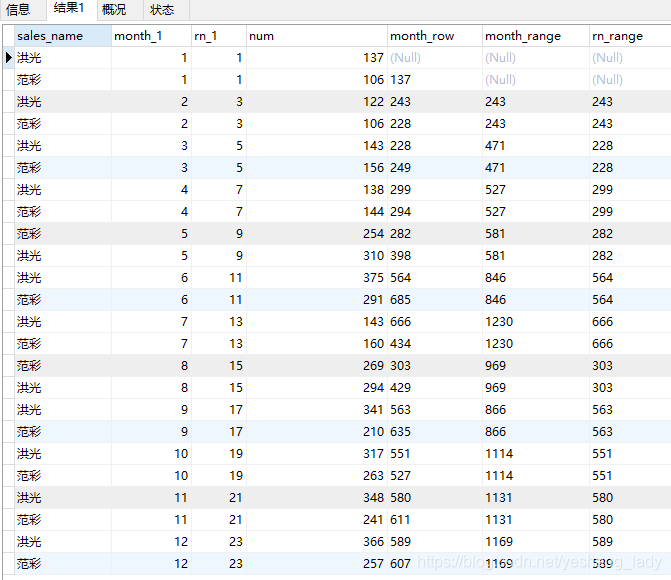
對以上代碼分析:
首先,在這里我新建了一個rn_1列。rn_1列和month_1的區別在于,month_1的數據是連續的,而rn_1列是有中斷的(兩個1之后出現的是3,我是故意要創建一個中斷的序列,來分析一下range的作用范圍)
先來看month_row的區別,month_row列的計算結果為當前行在分區中按month_1升序排序之后排在其前面的兩行(between and限定的)的sum求和值。所以rows后面的between and限定的偏移量是基于他們在分區中的排列位置的。
再來看month_range,通過分析其實驗結果可以發現,month_range列的計算為分區內month_1=當前行-1和month_1=當前行-2(-1,-2是由between an子句決定的。preceding代表負,following代表正)所有列的sum求和值。再來看rn_range, rn_range列的計算結果為分區內month_1=當前行-2的所有里列的sum求和值。所以,rang后面的between and限定的偏移量依據的是當前行的數值。
感謝各位的閱讀!關于“MySQL8.0中的窗口函數是什么”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





