溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章的內容主要圍繞Linux系統怎么安裝sqoop進行講述,文章內容清晰易懂,條理清晰,非常適合新手學習,值得大家去閱讀。感興趣的朋友可以跟隨小編一起閱讀吧。希望大家通過這篇文章有所收獲!
正如Sqoop的名字所示:Sqoop是一個用來將關系型數據庫和Hadoop中的數據進行相互轉移的工具,可以將一個關系型數據庫(例如Mysql、Oracle)中的數據導入到Hadoop(例如HDFS、Hive、Hbase)中,也可以將Hadoop(例如HDFS、Hive、Hbase)中的數據導入到關系型數據庫(例如Mysql、Oracle)中。如下圖所示: 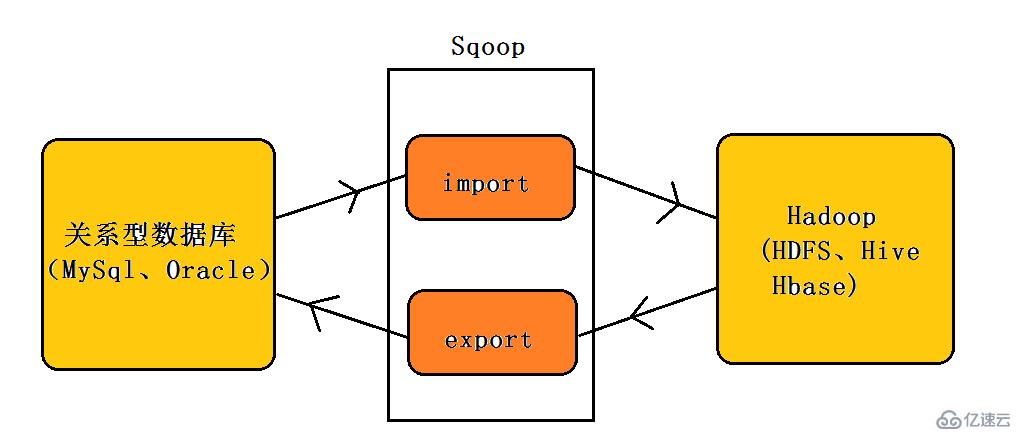 2、Sqoop架構 Sqoop架構:
2、Sqoop架構 Sqoop架構: 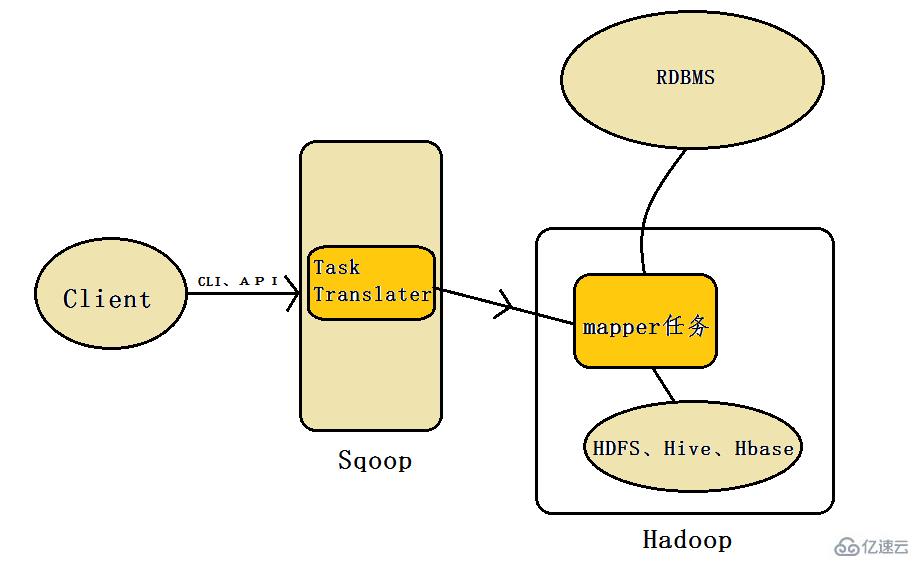 正如上圖所示:Sqoop工具接收到客戶端的shell命令或者Java api命令后,通過Sqoop中的任務翻譯器(Task Translator)將命令轉換為對應的MapReduce任務,而后將關系型數據庫和Hadoop中的數據進行相互轉移,進而完成數據的拷貝。
正如上圖所示:Sqoop工具接收到客戶端的shell命令或者Java api命令后,通過Sqoop中的任務翻譯器(Task Translator)將命令轉換為對應的MapReduce任務,而后將關系型數據庫和Hadoop中的數據進行相互轉移,進而完成數據的拷貝。
Hadoop
關系型數據庫(MySQL/Oracle)
HBase
Hive
ZooKeeper
tar -zxvf .tar.gz -C 目標目錄
mv sqoop-1.4.7.bin__hadoop-2.6.0/ sqoop-1.4.7
進入sqoop-1.4.7/conf路徑,重命名配置文件:
mv sqoop-env-template.sh sqoop-env.sh
修改sqoop-env.sh信息:(若配置了環境變量,可通過
echo $XXXXX_HOME
查詢安裝位置)
vi sqoop-env.sh
#Set path to where bin/hadoop is available export HADOOP_COMMON_HOME=Hadoop安裝路徑 #Set path to where hadoop-*-core.jar is available #export HADOOP_MAPRED_HOME=Hadoop安裝路徑 #set the path to where bin/hbase is available #export HBASE_HOME=HBase安裝路徑 #Set the path to where bin/hive is available #export HIVE_HOME=Hive安裝路徑 #Set the path for where zookeper config dir is #export ZOOCFGDIR=ZooKeeper 配置文件夾 路徑 復制代碼
cp /XXX/hive/conf/hive-site.xml /XXX/sqoop-1.4.7/conf/
修改配置文件:
vi /etc/profile
增加以下內容:
export SQOOP_HOME=sqoop安裝路徑
export PATH=$PATH:$SQOOP_HOME/bin
聲明環境變量:
source /etc/profile
sqoop version
導入MySQL驅動到sqoop/lib下
導入Oracle驅動到sqoop/lib下
參數查看:Sqoop官網 -> documentation -> Sqoop User Guide
import 導入數據到集群
export 從集群導出數據
create-hive-table 創建hive表
import-all-tables 指定關系型數據庫所有表到集群
list-databases 列出所有數據庫
list-tables 列出所有數據庫表
merge 合并數據
codegen 獲取某張表數據生成JavaBean并打Jar包
功能:MySQL/Oracle –> HDFS/Hive
修改MySQL訪問權限:
update user set host='%' where host='localhost';
delete from user where Host='127.0.0.1';
delete from user where Host='bigdata01';
delete from user where Host='::1';
flush privileges;
use mysql;
select User, Host, Password from user;
查看權限:
修改權限為所有用戶都可訪問:
操作命令:
準備工作:
導入命令:
開啟hive服務
在hive中創建好要導入的對應表
FAILED: SemanticException [Error 10072]: Database does not exist: XXXXXXXX
報錯原因:Sqoop沒有關聯Hive
解決方法:
cp /XXX/hive/conf/hive-site.xml /XXX/sqoop-1.4.7/conf/
ERROR tool.ImportTool: Import failed: org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://bigdata01:9000/XXXXXXXXXX already exists
報錯原因:hdfs中存在同名路徑
解決方法:
指定新路徑或者刪除hdfs中原文件
ERROR tool.ImportTool: Import failed: java.io.IOException: java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConf
報錯原因:hive環境變量配置缺失
解決方法:——Hadoop環境加入Hive依賴
source /etc/profile
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HIVE_HOME/lib/*
vi /etc/profile
修改配置文件:
增加以下內容:
聲明環境變量:
sqoop import --connect jdbc:mysql://bigdata01:3306/數據庫名 --username root --password 密碼 --table 表名 --num-mappers 1 --hive-import --fields-terminated-by "\t" --hive-overwrite --hive-table hive數據庫名.表名
在Hive中可以看到指定表中已傳入數據信息
可能報錯1:
可能報錯2:
可能報錯3:
導出命令:
Linux本地查看hdfs上傳結果:
使用query對數據進行過濾:
直接過濾字段:
sqoop import --connect jdbc:mysql://bigdata01:3306/數據庫名 # 連接MySQL --username root # 用戶名 --password XXXXXX # 密碼 --table 表名 # 上傳至HDFS的表 --target-dir /YYYYYYY # HDFS目標文件夾 --num-mappers 1 # 指定map運行 --fields-terminated-by "\t" # 指定分隔符
hdfs dfs -cat /XXXXXXX/part-m-00000
sqoop import --connect jdbc:mysql://bigdata01:3306/數據庫名 --username root --password XXXXXX --table 表名 --target-dir /YYYYYYY --num-mappers 1 --fields-terminated-by "\t" --query 'select * from 表名 where 條件 and $CONDITIONS' # $CONDITIONS 對mapper進行索引
sqoop import --connect jdbc:mysql://bigdata01:3306/數據庫名 --username root --password XXXXXX --table 表名 --target-dir /YYYYYYY --num-mappers 1 --columns 字段名
本地mysql表上傳至hdfs:
本地mysql表上傳至hive:
功能:HDFS/Hive –> MySQL/Oracle
操作命令:
導出命令:
sqoop emport --connect jdbc:mysql://bigdata01:3306/數據庫名 # 連接MySQL --username root # 用戶名 --password XXXXXX # 密碼 --table 表名 # 目標mysql表 --export-dir /user/hive/warehouse/YYYYYYY # hive文件夾 --num-mappers 1 # 指定map運行 --input-fields-terminated-by "\t" # 指定分隔符
hive表導出至本地mysql:
操作命令:
sqoop list-databases --connect jdbc:mysql://bigdata01:3306/ --username root --password 密碼
操作命令:
sqoop codegen --connect jdbc:mysql://bigdata01:3306/數據庫名 --username root --password 密碼 --table 表名 -- bindir Linux本地路徑 # 指定Jar包打包路徑 --class-name 類名 # 指定Java類名 --fields-terminated-by "\t"
操作命令:
sqoop merge --new-data hdfs新表路徑 --onto hdfs舊表路徑 --target-dir /YYYYYYY # 合并后的hdfs路徑 --jar-file = # Linux本地Jar包路徑 --class-name XXXXX # Jar包的類 --merge-key id # 合并依據
注意:merge操作是一個新表替代舊表的操作,如果有沖突id的話新表數據替換舊表數據,如果沒有沖突則是新表數據添加到舊表的數據。
感謝你的閱讀,相信你對“Linux系統怎么安裝sqoop”這一問題有一定的了解,快去動手實踐吧,如果想了解更多相關知識點,可以關注億速云網站!小編會繼續為大家帶來更好的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





