溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“redis面試中常被問到的重點有哪些”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“redis面試中常被問到的重點有哪些”吧!

Redis是面試中繞不過的檻,只要在簡歷中寫了用過Redis,肯定逃不過。
小張:
面試官,你好。我是來參加面試的。
面試官:
你好,小張。我看了你的簡歷,熟練掌握Redis,那么我就隨便問你幾個Redis相關的問題吧。首先我的問題是,Redis是單線程還是多線程呢?
小張:
Redis不同版本之間采用的線程模型是不一樣的,在Redis4.0版本之前使用的是單線程模型,在4.0版本之后增加了多線程的支持。
在4.0之前雖然我們說Redis是單線程,也只是說它的網絡I/O線程以及Set 和 Get操作是由一個線程完成的。但是Redis的持久化、集群同步還是使用其他線程來完成。
4.0之后添加了多線程的支持,主要是體現在大數據的異步刪除功能上,例如 unlink key、flushdb async、flushall async 等
面試官:
回答的很好,那為什么Redis在4.0之前會選擇使用單線程?而且使用單線程還那么快?
小張:
選擇單線程個人覺得主要是使用簡單,不存在鎖競爭,可以在無鎖的情況下完成所有操作,不存在死鎖和線程切換帶來的性能和時間上的開銷,但同時單線程也不能完全發揮出多核CPU的性能。
至于為什么單線程那么快我覺得主要有以下幾個原因:
Redis 的大部分操作都在內存中完成,內存中的執行效率本身就很快,并且采用了高效的數據結構,比如哈希表和跳表。
使用單線程避免了多線程的競爭,省去了多線程切換帶來的時間和性能開銷,并且不會出現死鎖。
采用 I/O 多路復用機制處理大量客戶端的Socket請求,因為這是基于非阻塞的 I/O 模型,這就讓Redis可以高效地進行網絡通信,I/O的讀寫流程也不再阻塞。
面試官:
不錯,那Redis是如何實現數據不丟失的呢?
小張:
Redis數據是存儲在內存中的,為了保證Redis數據不丟失,那就要把數據從內存存儲到磁盤上,以便在服務器重啟后還能夠從磁盤中恢復原有數據,這就是Redis的數據持久化。Redis數據持久化有三種方式。
AOF 日志(Append Only File,文件追加方式):記錄所有的操作命令,并以文本的形式追加到文件中。
RDB 快照(Redis DataBase):將某一個時刻的內存數據,以二進制的方式寫入磁盤。
混合持久化方式:Redis 4.0 新增了混合持久化的方式,集成了 RDB 和 AOF 的優點。
面試官:
那你分別說說 AOF和 RDB的實現原理吧。
小張:
AOF采用的是寫后日志的方式,Redis先執行命令把數據寫入內存,然后再記錄日志到文件中。AOF日志記錄的是操作命令,不是實際的數據,如果采用AOF方法做故障恢復時需要將全量日志都執行一遍。
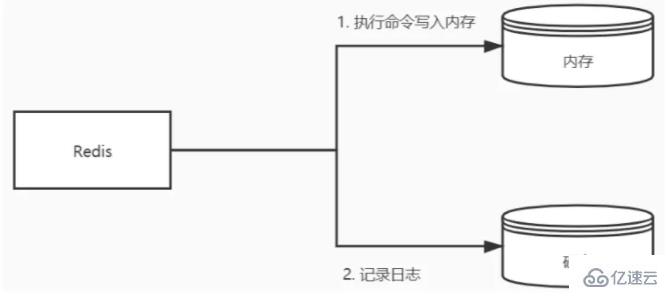
RDB采用的是內存快照的方式,它記錄的是某一時刻的數據,而不是操作,所以采用RDB方法做故障恢復時只需要直接把RDB文件讀入內存即可,實現快速恢復。
面試官:
你剛提到了AOF采用的是 “寫后日志” 的方式,我們平時用的MySQL則采用的是 “寫前日志”,那 Redis為什么要先執行命令,再把數據寫入日志呢?
小張:額頭開始冒汗,問的是些啥問題呀。。。
額,這個主要是由于Redis在寫入日志之前,不對命令進行語法檢查,所以只記錄執行成功的命令,避免出現記錄錯誤命令的情況,而且在命令執行后再寫日志不會阻塞當前的寫操作。
面試官:
那 后寫日志又有什么風險呢?
小張:
我... 這個我不會。
面試官:
好吧,后寫日志主要有兩個風險可能會發生:
數據可能會丟失:如果 Redis 剛執行完命令,此時發生故障宕機,會導致這條命令存在丟失的風險。
可能阻塞其他操作:AOF 日志其實也是在主線程中執行,所以當 Redis 把日志文件寫入磁盤的時候,還是會阻塞后續的操作無法執行。
我還有個問題是 RDB做快照時會阻塞線程嗎?
小張:
Redis 提供了兩個命令來生成 RDB 快照文件,分別是 save 和 bgsave。save 命令在主線程中執行,會導致阻塞。而 bgsave 命令則會創建一個子進程,用于寫入 RDB 文件的操作,避免了對主線程的阻塞,這也是 Redis RDB 的默認配置。
面試官:
RDB 做快照的時候數據能修改嗎?
小張:
save是同步的會阻塞客戶端命令,bgsave的時候是可以修改的。
面試官:
那Redis是怎么解決在bgsave做快照的時候允許數據修改呢?
小張:(你咋還問。。。我?不會啊!)
額,這個我不太清楚...
面試官:
這里主要是利用bgsave的子線程實現的,具體操作如下:
如果主線程執行讀操作,則主線程和 bgsave 子進程互相不影響;
如果主線程執行寫操作,則被修改的數據會復制一份副本,然后 bgsave子進程會把該副本數據寫入 RDB 文件,在這個過程中,主線程仍然可以直接修改原來的數據。
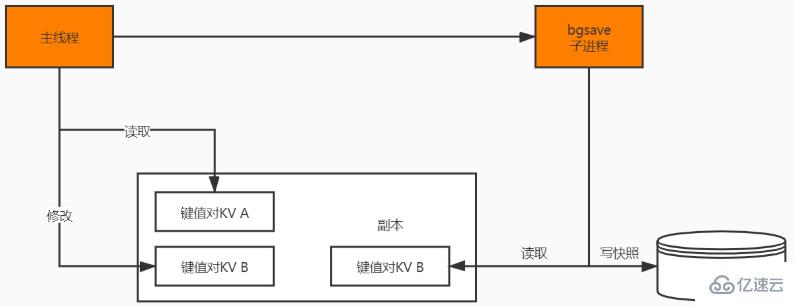
要注意,Redis 對 RDB 的執行頻率非常重要,因為這會影響快照數據的完整性以及 Redis 的穩定性,所以在 Redis 4.0 后,增加了 AOF 和 RDB 混合的數據持久化機制: 把數據以 RDB 的方式寫入文件,再將后續的操作命令以 AOF 的格式存入文件,既保證了 Redis 重啟速度,又降低數據丟失風險。
小張:
學到了學到了。
面試官:
那你再跟我說說Redis如何實現高可用吧?
小張:
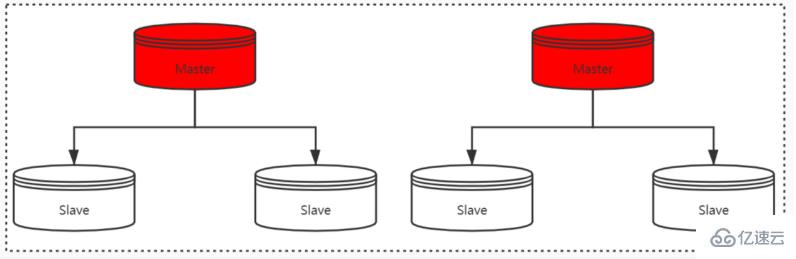
Redis實現高可用主要有三種方式:主從復制、哨兵模式,以及 Redis 集群。
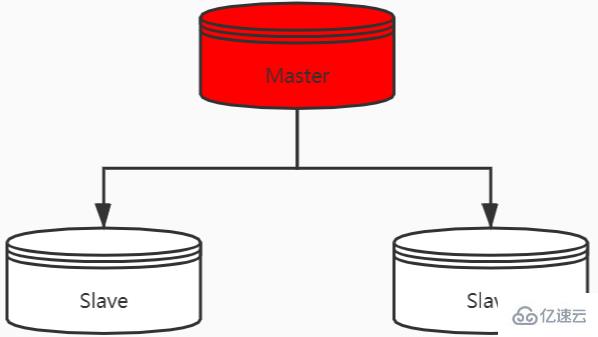
主從復制
將從前的一臺 Redis 服務器,同步數據到多臺從 Redis 服務器上,即一主多從的模式,這個跟MySQL主從復制的原理一樣。
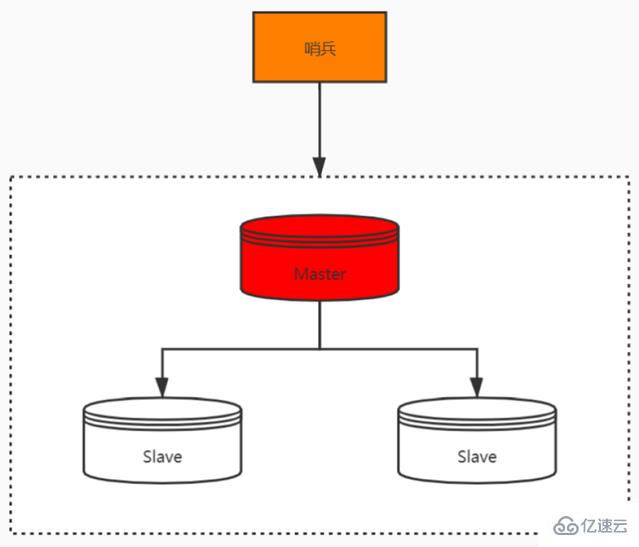
哨兵模式
使用 Redis 主從服務的時候,會有一個問題,就是當 Redis 的主從服務器出現故障宕機時,需要手動進行恢復,為了解決這個問題,Redis 增加了哨兵模式(因為哨兵模式做到了可以監控主從服務器,并且提供自動容災恢復的功能)。
Redis Cluster(集群)
Redis Cluster 是一種分布式去中心化的運行模式,是在 Redis 3.0 版本中推出的 Redis 集群方案,它將數據分布在不同的服務器上,以此來降低系統對單主節點的依賴,從而提高 Redis 服務的讀寫性能。
面試官:
使用哨兵模式在數據上有副本數據做保證,在可用性上又有哨兵監控,一旦master宕機會選舉salve節點為master節點,這種已經滿足了我們的生產環境需要,那為什么還需要使用集群模式呢?
小張:
額,哨兵模式歸根節點還是主從模式,在主從模式下我們可以通過增加salve節點來擴展讀并發能力,但是沒辦法擴展寫能力和存儲能力,存儲能力只能是master節點能夠承載的上限。所以為了擴展寫能力和存儲能力,我們就需要引入集群模式。
面試官:
集群中那么多Master節點,redis cluster在存儲的時候如何確定選擇哪個節點呢?
小張:
這應該是使用了某種hash算法,但是我不太清楚。。。
面試官:
那好,今天的面試就到這里吧,你先回去等我們的面試通知。
小張:
好的,謝謝面試官,你能告訴我redis cluster怎么實現節點選擇的嗎?
面試官:
Redis Cluster采用的是類一致性哈希算法實現節點選擇的,至于什么是一致性哈希算法你自己回去看看。
Redis Cluster將自己分成了16384個Slot(槽位),哈希槽類似于數據分區,每個鍵值對都會根據它的 key,被映射到一個哈希槽中,具體執行過程分為兩大步。
根據鍵值對的 key,按照 CRC16 算法計算一個 16 bit 的值。
再用 16bit 值對 16384 取模,得到 0~16383 范圍內的模數,每個模數代表一個相應編號的哈希槽。
每個Redis節點負責處理一部分槽位,加入你有三個master節點 ABC,每個節點負責的槽位如下:
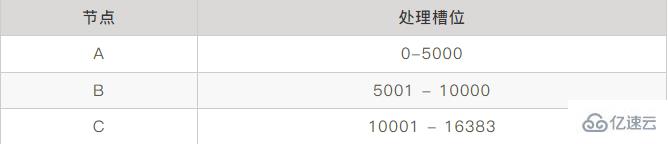
這樣就實現了cluster節點的選擇。
感謝各位的閱讀,以上就是“redis面試中常被問到的重點有哪些”的內容了,經過本文的學習后,相信大家對redis面試中常被問到的重點有哪些這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





