溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“如何使用AWK對文本進行過濾”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“如何使用AWK對文本進行過濾”吧!

正則表達式可以定義為代表若干個字符序列的字符串。它最重要的功能之一就是它允許你過濾一條命令或一個文件的輸出、編輯文本或配置文件的一部分等等。
正則表達式由以下內容組合而成:
普通字符,例如空格、下劃線、A-Z、a-z、0-9。
可以擴展為普通字符的
元字符
它們包括:
你必須使用類似 awk 這樣的文本過濾工具來過濾文本。你還可以把 awk 自身當作一個編程語言。但由于這個指南的適用范圍是關于使用 awk 的,我會按照一個簡單的命令行過濾工具來介紹它。
# awk 'script' filename
此處 ‘script’ 是一個由 awk 可以理解并應用于 filename 的命令集合。
它通過讀取文件中的給定行,復制該行的內容并在該行上執行腳本的方式工作。這個過程會在該文件中的所有行上重復。
該腳本 ‘script’ 中內容的格式是 ‘/pattern/ action’,其中 pattern 是一個正則表達式,而 action 是當 awk 在該行中找到此模式時應當執行的動作。
在下面的例子中,我們將聚焦于之前討論過的元字符。
一個使用 awk 的簡單示例:
下面的例子打印文件 /etc/hosts 中的所有行,因為沒有指定任何的模式。
# awk '//{print}' /etc/hosts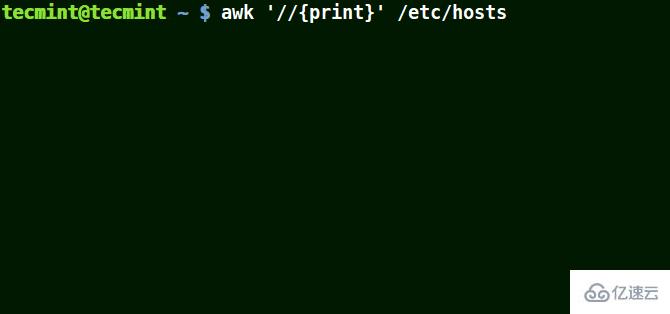
awk 打印文件中的所有行
結合模式使用 awk
在下面的示例中,指定了模式 localhost,因此 awk 將匹配文件 /etc/hosts 中有 localhost 的那些行。
# awk '/localhost/{print}' /etc/hosts
awk 打印文件中匹配模式的行
在 awk 模式中使用通配符 (.)
在下面的例子中,符號 (.) 將匹配包含 loc、localhost、localnet 的字符串。
這里的正則表達式的意思是匹配 l一個字符c。
# awk '/l.c/{print}' /etc/hosts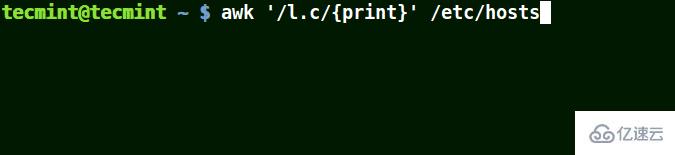
使用 awk 打印文件中匹配模式的字符串
在 awk 模式中使用字符 (*)
在下面的例子中,將匹配包含 localhost、localnet、lines, capable 的字符串。
# awk '/l*c/{print}' /etc/localhost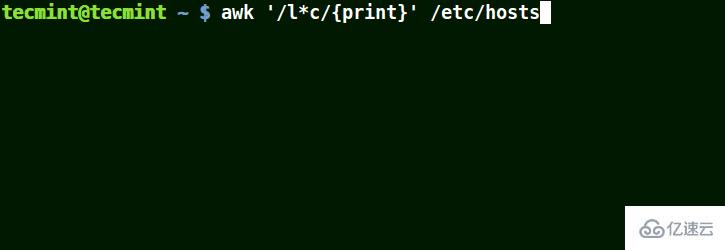
使用 awk 匹配文件中的字符串
你可能也意識到 (*) 將會嘗試匹配它可能檢測到的最長的匹配。
讓我們看一看可以證明這一點的例子,正則表達式 t*t 的意思是在下面的行中匹配以 t 開始和 t 結束的字符串:
this is tecmint, where you get the best good tutorials, how to's, guides, tecmint.
當你使用模式 /t*t/ 時,會得到如下可能的結果:
this is t this is tecmint this is tecmint, where you get t this is tecmint, where you get the best good t this is tecmint, where you get the best good tutorials, how t this is tecmint, where you get the best good tutorials, how tos, guides, t this is tecmint, where you get the best good tutorials, how tos, guides, tecmint
在 /tt/ 中的通配符 () 將使得 awk 選擇匹配的最后一項:
this is tecmint, where you get the best good tutorials, how to's, guides, tecmint
結合集合 [ character(s) ] 使用 awk
以集合 [al1] 為例,awk 將匹配文件 /etc/hosts 中所有包含字符 a 或 l 或 1 的字符串。
# awk '/[al1]/{print}' /etc/hosts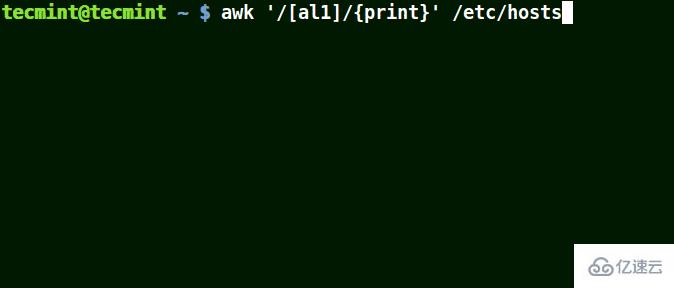
使用 awk 打印文件中匹配的字符
下一個例子匹配以 K 或 k 開始頭,后面跟著一個 T 的字符串:
# awk '/[Kk]T/{print}' /etc/hosts
使用 awk 打印文件中匹配的字符
以范圍的方式指定字符
awk 所能理解的字符:
讓我們看看下面的例子:
# awk '/[0-9]/{print}' /etc/hosts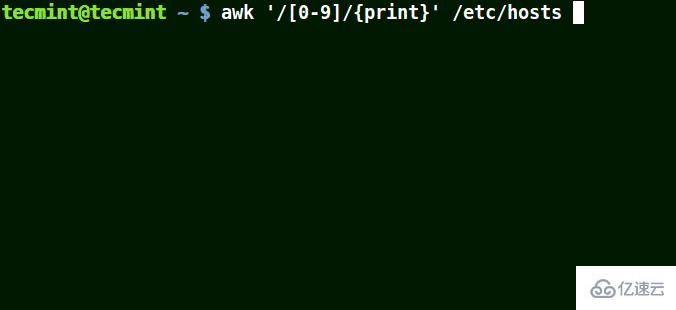
使用 awk 打印文件中匹配的數字
在上面的例子中,文件 /etc/hosts 中的所有行都至少包含一個單獨的數字 [0-9]。
結合元字符 (^) 使用 awk
在下面的例子中,它匹配所有以給定模式開頭的行:
# awk '/^fe/{print}' /etc/hosts# awk '/^ff/{print}' /etc/hosts
使用 awk 打印與模式匹配的行
結合元字符 ($) 使用 awk
它將匹配所有以給定模式結尾的行:
# awk '/ab$/{print}' /etc/hosts# awk '/ost$/{print}' /etc/hosts# awk '/rs$/{print}' /etc/hosts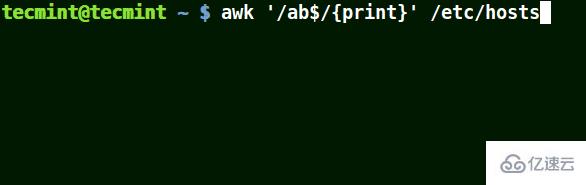
使用 awk 打印與模式匹配的字符串
結合轉義字符 (/) 使用 awk
它允許你將該轉義字符后面的字符作為文字,即理解為其字面的意思。
在下面的例子中,第一個命令打印出文件中的所有行,第二個命令中我想匹配具有 $25.00 的一行,但我并未使用轉義字符,因而沒有打印出任何內容。
第三個命令是正確的,因為一個這里使用了一個轉義字符以轉義 ,以將其識別為‘(而非元字符)。
# awk '//{print}' deals.txt# awk '/$25.00/{print}' deals.txt# awk '//$25.00/{print}' deals.txt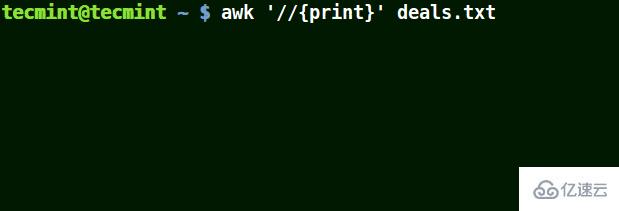
結合轉義字符使用 awk
到此,相信大家對“如何使用AWK對文本進行過濾”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





