溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了Linux的grep,sed,awk命令怎么用的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇Linux的grep,sed,awk命令怎么用文章都會有所收獲,下面我們一起來看看吧。
正則表達式:REGular EXPression, REGEXP 元字符: .: 匹配任意單個字符 []: 匹配指定范圍內的任意單個字符 [^]:匹配指定范圍外的任意單個字符 字符集合:[:digit:], [:lower:], [:upper:], [:punct:], [:space:], [:alpha:], [:alnum:] 注意:字符集合要用[ ]包含 匹配次數(貪婪模式): *: 匹配其前面的字符任意次 a, b, ab, aab, acb, adb, amnb a*b, a?b a.*b .*: 任意長度的任意字符 \?: 匹配其前面的字符1次或0次 \+:匹配至少一次 \{m,n\}:匹配其前面的字符至少m次,至多n次 \{1,\} \{0,3\} 備注:至少0次,必須要顯示的寫出來。 位置錨定: ^: 錨定行首,此字符后面的任意內容必須出現在行首 $: 錨定行尾,此字符前面的任意內容必須出現在行尾 ^$: 空白行 \
\>或\b: 錨定詞尾,其前面的任意字符必須作為單詞的尾部出現 分組: \(\) \(ab\)* 后向引用 \1: 引用第一個左括號以及與之對應的右括號所包括的所有內容 \2: \3:可以看到標準正則表達的使用過程中,許多符號都需要轉義,這在工作中帶來了一定的不便,因此擴展的正則表達式便出現了。
1. 字符匹配: . [abc]:包含abc任意一個字符 [^abc]:不包含abc任意一個字符 2. 次數匹配(不用再轉義): *: ?: +: 匹配其前面的字符至少1次 {m,n} 3. 位置錨定: ^ $ \
\> 4. 分組(不用再轉義): ():分組 \1, \2, \3, ... 5. 或者 |: or C|cat: C或cat(表示的是整個部分)可以看到,使用擴展的正則表達式可以省略很多的轉義符號,這尤其在寫sed語句時極大的提高了代碼的可讀性。建議優先使用擴展的正則表達式。
grep命令家族由grep, egrep, fgrep 三個子命令組成,適用于不同的場景。具體如下: 命令 描述 grep 原生的grep命令,使用“標準正則表達式”作為匹配標準。 egrep 擴展的grep命令,相當于$(grep -E),使用“擴展正則表達式”作為匹配標準。 fgrep 簡化版的grep命令,不支持正則表達式,但搜索速度快,系統資源使用率低。
語法 grep [options] PATTERN [FILE…] options部分 -i:忽略大小寫 –color:高亮匹配上的字符串 -v: 顯示沒有被模式匹配到的行 -o:只顯示被模式匹配到的字符串 -E:使用擴展的正則表達式 PATTERN部分 以字符串的方式給定匹配模板,可以使用普通字符串以及正則表達式(標準&擴展)。 FILE部分 需要查找內容的文件。
sed全稱是Stream EDitor sed是一個流編輯器、行編輯器
sed [option] ‘script’ [input file]… option部分 -n:不輸出模式空間中的內容到stdout -e:可以在sed命令中指定多個script腳本,多點編輯功能 -f:輸入sed腳本,腳本中寫著編輯命令 -r:支持使用擴展的正則 -i:直接編輯源文件
script部分 地址定界編輯命令(和vim命令相似) 1)空地址:全文編輯 2)單地址:   #:指定某一行,對特定行進行編輯   /pattern/:指定模式匹配到的那一行 3)地址范圍:   #,#   #,+#   #,/pattern/   /pattern1/,/pattern2/ 4)步進地址:   1~2:以1為起始行,然后遞進2行向下匹配   2~2:所有偶數行 5)編輯命令:   d:刪除整行,d放在最后   p:顯示模式空間中的內容, 放在最后   a:在匹配的行后面增加文本,使用\n支持多行追加。a放在定界后面   i:在前面加文本。舉例:sed ‘3i hello’ xxx   c:替換行為指定的文本。舉例:sed ‘3c text’ xxx 把第三行替換成text。sed -i ‘/xyz/c helloworld’ num.txt   w:保存模式空間中匹配的內容到指定位置。舉例:sed -n ‘/[#]/w /tmp/demo’ /etc/fstab 將/etc/fstab中非#開頭的行保存到/tmp/demo中。   r:讀取指定文件的內容添加到當前文件匹配到的行后面,進行文件合并。   !:條件取反。用法:地址定界!編輯命令。   s///:條件替換。 替換標記備注:g(全局替換),p(顯示替換成功的行)
替換舉例:根據輸入查找目錄 echo “/var/log/messages” | sed ‘s@/+$/?@@’
模式空間與保持空間 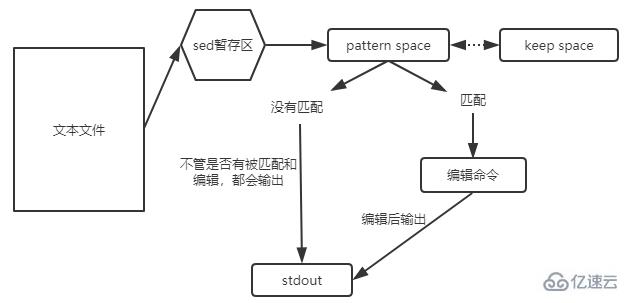
在模式空間中,完成匹配的操作。當沒有匹配上的時候,文本行內容會默認輸出stdout;當匹配上文本行的時候,會執行編輯命令,執行結果輸出到stdout中。 保持空間可以理解為一個暫存區,只是用于完成額外的動作。
參數 h:把模式空間中的內容覆蓋至保持空間中; H:把模式空間中的內容追加至保持空間中; g:把保持空間中的內容覆蓋至模式空間中; G:把保持空間中的內容追加至模式空間中; x:把模式空間中的內容與保持空間中的內容互換; n:覆蓋讀取匹配到的行的下一行(改變指向)至模式空間中; N:追加讀取匹配到的行的下一行(改變指向)至模式空間中; d:刪除模式空間中的行; D:刪除多行模式空間中的所有行;
3. 舉例 sed -n 'n;p' FILE:顯示偶數行; sed '1!G;h;$!d' FILE:逆序顯示文件的內容; sed '$!d' FILE:取出最后一行; sed '\$!N;$!D' FILE:取出文件后兩行; sed '/^$/d;G' FILE:刪除原有的所有空白行,而后為所有的非空白行后添加一個空白行; sed 'n;d' FILE:顯示奇數行; sed 'G' FILE:在原有的每行后方添加一個空白行;
舉例:提取字符串
/bin/bash info="hellozimskyshenzhen" echo $info | sed 's/hello\(\w\+\)shenzhen/\1/g'
備注:
sed中不支持\d,如果要用數字用[0-9],但是支持\w。
sed中的()要轉義,+要轉義,大于小于號要轉義。
舉例:判斷是否存在指定格式的字符串
#!/bin/bash # 判斷輸入是否為整數 if [ -n "$(echo $1 | sed -n '/^[0-9]\+$/p')" ] ; then echo 'yes' else echo 'no' fi
awk是發明該工具三個作者姓名的首字母簡稱,awk是一個報表生成器,主要用于格式化輸出。格式化文本輸出器。
1. 語法 gawk [option] ‘program’ FILE 其中program: PATTERN{ACTION STATEMENTS} {動作指令}可以理解成為命令,最常用的是print、printf
2. awk讀取文檔過程 按照行來讀取文檔,根據輸入分隔符切分成小部分(用內建變量來表示1,用來處理。0表示顯示整行。
3. 選項option -F:指名輸入字段的分隔符; -v:用來實現自定義變量var=value;
4. PATTERN(用于定界)  空:表示處理文件的每一行  /pattern/:使用正則匹配需要處理的行  !/pattern/:上面取反  關系表達式:結果為真假,結果為真的處理,假的不處理。非0非空字符串為真,其余為假。  行定界:不支持直接給出數字的格式(1,2{…})。見舉例。  BEGIN/END模式:BEGIN{}表示僅在開始處理文件中的文本之前執行一次的程序,例如打印表頭。END{}表示文本處理完成之后執行一次,例如匯總數據。
舉例: awk -F: '$NF=="/bin/bash" {print $1, $NF}' /etc/passwd awk -F: '$NF!"/bash/$"{print $1,$NF}' passwd awk -F: '$3
awk -F; '(NR>=2&&NR
awk -F: '{printf "%-15s %10s\n", $1, $2}' /etc/passwd5. 變量
內建變量(在引用變量時不用加::輸入字段分隔符,默認空白字符。使用指定。:輸出字段分隔符。使用指定。:輸入時的換行符:輸出時的換行符:每一行的字段數量。加上NF表示最后一列。 NR:number of record 文件的行數,打印出來是打印行號 FNR:多個文件中的行數分別計數 FILENAME:當前文件的文件名 ARGC:參數命令行中參數的個數 ARGV**:返回數組,命令行中的每個參數 舉例:awk ‘BEGIN {print ARGV[0]}’ /etc/fstab /etc/issue 在這里ARGV[0]是awk,固定為第0個參數。ARGV[1]是/etc/fstab,ARGV[2]是/etc/issue 舉例:awk -v FS=’:’ ‘{print $1}’ -v OFS=’:’ /etc/passwd 指名冒號作為輸入的分隔符。同awk -F: …
自定義變量 方法1:-v var=value (區分字符的大小寫) 方法2:在program中定義
舉例:awk -v test=’hello’ ‘BEGIN {print test}’ awk ‘BEGIN {test=’hello’ print test}’
6. 常用的ACTION命令
print 輸出格式:print item1,item2 … 備注:使用逗號作為分隔符;輸出item可以是字符串、內建變量、awk表達式;若省略item,則顯示$0整行;
printf 格式化輸出:printf FORMAT, item1, item2…按位放在format中。 注意事項:format必須要給出;如需換行,必須要顯示寫出;format中需要為后面每個item指定格式符;
Expressions
Control statements:控制語句if,while if(condition){statement} if(condition){statement} else {statements} while(condition) {statements} do {statements} while(condition) for(expr1;expr2;expr3) {statements} break continue delete array[index] delete array刪除整個數組 exit 退出語句
Compound statements:組合語句
Input statements:輸入語句
Output statements:輸出語句 格式符:  %c:顯示字符的ASCII值  %d:顯示十進制整數  %e:科學計數法數值顯示  %f:顯示為浮點數  %g:以科學計數法顯示浮點數  %s:顯示字符串  %u:顯示無符號整數  %%:顯示%自身 修飾符:  #[.#]:第一個數字用于控制顯示字符的寬度,第二個數字表示小數的精度(對于浮點數而言);輸出默認右對齊%15s,左對齊:%-15s;+:表示帶正負符號; 操作符:  算數操作符:+-/* ; +x把字符串轉換成數值;-x改成負數;  字符串操作符:字符串連接(沒有操作符)  復制操作符:=,+=,-=,/=,++,–  比較操作符:>, 模式匹配符:  ~:左側的字符串是否被模式匹配  !~:左側的字符串是否不能被模式匹配 邏輯操作符:  &&:與  ||:或  !:非 函數調用:  function_name(arg1, arg2, …) 條件表達式:  selector?true_exp:false_exp 和三目運算符一樣
操作例子
# 一般來說, 打印無狀態內容放在BEGIN和END塊中 awk -v begin="hello" -v end="ok" -F: 'BEGIN{print begin}; {print $1, $NF}; END{print end}' /etc/passwdawk常用內置變量
$1:表示第一列 $NF:表示最后一列 $NR:表示行號
常用條件表示
1) /指定內容/
這種方式可以匹配到含有“指定內容”的行,在條件中不添加$#所帶的項,建議不使用正則,有異常情況。
awk -F: '/nologin/{print $0}' /etc/passwd #匹配到含有nologin關鍵字的行 seq 100 | awk '/1/{print $1}'2) $#=/指定內容/
這種方式指定第#列匹配指定內容
awk -F: '$1=/bin/{print $0}' /etc/passwd3) $#~/指定內容/
這種方式用于指定列模糊匹配(正則匹配)指定內容,并獲取該行。
awk -F: '$1~/dae/{print $1}' /etc/passwd #正向選擇 awk -F: '$1!~/dae/{print $1}' /etc/passwd #反向選擇4) 值判斷
使用>,=,
awk -F: '$3>=10{print $1}' /etc/passwd5) 邏輯判斷
使用&&,||來進行邏輯判斷。
awk -F: '$3>=5 && $3
6) if條件判斷
awk -F: '{if ($NF~/nologin$/){i++}else{j++}}; END{print i, j}' /etc/passwd #注意if-else條件判斷是放在{}中的7) 字典使用
在awk中可以定義數組類型,用于統計。
awk '{ip[$1]++}; END{for (i in ip) {print i, ip[i]}}' access.log #解析: 將第一列ip設置為字典的key,當出現一次相同的ip時自增1,用于統計所有的ip計數。 #for循環中取到每個字典對應的key,再使用print塊打印出來。注意花括號的隔離。 #QQ號 等級 時長 #統計等級(30
#1234 12 23 #1234 10 122 #1233 92 4212 #1233 42 4252 #1239 87 2313 #1233 56 1121 #1231 19 45 #1235 45 679 cat data | awk '$2>=30&&$2關于“Linux的grep,sed,awk命令怎么用”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“Linux的grep,sed,awk命令怎么用”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





