溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Flume是一個分布式的、可靠的、可用的服務,用于從許多不同的源上有效地搜集、匯總、移動大量數據日志到一個集中式的數據存儲中。并且它是一個簡單的和靈活的基于流的數據流架構。它具有魯棒性和容錯機制以及故障轉移和恢復的機制。對于分析的應用中它使用一個簡單的可擴展的數據模型。Flume傳輸的數據可以是網絡,媒體等產生。
Apache Flume是Apache軟件基金會的一個頂級項目。
源-Source,接收器-Sink,通道-Channel
flume是cloudera公司的一款高性能、高可能的分布式日志收集系統。
flume的核心是把數據從數據源收集過來,再送到目的地。為了保證輸送一定成功,在送到目的地之前,會先緩存數據,待數據真正到達目的地后,刪除自己緩存的數據。
flume傳輸的數據的基本單位是event,如果是文本文件,通常是一行記錄,這也是事務的基本單位。
flume運行的核心是agent。它是一個完整的數據收集工具,含有三個核心組件,分別是source、channel、sink。通過這些組件,event可以從一個地方流向另一個地方
Apache Flume系統需求:
Java Runtime Environment - Java 1.6 or later (Java 1.7 Recommended)
Memory - Sufficient memory for configurations used by sources, channels or sinks
Disk Space - Sufficient disk space for configurations used by channels or sinks
Directory Permissions - Read/Write permissions for directories used by agent
數據流
Flume事件被定義為一個單位的數據流量有一個字節的有效載荷和一個可選字符串屬性。Flume代理(JVM)的過程中,承載組件,通過這些事件流從外部源的下一個目的地(跳)。
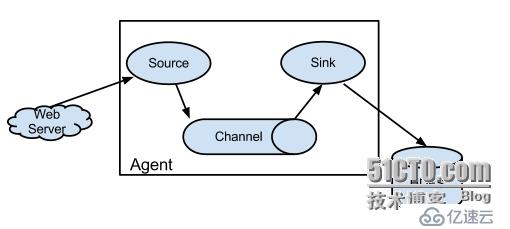
多agent模式:

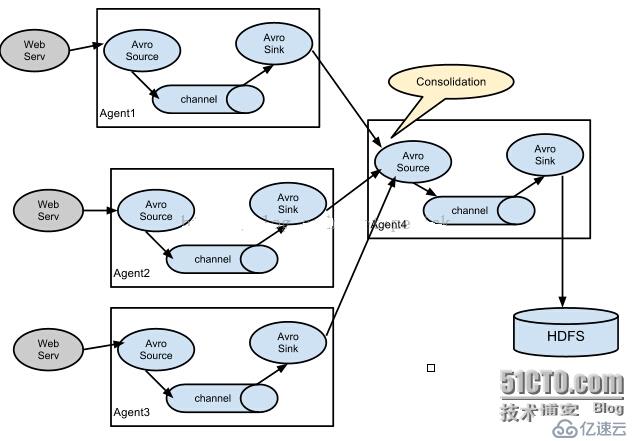
一對多路輸出模型:

source:
Client端操作消費數據的來源,Flume支持Avro,log4j,syslog和http post(body為json格式)。可以讓應用程序同已有的Source直接打交道,如AvroSource,SyslogTcpSource。也可以寫一個Source,以IPC或RPC的方式接入自己的應用,Avro和Thrift都可以(分別有NettyAvroRpcClient和ThriftRpcClient實現了RpcClient接口),其中Avro是默認的RPC協議。具體代碼級別的Client端數據接入,可以參考官方手冊。
對現有程序改動最小的使用方式是使用是直接讀取程序原來記錄的日志文件,基本可以實現無縫接入,不需要對現有程序進行任何改動。
對于直接讀取文件Source,有兩種方式:
ExecSource:以運行Linux命令的方式,持續的輸出最新的數據,如tail -F 文件名指令,在這種方式下,取的文件名必須是指定的。 ExecSource可以實現對日志的實時收集,但是存在Flume不運行或者指令執行出錯時,將無法收集到日志數據,無法保證日志數據的完整性。
SpoolSource:監測配置的目錄下新增的文件,并將文件中的數據讀取出來。需要注意兩點:拷貝到spool目錄下的文件不可以再打開編輯;spool目錄下不可包含相應的子目錄。SpoolSource雖然無法實現實時的收集數據,但是可以使用以分鐘的方式分割文件,趨近于實時。如果應用無法實現以分鐘切割日志文件的話,可以兩種收集方式結合使用。 在實際使用的過程中,可以結合log4j使用,使用log4j的時候,將log4j的文件分割機制設為1分鐘一次,將文件拷貝到spool的監控目錄。log4j有一個TimeRolling的插件,可以把log4j分割的文件到spool目錄。基本實現了實時的監控。Flume在傳完文件之后,將會修改文件的后綴,變為.COMPLETED(后綴也可以在配置文件中靈活指定)
channel:
Channel有多種方式:有MemoryChannel,JDBC Channel,MemoryRecoverChannel,FileChannel。
MemoryChannel可以實現高速的吞吐,但是無法保證數據的完整性。
MemoryRecoverChannel在官方文檔的建議上已經建義使用FileChannel來替換。
FileChannel保證數據的完整性與一致性。在具體配置不現的FileChannel時,建議FileChannel設置的目錄和程序日志文件保存的目錄設成不同的磁盤,以便提高效率。
sink:
Sink在設置存儲數據時,可以向文件系統、數據庫、hadoop存數據,在日志數據較少時,可以將數據存儲在文件系中,并且設定一定的時間間隔保存數據。在日志數據較多時,可以將相應的日志數據存儲到Hadoop中,便于日后進行相應的數據分析。
一個web服務器的產生的事件由 Flume源消耗。外部源發送事件發送到Flume中,會帶著一個識別的格式。例如: 例如:一個Avro Flume源可以用來接收從Avro clients 或其他flume代理從Avro link發送事件。當一個Flume 源接收一個事件,他會存儲到一個活多個channels中,這些channel會一直保存著event,直到被Flume sink消費處理掉,例如JDBC Channel作為一個例子-它使用一個文件系統支持嵌入式數據庫,sink從channel中移除事件,同時放入到一個外部的倉庫,比如HDFS,或者流轉到下一個Flume source 源,source和sink在agent中是以異步運行方式運行事件。
復雜數據流:
Flume到達最終目的地之前,允許用戶建立多跳流活動,通過多個代理。對于失敗的每一跳它還允許fan-in和fan-out flows,內容路由和備份路由失敗(故障轉移)。
可靠性:
Flume的核心是把數據從數據源收集過來,再送到目的地。為了保證輸送一定成功,在送到目的地之前,會先緩存數據,待數據真正到達目的地后,刪除自己緩存的數據。
Flume使用事務性的方式保證傳送Event整個過程的可靠性。Sink必須在Event被存入Channel后,或者,已經被傳達到下一站agent里,又或者,已經被存入外部數據目的地之后,才能把Event從Channel中remove掉。這樣數據流里的event無論是在一個agent里還是多個agent之間流轉,都能保證可靠,因為以上的事務保證了event會被成功存儲起來。而Channel的多種實現在可恢復性上有不同的保證。也保證了event不同程度的可靠性。比如Flume支持在本地保存一份文件channel作為備份,而memory channel將event存在內存queue里,速度快,但丟失的話無法恢復。
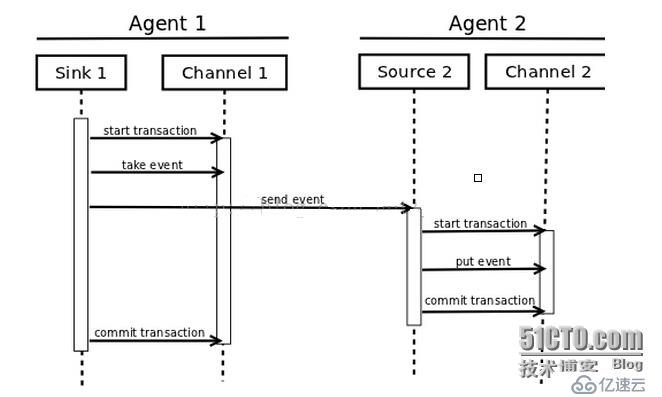
具體看一下Transaction。Source和Sink封裝了Channel提供的對Event的事務存、取接口,下圖為一個transaction過程:
一
一個Channel的實現里會包括一個transaction的實現,每個與channel打交道的source和sink都得帶有一個transaction對象。下面的例子中可以看到一個Event的狀態和變化會在一次transation中完成。transaction的狀態也對應了時序圖中的各個狀態。
故障恢復:
在每一個agent的channel中的event都可以在失敗中恢復。Flume支持持久文件channel(本地文件系統必須支持)內存channel僅僅將event存儲在內存隊列中,這樣內存中的event一旦丟失就不能恢復。
配置一個代理(agent)
Flume代理配置存儲在本地配置文件。這是一個文本文件格式如下Java屬性文件格式。在相同的配置文件,可以指定一個或多個代理的配置。配置文件包括每個源,接收器和代理渠道的性質和它們連接在一起,形成數據流。
配置單個組件
流中每個組件(源,接收器或通道)的名稱,類型,和一組特定的類型和實例的屬性。例如 Avro源需要一個主機名(或IP地址)和接收數據的端口號。一個內存通道可以有最大隊列大小(“能力”),HDFS的散熱器需要知道文件系統的URI,路徑創建文件,文件的旋轉頻率(“hdfs.rollInterval”)等,所有這些組件的屬性需要設置在托管 Flume 代理的屬性文件。
組合組件(Wiring the pieces together)
代理需要知道什么加載各個組件以及它們是如何連接,以構成的流動。這是通過列出的源,匯和代理渠道的名稱,然后指定每個接收器和源的連接通道。例如,代理到HDFS flume HDFS cluster1中通過JDBC JDBC通道通道流動稱為avroWeb Avro 源的事件。該配置文件將包含這些組件和JDBC通道為avroWeb源和HDFS cluster1中匯作為共享信道的名稱。
啟動代理(starting an agent)
代理人是開始使用shell腳本稱為flume-NG是位于flume分布在bin目錄。你需要在命令行上指定的代理的名稱,config目錄,配置文件:
$ bin/flume-ng agent -n $agent_name -c conf -f conf/flume-conf.properties.template
現在,代理將開始運行的源和匯的配置在給定的屬性文件。
A simple example
在這里,我們舉一個例子,配置文件,描述一個單節點的Flume部署。這種配置可以讓用戶生成的事件和隨后輸出到控制臺。
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
這個配置定義了一個單一的代理,稱為agent1。 agent1監聽44444端口,通道緩存在內存中事件數據,事件數據記錄到控制臺和一個接收器上的數據源。配置文件名的各個組成部分,然后介紹了他們的類型和配置參數。一個給定的配置文件可能會定義多個命名的代理人;一個給定的Flume進程啟動時傳遞一個標志,告訴它的具名代理體現。
結合此配置文件,我們啟動Flume按如下參數:
$ bin/flume-ng agent --conf conf --conf-file example.conf --name a1 -Dflume.root.logger=INFO,console
請注意,在完整部署,我們通常會包括一個選項: - CONF=<conf-dir>。 <conf-dir>目錄將包括一個shell腳本flume-env.sh和內置的Log4j屬性文件。在這個例子中,我們使用一個Java選項強制flume登錄到控制臺
我們可以從一個單獨的終端,然后telnet端口44444和發送flume事件:
$ telnet localhost 44444Trying 127.0.0.1...Connected to localhost.localdomain (127.0.0.1).Escape character is '^]'.Hello world! <ENTER>OK
他原來的flume終端輸出日志信息的事件。
12/06/19 15:32:19 INFO source.NetcatSource: Source starting
12/06/19 15:32:19 INFO source.NetcatSource: Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444]
12/06/19 15:32:34 INFO sink.LoggerSink: Event: { headers:{} body: 48 65 6C 6C 6F 20 77 6F 72 6C 64 21 0D Hello world!. }
至此,你已經成功地配置和部署了一個flume代理!隨后的章節涵蓋更詳細的代理配置。
數據獲取
flume支持從從外部數據源獲取數據的機制。
RPC
在flume中 ,Avro客戶端使用AVRO RPC機制可以發送一個給定的文件 Avro 源:
$ bin/flume-ng avro-client -H localhost -p 41414 -F /usr/logs/log.10
上面的命令將發送的/ usr/logs/log.10的內容到 flume源監聽端
Executing commands
還有一個exec執行一個給定的命令獲得輸出的源。一個單一的輸出,即“line”。回車('\ R')或換行符('\ N'),或兩者一起的文本。
注:Flume不支持tail做為一個源,不過可以通過exec tail
Network streams
Flume支持以下的機制,從流行的日志流類型讀取數據
Avro
Syslog
Netcat
定義流
在一個單一的代理定義的流,你需要通過一個通道的來源和接收器鏈接。你需要列出源,接收器和通道,為給定的代理,然后指向源和接收器及通道。一個源的實例可以指定多個通道,但只能指定一個接收器實例通道。格式如下:
# list the sources, sinks and channels for the agent
<Agent>.sources = <Source>
<Agent>.sinks = <Sink>
<Agent>.channels = <Channel1> <Channel2>
# set channel for source
<Agent>.sources.<Source>.channels = <Channel1> <Channel2> ...
# set channel for sink
<Agent>.sinks.<Sink>.channel = <Channel1>
例如一個代理名為weblog-agent,外部通過avro客戶端,并且發送數據通過內存通道給hdfs。在配置文件weblog.config的可能看起來像這樣:
# list the sources, sinks and channels for the agent
agent_foo.sources = avro-appserver-src-1
agent_foo.sinks = hdfs-sink-1
agent_foo.channels = mem-channel-1
# set channel for source
agent_foo.sources.avro-appserver-src-1.channels = mem-channel-1
# set channel for sink
agent_foo.sinks.hdfs-sink-1.channel = mem-channel-1
這將使事件流從avro-AppSrv-source到hdfs-Cluster1-sink通過內存通道mem-channel-1。當代理開始weblog.config作為其配置文件,它會實例化流。
配置單個組件
定義流之后,你需要設置每個源,接收器和通道的屬性。可以分別設定組件的屬性值。
# properties for sources
<Agent>.sources.<Source>.<someProperty> = <someValue>
# properties for channels
<Agent>.channel.<Channel>.<someProperty> = <someValue>
# properties for sinks
<Agent>.sources.<Sink>.<someProperty> = <someValue>
“type”屬性必須為每個組件設置,以了解它需要什么樣的對象。每個源,接收器和通道類型有其自己的一套,它所需的性能,以實現預期的功能。所有這些,必須根據需要設置。在前面的例子中,我們拿到從hdfs-Cluster1-sink中的流到HDFS,通過內存通道mem-channel-1的avro-AppSrv-source源。下面是一個例子,顯示了這些組件的配置。
agent_foo.sources = avro-AppSrv-source
agent_foo.sinks = hdfs-Cluster1-sink
agent_foo.channels = mem-channel-1
# set channel for sources, sinks
# properties of avro-AppSrv-source
agent_foo.sources.avro-AppSrv-source.type = avro
agent_foo.sources.avro-AppSrv-source.bind = localhost
agent_foo.sources.avro-AppSrv-source.port = 10000
# properties of mem-channel-1
agent_foo.channels.mem-channel-1.type = memory
agent_foo.channels.mem-channel-1.capacity = 1000
agent_foo.channels.mem-channel-1.transactionCapacity = 100
# properties of hdfs-Cluster1-sink
agent_foo.sinks.hdfs-Cluster1-sink.type = hdfs
agent_foo.sinks.hdfs-Cluster1-sink.hdfs.path = hdfs://namenode/flume/webdata
#...
在一個代理中添加多個流
單個Flume代理可以包含幾個獨立的流。你可以在一個配置文件中列出多個源,接收器和通道。這些組件可以連接形成多個流。
# list the sources, sinks and channels for the agent
<Agent>.sources = <Source1> <Source2>
<Agent>.sinks = <Sink1> <Sink2>
<Agent>.channels = <Channel1> <Channel2>
那么你就可以連接源和接收器到其相應的通道,設置兩個不同的流。例如,如果您需要設置一個weblog代理兩個流,一個從外部Avro客戶端到HDFS,另外一個是tail的輸出到Avro接收器,然后在這里是做一個配置:
# list the sources, sinks and channels in the agent
agent_foo.sources = avro-AppSrv-source1 exec-tail-source2
agent_foo.sinks = hdfs-Cluster1-sink1 avro-forward-sink2
agent_foo.channels = mem-channel-1 file-channel-2
# flow #1 configuration
agent_foo.sources.avro-AppSrv-source1.channels = mem-channel-1
agent_foo.sinks.hdfs-Cluster1-sink1.channel = mem-channel-1
# flow #2 configuration
agent_foo.sources.exec-tail-source2.channels = file-channel-2
agent_foo.sinks.avro-forward-sink2.channel = file-channel-2
配置多代理流程
設置一個多層的流,你需要有一個指向下一跳avro源的第一跳的avro 接收器。這將導致第一Flume代理轉發事件到下一個Flume代理。例如,如果您定期發送的文件,每個事件(1文件)AVRO客戶端使用本地Flume代理,那么這個當地的代理可以轉發到另一個有存儲的代理。
Weblog agent config:
list sources, sinks and channels in the agent
agent_foo.sources = avro-AppSrv-source
agent_foo.sinks = avro-forward-sink
agent_foo.channels = file-channel
# define the flow
agent_foo.sources.avro-AppSrv-source.channels = file-channel
agent_foo.sinks.avro-forward-sink.channel = file-channel
# avro sink properties
agent_foo.sources.avro-forward-sink.type = avro
agent_foo.sources.avro-forward-sink.hostname = 10.1.1.100
agent_foo.sources.avro-forward-sink.port = 10000
# configure other pieces
#...
HDFS agent config:
# list sources, sinks and channels in the agent
agent_foo.sources = avro-collection-source
agent_foo.sinks = hdfs-sink
agent_foo.channels = mem-channel
# define the flow
agent_foo.sources.avro-collection-source.channels = mem-channel
agent_foo.sinks.hdfs-sink.channel = mem-channel
# avro sink properties
agent_foo.sources.avro-collection-source.type = avro
agent_foo.sources.avro-collection-source.bind = 10.1.1.100
agent_foo.sources.avro-collection-source.port = 10000
# configure other pieces
#...
這里我們連接從weblog-agent的avro-forward-sink 到hdfs-agent的avro-collection-source收集源。最終結果從外部源的appserver最終存儲在HDFS的事件。
Fan out flow
Flume支持Fan out流從一個源到多個通道。有兩種模式的Fan out,分別是復制和復用。在復制的情況下,流的事件被發送到所有的配置通道。在復用的情況下,事件被發送到可用的渠道中的一個子集。Fan out流需要指定源和Fan out通道的規則。這是通過添加一個通道“選擇”,可以復制或復。再進一步指定選擇的規則,如果它是一個多路。如果你不指定一個選擇,則默認情況下它復制
# List the sources, sinks and channels for the agent
<Agent>.sources = <Source1>
<Agent>.sinks = <Sink1> <Sink2>
<Agent>.channels = <Channel1> <Channel2>
# set list of channels for source (separated by space)
<Agent>.sources.<Source1>.channels = <Channel1> <Channel2>
# set channel for sinks
<Agent>.sinks.<Sink1>.channel = <Channel1>
<Agent>.sinks.<Sink2>.channel = <Channel2>
<Agent>.sources.<Source1>.selector.type = replicating
復用的選擇集的屬性進一步分叉。這需要指定一個事件屬性映射到一組通道。選擇配置屬性中的每個事件頭檢查。如果指定的值相匹配,那么該事件被發送到所有的通道映射到該值。如果沒有匹配,那么該事件被發送到設置為默認配置的通道。
# Mapping for multiplexing selector
<Agent>.sources.<Source1>.selector.type = multiplexing
<Agent>.sources.<Source1>.selector.header = <someHeader>
<Agent>.sources.<Source1>.selector.mapping.<Value1> = <Channel1>
<Agent>.sources.<Source1>.selector.mapping.<Value2> = <Channel1> <Channel2>
<Agent>.sources.<Source1>.selector.mapping.<Value3> = <Channel2>
#...
<Agent>.sources.<Source1>.selector.default = <Channel2>
映射允許每個值通道可以重疊。默認值可以包含任意數量的通道。下面的示例中有一個單一的流復用兩條路徑。代理有一個單一的avro源和連接道兩個接收器的兩個通道。
# list the sources, sinks and channels in the agent
agent_foo.sources = avro-AppSrv-source1
agent_foo.sinks = hdfs-Cluster1-sink1 avro-forward-sink2
agent_foo.channels = mem-channel-1 file-channel-2
# set channels for source
agent_foo.sources.avro-AppSrv-source1.channels = mem-channel-1 file-channel-2
# set channel for sinks
agent_foo.sinks.hdfs-Cluster1-sink1.channel = mem-channel-1
agent_foo.sinks.avro-forward-sink2.channel = file-channel-2
# channel selector configuration
agent_foo.sources.avro-AppSrv-source1.selector.type = multiplexing
agent_foo.sources.avro-AppSrv-source1.selector.header = State
agent_foo.sources.avro-AppSrv-source1.selector.mapping.CA = mem-channel-1
agent_foo.sources.avro-AppSrv-source1.selector.mapping.AZ = file-channel-2
agent_foo.sources.avro-AppSrv-source1.selector.mapping.NY = mem-channel-1 file-channel-2
agent_foo.sources.avro-AppSrv-source1.selector.default = mem-channel-1
“State”作為Header的選擇檢查。如果值是“CA”,然后將其發送到mem-channel-1,如果它的“AZ”的,那么jdbc-channel-2,如果它的“NY”那么發到這兩個。如果“State”頭未設置或不匹配的任何三個,然后去默認的mem-channel-1通道。
Flume Sources
Avro Source
Avro端口監聽并接收來自外部的Avro客戶流的事件。當內置AvroSink另一個(前跳)Flume代理,它可以創建分層集合配對拓撲。
Example for agent named agent_foo:
a1.sources = r1a1.channels = c1a1.sources.r1.type = org.apache.flume.source.avroLegacy.AvroLegacySourcea1.sources.r1.host = 0.0.0.0a1.sources.r1.bind = 6666a1.sources.r1.channels = c1
Exec Source
此源啟動運行一個給定的Unix命令,預計這一過程中不斷產生標準輸出(stderr被簡單地丟棄,除非logStdErr= TRUE)上的數據。如果因任何原因的進程退出時,源也退出,并不會產生任何進一步的數據。
備注: 在ExecSource不能保證,如果有一個失敗的放入到通道的事件,客戶也知道。在這種情況下,數據將丟失。
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /var/log/secure
a1.sources.r1.channels = c1
shell:
agent_foo.sources.tailsource-1.type = exec
agent_foo.sources.tailsource-1.shell = /bin/bash -c
agent_foo.sources.tailsource-1.command = for i in /path/*.txt; do cat $i; done
JMS source:
Required properties are in bold.
Converter:
Example for agent named a1:
a1.sources = r1a1.channels = c1a1.sources.r1.type = jmsa1.sources.r1.channels = c1a1.sources.r1.initialContextFactory = org.apache.activemq.jndi.ActiveMQInitialContextFactorya1.sources.r1.connectionFactory = GenericConnectionFactorya1.sources.r1.providerURL = tcp://mqserver:61616a1.sources.r1.destinationName = BUSINESS_DATAa1.sources.r1.destinationType = QUEUE
Spooling Directory Source
Example for an agent named agent-1:
agent-1.channels = ch-1
agent-1.sources = src-1
agent-1.sources.src-1.type = spooldir
agent-1.sources.src-1.channels = ch-1
agent-1.sources.src-1.spoolDir = /var/log/apache/flumeSpool
agent-1.sources.src-1.fileHeader = true
書寫agent配置
使用flume的核心是如何配置agent文件。agent的配置是一個普通文本文件,使用鍵值對形式存儲配置信息,可以設置多個agent信息。配置的內容包括source、channel、sink等。組件source、channel、sink都有名稱、類型和很多個性化的屬性配置。
配置文件應該這么寫
# list the sources, sinks and channels for the agent
<Agent>.sources = <Source>
<Agent>.sinks = <Sink>
<Agent>.channels = <Channel1> <Channel2>
# set channel for source
<Agent>.sources.<Source>.channels = <Channel1> <Channel2> ...
# set channel for sink
<Agent>.sinks.<Sink>.channel = <Channel1>
# properties for sources
<Agent>.sources.<Source>.<someProperty> = <someValue>
# properties for channels
<Agent>.channel.<Channel>.<someProperty> = <someValue>
# properties for sinks
<Agent>.sources.<Sink>.<someProperty> = <someValue>
# 下面是示例
#下面的agent1是代理名稱,對應有source,名稱是src1,;有一個sink,名稱是sink1;有一個channel,名稱是ch2.
gent1.sources = src1
agent1.sinks = sink1
agent1.channels = ch3
# 配置目錄 source,監控目錄(必須存在)的變化,要求文件名必須唯一,否則flume報錯
agent1.sources.src1.type = spooldir
agent1.sources.src1.channels = ch3
agent1.sources.src1.spoolDir = /root/hmbbs
agent1.sources.src1.fileHeader = false
agent1.sources.src1.interceptors = i1
agent1.sources.src1.interceptors.i1.type = timestamp
# 配置內存 channel
agent1.channels.ch2.type = memory
agent1.channels.ch2.capacity = 1000
agent1.channels.ch2.transactionCapacity = 1000
agent1.channels.ch2.byteCapacityBufferPercentage = 20
agent1.channels.ch2.byteCapacity = 800000
# 配置文件 channel
agent1.channels.ch3.type = file
agent1.channels.ch3.checkpointDir = /root/flumechannel/checkpoint
agent1.channels.ch3.dataDirs = /root/flumechannel/data
# 配置hdfs sink
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.channel = ch3
agent1.sinks.sink1.hdfs.path = hdfs://hadoop0:9000/flume/%Y-%m-%d/
agent1.sinks.sink1.hdfs.rollInterval=1
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat = Text
# 配置hbase sink
#配置hbase sink2
agent1.sinks.sink2.type = hbase
agent1.sinks.sink2.channel = channel1
agent1.sinks.sink2.table = hmbbs
agent1.sinks.sink2.columnFamily = cf
agent1.sinks.sink2.serializer = flume.HmbbsHbaseEventSerializer
agent1.sinks.sink2.serializer.suffix = timestamp
agent1.sinks.sink2.serializer = org.apache.flume.sink.hbase.SimpleHbaseEventSerializer
5.啟動代理的腳本是flume-ng agent,需要指定agent name、配置目錄、配置文件
-n 指定agent名稱
-c 指定配置文件目錄
-f 指定配置文件
-Dflume.root.logger=DEBUG,console
因此完整的啟動命令應該這么寫
bin/flume-ng agent –n agent1 –c conf –f conf/example –Dflume.root.logger=DEBUG,console
啟動成功后,可以向目錄/root/hmbbs中放入文件,flume會感知到新文件,然后上傳到hdfs的/flume目錄下。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





