溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Elasticsearch節點、集群、分片及副本是什么”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Elasticsearch節點、集群、分片及副本是什么”吧!
Elasticsearch是一個基于Lucene的搜索服務器。它提供了一個分布式多用戶能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java語言開發的,并作為Apache許可條款下的開放源碼發布,是一種流行的企業級搜索引擎。

Elasticsearch 分布式特性包括如下幾個點:
高可用
什么是高可用?CAP 定理是分布式系統的基礎,也是分布式系統的 3 個指標:
Consistency(一致性)
Availability(可用性)
Partition tolerance(分區容錯性)
那高可用(High Availability)是什么?高可用,簡稱 HA,是系統一種特征或者指標,通常是指,提供一定性能上的服務運行時間,高于平均正常時間段。反之,消除系統服務不可用的時間。
衡量系統是否滿足高可用,就是當一臺或者多臺服務器宕機的時候,系統整體和服務依然正常可用。舉個例子,一些知名的網站保證 4 個 9 以上的可用性,也就是可用性超過 99.99%。那 0.01% 就是所謂故障時間的百分比。
Elasticsearch 在高可用性上,體現如下兩點:
服務可用性:允許部分節點停止服務,整體服務沒有影響
數據可用性:允許部分節點丟失,最終不會丟失數據
可擴展
隨著公司業務發展,Elasticsearch 也面臨兩個挑戰:
搜索數據量從百萬到億量級
搜索請求 QPS 也猛增
那么需要將原來節點和增量數據重新從 10 個節點分布到 100 個節點。Elasticsearch 可以橫向擴展至數百(甚至數千)的服務器節點,同時可以處理PB級數據。Elasticsearch 為了可擴展性而生,由小規模集群增長為大規模集群的過程幾乎完全自動化,這是水平擴展的體現。
Elasticsearch 分布式特性
上面通過可擴展性,可以看出 Elasticsearch 分布式的好處明顯:
存儲可以水平擴容,水平空間換時間
部分節點停止服務,整個集群服務不受影響,照樣正常提供服務
Elasticsearch 在后臺自動完成了分布式相關工作,如下:
自動分配文檔到不同分片或者多節點上
均衡分配分片到集群節點上,index 和 search 操作時進行負載均衡
復制每個分片,支持數據冗余,防止硬件故障數據丟失
集群擴容時,無縫整合新節點,并且重新分配分片
Elasticsearch 集群知識點如下:
不同集群通過名字區分,默認集群名稱為 “elasticsearch”
集群名 cluster name ,可以通過配置文件修改或者命令行 -E cluster.name=user-es-cluster 進行設置一個集群由多個節點組成
Elasticsearch 節點 & 集群
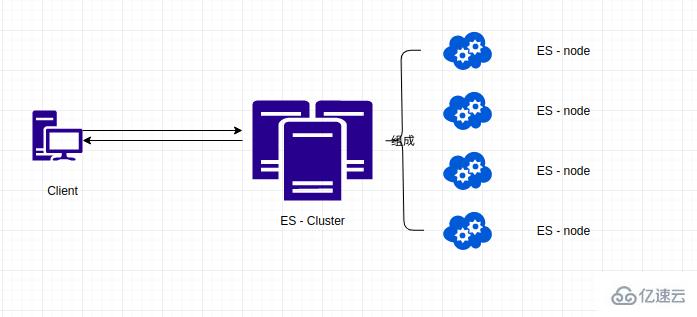
Elasticsearch 集群有多個節點組成,形成分布式集群。那么,什么是節點呢?
節點(Node),就是一個 Elasticsearch 應用實例。大家都知道 Elasticsearch 源代碼是 Java 寫的,那么節點就是一個 Java 進程。
所以類似 Spring 應用一樣,一臺服務器或者本機可以運行多個節點,只要對應的端口不同即可。但生產服務器中,一般一臺服務器運行一個 Elasticsearch 節點。還有需要注意:
Elasticsearch 都會有 name ,通過 -E node.name=node01 指定或者配置文件中配置
每個節點啟動成功,都會分配對應得一個 UID ,保存在 data 目錄
可以通過命令 _cluster/health 查看集群的健康狀態,如下:
Green 主分片與副本分片都正常
Yellow 主分片正常,副本分片不正常
Red 有主分片不正常,可能某個分片容量超過了磁盤大小等
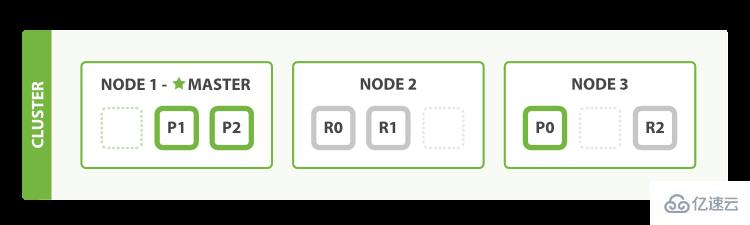
如圖,有主(Master)節點和其他節點。那么節點有多少類型呢?
Master-eligible Node 和 Master Node
Elasticsearch 被啟動后,默認就是 Master-eligible Node。然后通過參與選主過程,可以成為 Master Node。具體選主原理,后續單獨寫一篇文章。Master Node 有什么作用呢?
Master Node 負責同步集群狀態信息:
所有節點信息
所有索引即其 Mapping 和 Setting 信息
所有分片路由信息
只能 Master 節點可以修改信息,是因為這樣就能保證數據得一致性
Data Node 和 Coordinating Node
Data Node,又稱數據節點。用于保存數據,其在數據擴展上起至關重要的作用。
Coordinating Node,是負責接收任何 Client 的請求,包括 REST Client 等。該節點將請求分發到合適的節點,最終把結果匯集到一起。一般來說,每個節點默認起到了 Coordinating Node 的職責。
其他節點類型
還有其他節點類型,雖然不常見,但需要知道:
Hot & Warm Node:不同硬件配置的 Data Node,用來實現冷熱數據節點架構,降低運維部署的成本
Machine Learning Node:負責機器學習的節點
Tribe Node:負責連接不同的集群。支持跨集群搜索 Cross Cluster Search
一般在開發環境中,設置單一的角色節點:
master node:通過 node.master 配置,默認 true
data node:通過 node.data 配置,默認 true
ingest node:通過 node.ingest 配置,默認 true
coordinating node:默認每個節點都是 coordinating 節點,設置其他類型全部為 false。
machine learning:通過 node.ml 配置,默認 true,需要通過 x-pack 開啟。
同樣看這個圖,3 個節點分別為 Node1、Node2、Node3。并且 Node3 上面有一個主分片 P0 和一個副本 R2。那什么是主分片呢?
主分片,用來解決數據水平擴展的問題。比如上圖這個解決可以將數據分布到所有節點上:
節點上可以有主分片,也可以沒有主分片
主分片在索引創建的時候確定,后續不允許修改。除非 Reindex 操作進行修改
副本,用來備份數據,提高數據的高可用性。副本分片是主分片的拷貝
副本分片數,可以動態調整
增加副本數,可以一定程度上提高服務讀取的吞吐和可用性
如何查看 Elasticsearch 集群的分片配置呢?可以從 settings 從看出:
number_of_shards 主分片數
number_of_replicas 副本分片數
{
"my_index": {
"settings": {
"index": {
"number_of_shards": "8",
"number_of_replicas": "1" }
}
}
}實戰建議:對生產環境中,分片設置很重要,需要最好容量評估與規劃
根據數據容量評估分配數,設置過小,后續無法水平擴展;單分片數據量太大,也容易導致數據分片耗時嚴重
分片數設置如果太大,會導致資源浪費,性能降低;同時也會影響搜索結果打分和搜索準確性
索引評估,每個索引下面的單分片數不用太大。如何評估呢?比如這個索引 100 G 數據量,那設置 10 個分片,平均每個分片數據量就是 10G 。每個分片 10 G 數據量這么大,耗時肯定嚴重。所以根據評估的數據量合理安排分片數即可。如果需要調整主分片數,那么需要進行 reindex 等遷索引操作。
比如知道了搜索性能場景,例如多少數據量,多大的寫入,是寫為主還是查詢為主等等,才可以確定:
磁盤,推薦 SSD,JVM最大 Xmx 不要超過30G。副本分片至少設置為1。主分片,單個存儲不要超過 30 GB,按照這個你推算出分片數,進行設定。
集群中磁盤快滿的時候,你再增加機器,確實可能導致新建的索引全部分配到新節點上去的可能性。最終導致數據分配不均。所以要記得監控集群,到70%就需要考慮刪除數據或是增加節點可以設置最大分片數緩解這個問題。
分片的尺寸如果過大,確實也沒有快速恢復的辦法,所以盡量保證分片的size在40G以下。
感謝各位的閱讀,以上就是“Elasticsearch節點、集群、分片及副本是什么”的內容了,經過本文的學習后,相信大家對Elasticsearch節點、集群、分片及副本是什么這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





