溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關OpenCV中圖像如何實現分割與修復的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
圖像分割本質就是將前景目標從背景中分離出來。在當前的實際項目中,應用傳統分割的并不多,大多是采用深度學習的方法以達到更好的效果;當然,了解傳統的方法對于分割的整體認知具有很大幫助,本篇將介紹些傳統分割的一些算法;
原理圖如下:
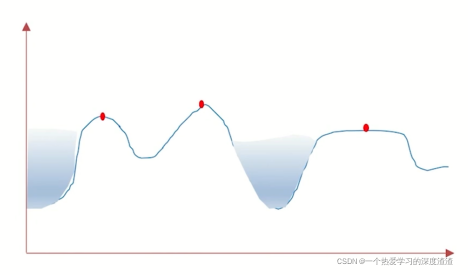
利用二值圖像的梯度關系,設置一定邊界,給定不同顏色實現分割;
實現步驟:
標記背景 —— 標記前景 —— 標記未知區域(背景減前景) —— 進行分割
函數原型:
watershed(img,masker):分水嶺算法,其中masker表示背景、前景和未知區域;
distanceTransform(img,distanceType,maskSize):矩離變化,求非零值到最近的零值的距離;
connectedComponents(img,connectivity,…):求連通域;
代碼實現:
img = cv2.imread('water_coins.jpeg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 加入cv2.THRESH_OTSU表示自適應閾值(實現更好的效果)
ret, thresh = cv2.threshold(gray, 100, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
# 開運算(去噪點)
kernel = np.ones((3,3), np.int8)
open1 = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, kernel, iterations = 2)
#膨脹
beijing = cv2.dilate(open1, kernel, iterations = 1)
# 獲取前景
tmp = cv2.distanceTransform(open1, cv2.DIST_L2, 5)
ret, qianjing = cv2.threshold(tmp, 0.7*tmp.max(), 255, cv2.THRESH_BINARY)
# 獲取未知區域
beijingj = np.uint8(beijing)
qianjing = np.uint8(qianjing)
unknow = cv2.subtract(beijing, qianjing)
# 創建連通域
ret, masker = cv2.connectedComponents(qianjing)
masker = masker + 1
masker[unknow==255] = 0
# 進行圖像分割
result = cv2.watershed(img, masker)
img[result == -1] = [0, 0, 255]
cv2.imshow('result', img)
cv2.waitKey(0)
原理:通過交互的方式獲得前景物體;
1、用戶指定前景的大體區域,剩下的為背景區域;
2、用戶可以明確指定某些地方為前景或背景;
3、采用分段迭代的方法分析前景物體形成模型樹;
4、根據權重決定某個像素是前景還是背景;
函數原型:
grabCut(img,mask,rect,bgdModel,fbgModel,5,mode)
mask:表示生成的掩碼,函數輸出的值,其中0表示背景、1表示前景、2表示可能背景、3表示可能前景;
代碼如下:
class App:
flag_rect = False
rect=(0, 0, 0, 0)
startX = 0
startY = 0
def onmouse(self, event, x, y, flags, param):
if event == cv2.EVENT_LBUTTONDOWN:
self.flag_rect = True
self.startX = x
self.startY = y
print("LBUTTIONDOWN")
elif event == cv2.EVENT_LBUTTONUP:
self.flag_rect = False
cv2.rectangle(self.img,
(self.startX, self.startY),
(x, y),
(0, 0, 255),
3)
self.rect = (min(self.startX, x), min(self.startY, y),
abs(self.startX - x),
abs(self.startY -y))
print("LBUTTIONUP")
elif event == cv2.EVENT_MOUSEMOVE:
if self.flag_rect == True:
self.img = self.img2.copy()
cv2.rectangle(self.img,
(self.startX, self.startY),
(x, y),
(255, 0, 0),
3)
print("MOUSEMOVE")
print("onmouse")
def run(self):
print("run...")
cv2.namedWindow('input')
cv2.setMouseCallback('input', self.onmouse)
self.img = cv2.imread('./lena.png')
self.img2 = self.img.copy()
self.mask = np.zeros(self.img.shape[:2], dtype=np.uint8)
self.output = np.zeros(self.img.shape, np.uint8)
while(1):
cv2.imshow('input', self.img)
cv2.imshow('output', self.output)
k = cv2.waitKey(100)
if k == 27:
break
if k == ord('g'):
bgdmodel = np.zeros((1, 65), np.float64)
fgdmodel = np.zeros((1, 65), np.float64)
cv2.grabCut(self.img2, self.mask, self.rect,
bgdmodel, fgdmodel,
1,
cv2.GC_INIT_WITH_RECT)
# 注意np.where的用法可以用來篩選前景
mask2 = np.where((self.mask==1)|(self.mask==3), 255, 0).astype('uint8')
self.output = cv2.bitwise_and(self.img2, self.img2, mask=mask2)由于效果并不是特別明顯,并且運行時耗時會比較長,在這里就不展示了;
注意:np.where的用法需要掌握,可以將一個矩陣中選定的值與未選定的值做二值化的處理;
實現原理:
并不是用來進行圖像分割的,而是在色彩層面的平滑濾波;
中和色彩分布相近的顏色,平滑色彩細節,腐蝕掉面積較小的顏色區域;
以圖像上任意點P為圓心,半徑為sp,色彩幅值為sr進行不斷的迭代;
函數原型:
pyrMeanShiftFiltering(img,sp,sr,…)
代碼實現:
img = cv2.imread('flower.png')
result = cv2.pyrMeanShiftFiltering(img, 20, 30)
cv2.imshow('img', img)
cv2.imshow('result', result)
cv2.waitKey(0)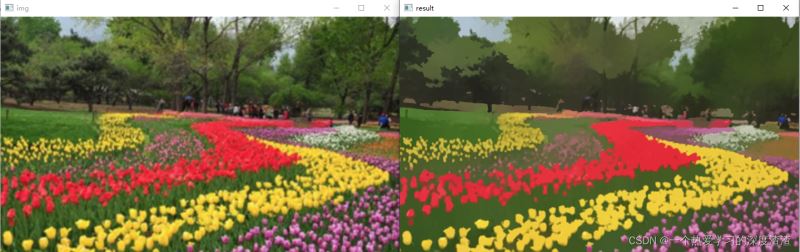
通過該函數可以實現色彩的平滑處理,做特效也是不錯的(有種卡通化的效果),雖然該函數并不能直接做圖像分割,但處理后的圖像可以通過canny算法進行邊緣檢測;
Canny代碼:
img = cv2.imread('key.png')
result = cv2.pyrMeanShiftFiltering(img, 20, 30)
img_canny = cv2.Canny(result, 150, 300)
contours, _ = cv2.findContours(img_canny, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cv2.drawContours(img, contours, -1, (0, 0, 255), 2)
cv2.imshow('img', img)
cv2.imshow('result', result)
cv2.imshow('canny', img_canny)
cv2.waitKey(0)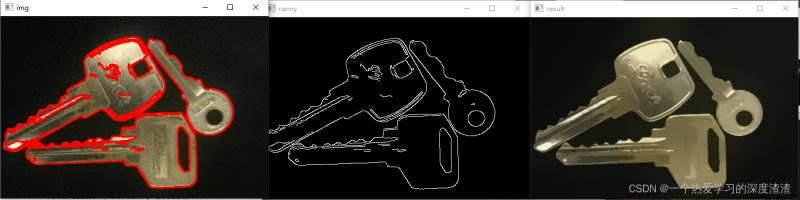
首先需要了解視頻的一些原理:
視頻是一組連續幀組成的(一幀也可以看作一副圖像)
幀與幀之間關系密切(又稱為GOP)
在GOP中,背景幾乎是不變的
主要有以下幾種方法:
1、MOG去背景
原理:混合高斯模型為基礎的前景、背景分割法;
函數原型:
createBackgroundSubtractorMOG(其中的默認值就不做講解了)
代碼實戰:
cap = cv2.VideoCapture('./vtest.avi')
mog = cv2.bgsegm.createBackgroundSubtractorMOG()
while(True):
ret, frame = cap.read()
mask = mog.apply(frame)
cv2.imshow('img', mask)
k = cv2.waitKey(10)
if k == 27:
break
cap.release()
cv2.destroyAllWindows()
1、MOG2
說明:與MOG算法類似,但對于亮度產生的陰影有更好的識別效果,噪點更多;
函數原型:createBackgroundSubtractorMOG2(默認參數不作介紹)
效果展示:

2、GMG
說明:靜態背景圖像估計和每個像素的貝葉斯分割抗噪性更強;
函數原型:createBackgroundSubtractorGMG()
效果展示:

總結:GMG開始會不顯示一段時間,這是由于初始參考幀的數量和過大;對比業界的效果來看,這些傳統方法的效果并不好,特別是對比深度學習的算法;但很多原理值得我們取思考借鑒,模型只是給出我們問題的優解,如果能將傳統算法結合深度學習算法,那是否能在提速的同時,也達到一個可觀的效果,這是我思考的一個點,歡迎大家發表自己的意見;
說明:我們的圖像往往會有一些馬賽克的存在,特別是一些老照片會有不必要的圖案,圖像修復就是用于解決這類問題,并不等同于超清化;
函數原型:
inpaint(img,mask,inpaintRadius,兩種方式:INPAINT_NS、INPAINT_TELEA)
代碼案例:
img = cv2.imread('inpaint.png')
mask = cv2.imread('inpaint_mask.png', 0)
result = cv2.inpaint(img, mask, 5, cv2.INPAINT_TELEA)
cv2.imshow('img', img)
cv2.imshow('result', result)
cv2.waitKey()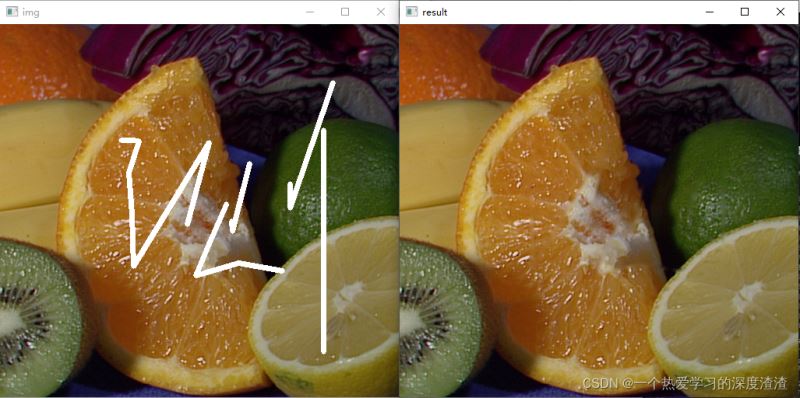
總結:從結果來看,效果相當不錯,但前提我們需要知道需要修復的部分,所以應用的場景也會比較局限;
感謝各位的閱讀!關于“OpenCV中圖像如何實現分割與修復”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





