溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇“Matplotlib的bins和rwidth參數怎么實現”文章的知識點大部分人都不太理解,所以小編給大家總結了以下內容,內容詳細,步驟清晰,具有一定的借鑒價值,希望大家閱讀完這篇文章能有所收獲,下面我們一起來看看這篇“Matplotlib的bins和rwidth參數怎么實現”文章吧。
我們在做機器學習相關項目時,常常會分析數據集的樣本分布,而這就需要用到直方圖的繪制。
在Python中可以很容易地調用matplotlib.pyplot的hist函數來繪制直方圖。不過,該函數參數不少,有幾個繪圖的小細節也需要注意。
首先,我們假定現在有個聯邦學習的項目情景。我們有一個樣本個數為15的圖片數據集,樣本標簽有4個,分別為cat, dog, car, ship。這個數據集已經被不均衡地劃分到4個任務節點(client)上。 情境引入
我們在做機器學習相關項目時,常常會分析數據集的樣本分布,而這就需要用到直方圖的繪制。
在Python中可以很容易地調用matplotlib.pyplot的hist函數來繪制直方圖。不過,該函數參數不少,有幾個繪圖的小細節也需要注意。
首先,我們假定現在有個聯邦學習的項目情景。我們有一個樣本個數為15的圖片數據集,樣本標簽有4個,分別為cat, dog, car, ship。這個數據集已經被不均衡地劃分到4個任務節點(client)上,如像下面表示:
N_CLIENTS = 3 num_cls, classes = 4, ['cat', 'dog', 'car', 'ship'] train_labels = [0, 3, 2, 0, 3, 2, 1, 0, 3, 3, 1, 0, 3, 2, 2] #數據集的標簽列表 client_idcs = [slice(0, 4), slice(4, 11), slice(11, 15)] # 數據集樣本在client上的劃分情況
我們需要可視化樣本在任務節點的分布情況。我們第一次可能會寫出如下代碼:
import matplotlib.pyplot as plt
import numpy as np
plt.figure(figsize=(5,3))
plt.hist([train_labels[idc]for idc in client_idcs], stacked=False,
bins=num_cls,
label=["Client {}".format(i) for i in range(N_CLIENTS)])
plt.xticks(np.arange(num_cls), classes)
plt.legend()
plt.show()此時的可視化結果如下:
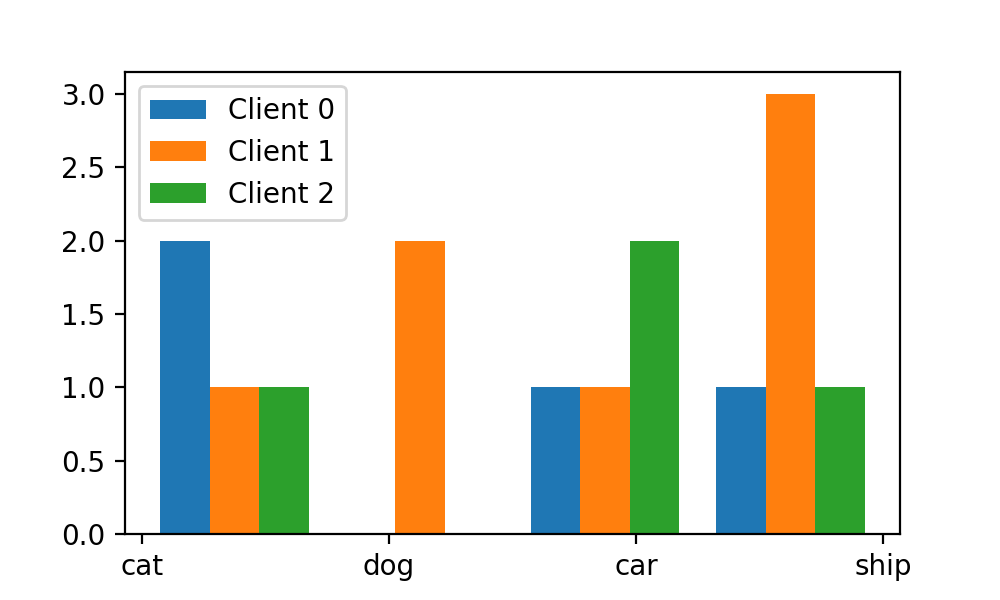
這時我們會發現,我們x軸上的標簽和上方的bar(每個圖像類別對應的3個bar合稱為1個bin)并沒有對齊,而這時劇需要我們調整bins這個參數。
在講述bins參數之前我們先來熟悉一下hist繪圖中bin和bar的含義。下面是它們的詮釋圖:
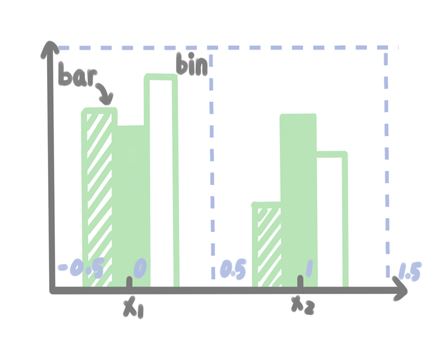
這里\(x_1\)、\(x_2\)是x軸對象,在hist中,默認x軸第一個對象對應刻度為0,第2個對象刻度為1,依次類圖。在這個詮釋圖上,bin(原意為垃圾箱)就是指每個x軸對象所占優的矩形繪圖區域,bar(原意為塊)就是指每個矩形繪圖區域中的條形。 如上圖所示,x軸第一個對象對應的bin區間為[-0.5, 0.5),第2個對象對應的bin區域為[0.5, 1)(注意,hist規定一定是左閉又開)。每個對象的bin區域內都有3個bar。
通過查閱matplotlib文檔,我們知道了bins參數的解釋如下:
bins: int or sequence or str, default: rcParams["hist.bins"] (default: 10)
If bins is an integer, it defines the number of equal-width bins in the range.
If bins is a sequence, it defines the bin edges, including the left edge of the first bin and the right edge of the last bin; in this case, bins may be unequally spaced. All but the last (righthand-most) bin is half-open. In other words, if bins is:
[1, 2, 3, 4]then the first bin is [1, 2) (including 1, but excluding 2) and the second [2, 3). The last bin, however, is [3, 4], which includes 4.
If bins is a string, it is one of the binning strategies supported by numpy.histogram_bin_edges: 'auto', 'fd', 'doane', 'scott', 'stone', 'rice', 'sturges', or 'sqrt'.
我來概括一下,也就是說如果bins是個數字,那么它設置的是bin的個數,也就是沿著x軸劃分多少個獨立的繪圖區域。我們這里有四個圖像類別,故需要設置4個繪圖區域,每個區域相對于x軸刻度的偏移采取默認設置。
不過,如果我們要設置每個區域的位置偏移,我們就需要將bins設置為一個序列。
bins序列的刻度要參照hist函數中的x坐標刻度來設置,本任務中4個分類類別對應的x軸刻度分別為[0, 1, 2, 3] 。如果我們將序列設置為[0, 1, 2, 3, 4]就表示第一個繪圖區域對應的區間是[1, 2),第2個繪圖區域對應的位置是[1, 2),第三個繪圖區域對應的位置是[2, 3),依次類推。
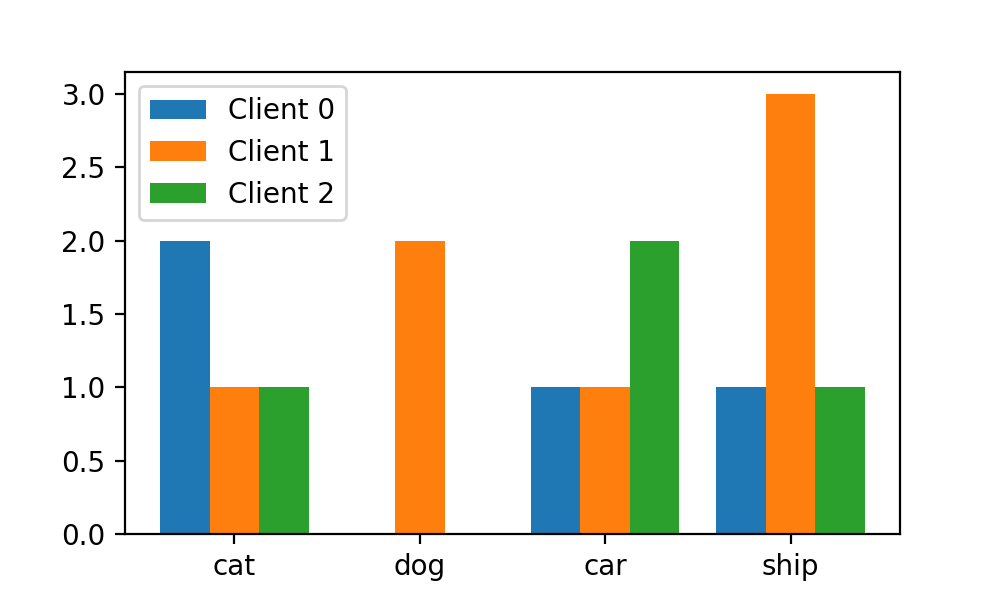
就大眾審美而言,我們想讓每個區域的中心和對應x軸刻度對齊,這第一個區域的區間為[-0.5, 0.5),第二個區域的區間為[0.5, 1.5),依次類推。則最終的bins序列為[-0.5, 0.5, 1.5, 2.5, 3.5]。于是,我們將hist函數修改如下:
plt.hist([train_labels[idc]for idc in client_idcs], stacked=False,
bins=np.arange(-0.5, 4, 1),
label=["Client {}".format(i) for i in range(N_CLIENTS)])這樣,每個劃分區域和對應x軸的刻度就對齊了:
有時x軸的項目多了,每個x軸的對象都要設置3個bar對繪圖空間無疑是一個巨大的占用。在這個情況下我們如何壓縮空間的使用呢?這個時候參數stacked就派上了用場,我們將參數stacked設置為True:
plt.hist([train_labels[idc]for idc in client_idcs],stacked=True
bins=np.arange(-0.5, 4, 1),
label=["Client {}".format(i) for i in range(N_CLIENTS)])可以看到每個x軸對象的bar都“疊加”起來了:
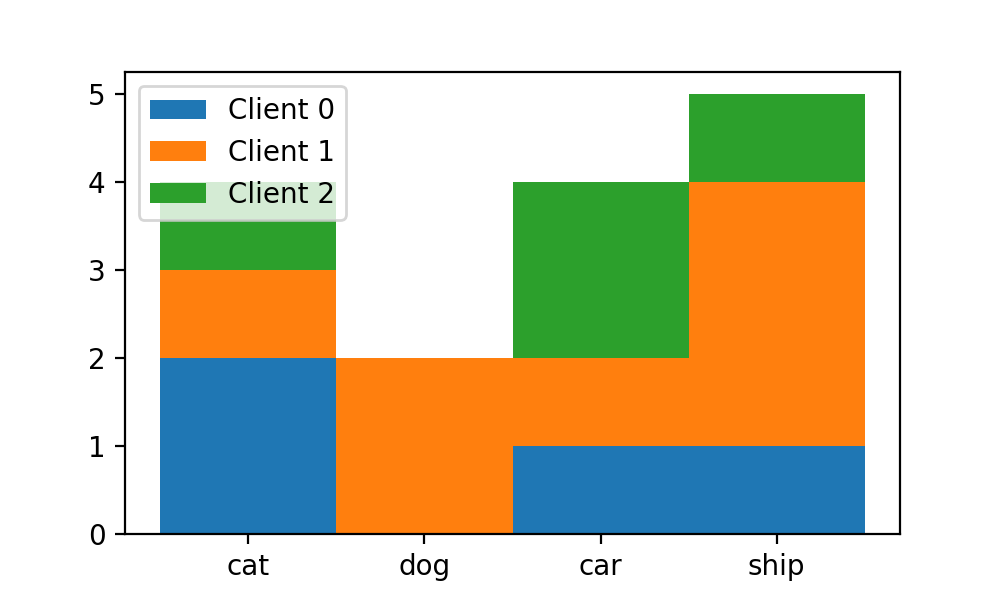
不過,新的問題又出來了,這樣每x軸對象的bar之間完全沒有距離了,顯得十分“擁擠”,我們可否修改bins參數以設置區域bin之間的間距呢?答案是不行,因為我們前面提到過,bins參數中只能將區域設置為連續排布的。
換一個思路,我們設置每個bin內的bar和bin邊界之間的間距。此時,我們需要修改r_width參數。
我們看文檔中對rwidth參數的解釋:
rwidth float or None, default: None
The relative width of the bars as a fraction of the bin width. If None, automatically compute the width.
Ignored if histtype is 'step' or 'stepfilled'.
翻譯一下,rwidth用于設置每個bin中的bar相對bin的大小。這里我們不妨修改為0.5:
plt.hist([train_labels[idc]for idc in client_idcs],stacked=True,
bins=np.arange(-0.5, 4, 1), rwidth=0.5,
label=["Client {}".format(i) for i in range(N_CLIENTS)])修改之后的圖表如下:
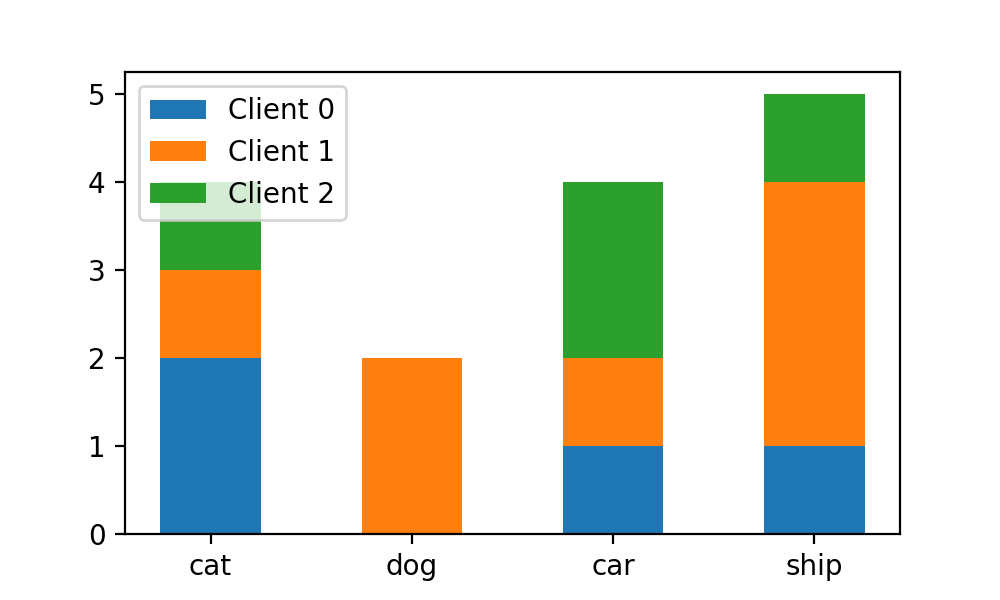
可以看到每個x軸元素內的bar正好占對應bin的寬度的二分之一。
以上就是關于“Matplotlib的bins和rwidth參數怎么實現”這篇文章的內容,相信大家都有了一定的了解,希望小編分享的內容對大家有幫助,若想了解更多相關的知識內容,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





