溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Java的深拷貝和淺拷貝怎么實現”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“Java的深拷貝和淺拷貝怎么實現”文章能幫助大家解決問題。
關于Java的深拷貝和淺拷貝,簡單來說就是創建一個和已知對象一模一樣的對象。可能日常編碼過程中用的不多,但是這是一個面試經常會問的問題,而且了解深拷貝和淺拷貝的原理,對于Java中的所謂值傳遞或者引用傳遞將會有更深的理解。
這是最常用的一種方式,通過 new 關鍵字調用類的有參或無參構造方法來創建對象。比如 Object obj = new Object();
這種默認是調用類的無參構造方法創建對象。比如Person p2 = (Person) Class.forName("com.ys.test.Person").newInstance();
這和第二種方法類時,都是通過反射來實現。通過java.lang.relect.Constructor 類的newInstance() 方法指定某個構造器來創建對象。
Person p3 = (Person) Person.class.getConstructors()[0].newInstance();
實際上第二種方法利用 Class 的 newInstance() 方法創建對象,其內部調用還是 Constructor 的 newInstance() 方法。
Clone 是 Object 類中的一個方法,通過 對象A.clone() 方法會創建一個內容和對象 A 一模一樣的對象 B,clone 克隆,顧名思義就是創建一個一模一樣的對象出來。
Person p4 = (Person) p3.clone();
序列化是把堆內存中的 Java 對象數據,通過某種方式把對象存儲到磁盤文件中或者傳遞給其他網絡節點(在網絡上傳輸)。而反序列化則是把磁盤文件中的對象數據或者把網絡節點上的對象數據,恢復成Java對象模型的過程。
具體如何實現可以參考我這篇博文。
本篇博客我們講解的是 Java 的深拷貝和淺拷貝,其實現方式正是通過調用 Object 類的 clone() 方法來完成。在 Object.class 類中,源碼為:
protected native Object clone() throws CloneNotSupportedException;
這是一個用 native 關鍵字修飾的方法,關于native關鍵字有一篇博客專門有介紹,不理解也沒關系,只需要知道用 native 修飾的方法就是告訴操作系統,這個方法我不實現了,讓操作系統去實現。具體怎么實現我們不需要了解,只需要知道 clone方法的作用就是復制對象,產生一個新的對象。那么這個新的對象和原對象是什么關系呢?
這里再給大家普及一個概念,在 Java 中基本類型和引用類型的區別。
在 Java 中數據類型可以分為兩大類:基本類型和引用類型。
基本類型也稱為值類型,分別是字符類型 char,布爾類型 boolean以及數值類型 byte、short、int、long、float、double。
引用類型則包括類、接口、數組、枚舉等。
Java 將內存空間分為堆和棧。基本類型直接在棧中存儲數值,而引用類型是將引用放在棧中,實際存儲的值是放在堆中,通過棧中的引用指向堆中存放的數據。
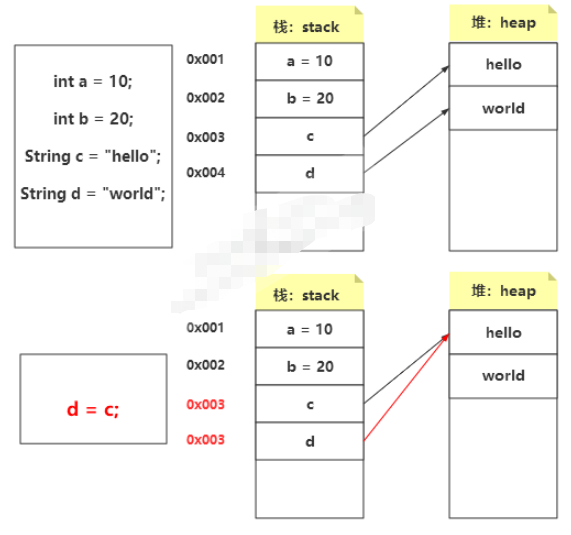
上圖定義的 a 和 b 都是基本類型,其值是直接存放在棧中的;而 c 和 d 是 String 聲明的,這是一個引用類型,引用地址是存放在 棧中,然后指向堆的內存空間。
下面 d = c;這條語句表示將 c 的引用賦值給 d,那么 c 和 d 將指向同一塊堆內存空間。
我們看如下這段代碼:
package com.ys.test;
public class Person implements Cloneable{
public String pname;
public int page;
public Address address;
public Person() {}
public Person(String pname,int page){
this.pname = pname;
this.page = page;
this.address = new Address();
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
public void setAddress(String provices,String city ){
address.setAddress(provices, city);
}
public void display(String name){
System.out.println(name+":"+"pname=" + pname + ", page=" + page +","+ address);
}
public String getPname() {
return pname;
}
public void setPname(String pname) {
this.pname = pname;
}
public int getPage() {
return page;
}
public void setPage(int page) {
this.page = page;
}
}package com.ys.test;
public class Address {
private String provices;
private String city;
public void setAddress(String provices,String city){
this.provices = provices;
this.city = city;
}
@Override
public String toString() {
return "Address [provices=" + provices + ", city=" + city + "]";
}
}這是一個我們要進行賦值的原始類 Person。下面我們產生一個 Person 對象,并調用其 clone 方法復制一個新的對象。
注意:調用對象的 clone 方法,必須要讓類實現Cloneable 接口,并且覆寫 clone 方法。
測試:
@Test
public void testShallowClone() throws Exception{
Person p1 = new Person("zhangsan",21);
p1.setAddress("湖北省", "武漢市");
Person p2 = (Person) p1.clone();
System.out.println("p1:"+p1);
System.out.println("p1.getPname:"+p1.getPname().hashCode());
System.out.println("p2:"+p2);
System.out.println("p2.getPname:"+p2.getPname().hashCode());
p1.display("p1");
p2.display("p2");
p2.setAddress("湖北省", "荊州市");
System.out.println("將復制之后的對象地址修改:");
p1.display("p1");
p2.display("p2");
}打印結果為:
首先看原始類 Person 實現Cloneable 接口,并且覆寫 clone 方法,它還有三個屬性,一個引用類型 String定義的 pname,一個基本類型 int定義的 page,還有一個引用類型 Address ,這是一個自定義類,這個類也包含兩個屬性 pprovices 和 city 。
接著看測試內容,首先我們創建一個Person 類的對象 p1,其pname 為zhangsan,page為21,地址類 Address 兩個屬性為 湖北省和武漢市。接著我們調用 clone() 方法復制另一個對象 p2,接著打印這兩個對象的內容。
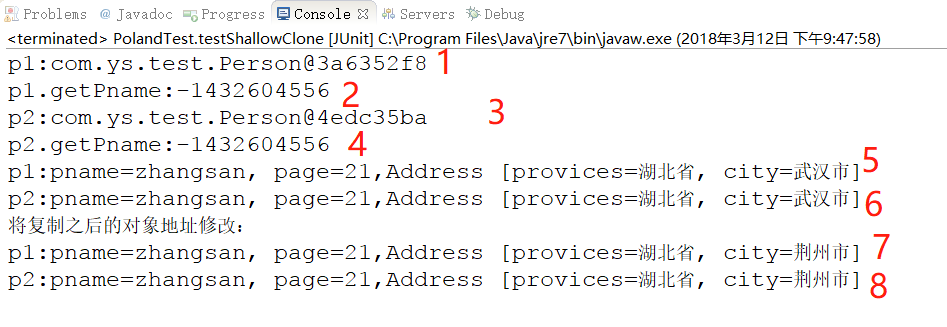
從第 1 行和第 3 行打印結果:
p1:com.ys.test.Person@349319f9
p2:com.ys.test.Person@258e4566
可以看出這是兩個不同的對象。
從第 5 行和第 6 行打印的對象內容看,原對象 p1 和克隆出來的對象 p2 內容完全相同。
代碼中我們只是更改了克隆對象 p2 的屬性 Address 為湖北省荊州市(原對象 p1 是湖北省武漢市) ,但是從第 7 行和第 8 行打印結果來看,原對象 p1 和克隆對象 p2 的 Address 屬性都被修改了。
也就是說對象 Person 的屬性 Address,經過 clone 之后,其實只是復制了其引用,他們指向的還是同一塊堆內存空間,當修改其中一個對象的屬性 Address,另一個也會跟著變化。
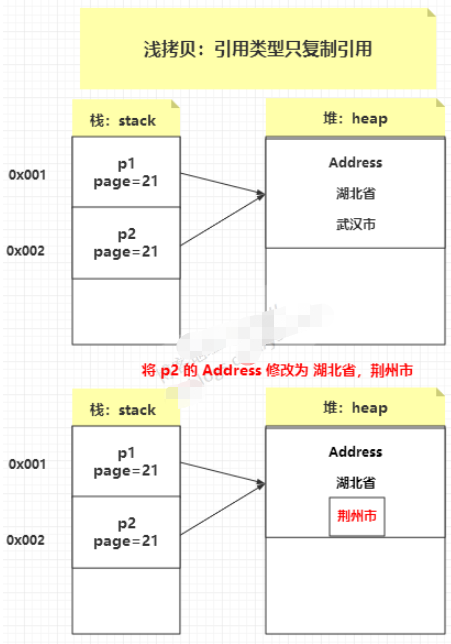
淺拷貝:創建一個新對象,然后將當前對象的非靜態字段復制到該新對象,如果字段是值類型的,那么對該字段執行復制;如果該字段是引用類型的話,則復制引用但不復制引用的對象。因此,原始對象及其副本引用同一個對象。
弄清楚了淺拷貝,那么深拷貝就很容易理解了。
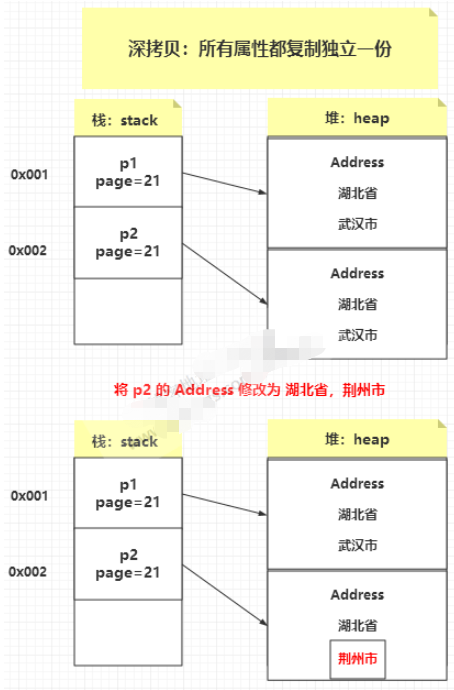
深拷貝:創建一個新對象,然后將當前對象的非靜態字段復制到該新對象,無論該字段是值類型的還是引用類型,都復制獨立的一份。當你修改其中一個對象的任何內容時,都不會影響另一個對象的內容。
那么該如何實現深拷貝呢?Object 類提供的 clone 是只能實現 淺拷貝的。
深拷貝的原理我們知道了,就是要讓原始對象和克隆之后的對象所具有的引用類型屬性不是指向同一塊堆內存,這里有三種實現思路。
既然引用類型不能實現深拷貝,那么我們將每個引用類型都拆分為基本類型,分別進行淺拷貝。比如上面的例子,Person 類有一個引用類型 Address(其實String 也是引用類型,但是String類型有點特殊,后面會詳細講解),我們在 Address 類內部也重寫 clone 方法。如下:
Address.class:
package com.ys.test;
public class Address implements Cloneable{
private String provices;
private String city;
public void setAddress(String provices,String city){
this.provices = provices;
this.city = city;
}
@Override
public String toString() {
return "Address [provices=" + provices + ", city=" + city + "]";
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}Person.class 的 clone() 方法:
@Override
protected Object clone() throws CloneNotSupportedException {
Person p = (Person) super.clone();
p.address = (Address) address.clone();
return p;
}測試還是和上面一樣,我們會發現更改了p2對象的Address屬性,p1 對象的 Address 屬性并沒有變化。
但是這種做法有個弊端,這里我們Person 類只有一個 Address 引用類型,而 Address 類沒有,所以我們只用重寫 Address 類的clone 方法,但是如果 Address 類也存在一個引用類型,那么我們也要重寫其clone 方法,這樣下去,有多少個引用類型,我們就要重寫多少次,如果存在很多引用類型,那么代碼量顯然會很大,所以這種方法不太合適。
序列化是將對象寫到流中便于傳輸,而反序列化則是把對象從流中讀取出來。這里寫到流中的對象則是原始對象的一個拷貝,因為原始對象還存在 JVM 中,所以我們可以利用對象的序列化產生克隆對象,然后通過反序列化獲取這個對象。
注意每個需要序列化的類都要實現Serializable 接口,如果有某個屬性不需要序列化,可以將其聲明為transient,即將其排除在克隆屬性之外。
//深度拷貝
public Object deepClone() throws Exception{
// 序列化
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(this);
// 反序列化
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
return ois.readObject();
}因為序列化產生的是兩個完全獨立的對象,所有無論嵌套多少個引用類型,序列化都是能實現深拷貝的。
關于“Java的深拷貝和淺拷貝怎么實現”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





