溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
魯春利的工作筆記,誰說程序員不能有文藝范?
HDFS Architecture見:
http://hadoop.apache.org/docs/r2.6.0/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
或下載的tar包解壓后的
hadoop-2.6.0/share/doc/hadoop/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
Hadoop分布式文件系統(Hadoop Distributed File System,簡稱HDFS)是一個分布式的文件系統,運行在廉價的硬件上。HDFS是高容錯的,被設計成在低成本硬件上部署,為應用數據提供高吞吐量的訪問,適用于具有大規模數據集的應用程序。
說明:分布式應用中數據是分散在不同的機器上的,而通過分布式的文件系統,提供了統一的數據訪問方式,屏蔽了底層數據存儲位置的差異。
HDFS的設想和目標
1、硬件故障
在集中式環境下,總是假定機器是能夠穩定持續運行的;而分布式環境恰恰相反,它認為硬件錯誤是常態,而非異常情況。HDFS有成百上千的計算機節點組成,每個節點存儲部分數據。大量的節點中,任意節點都有可能由于故障而無法提供服務,因此故障檢測,快速、自動的故障恢復是HDFS設計的核心架構目標。
2、流式數據訪問
運行于HDFS之上的應用程序需要以流式方式來進行數據集的讀取。HDFS不是為了通用的目的而設計的,它主要被設計用來實現批量數據處理,而非交互式的數據運算;高吞吐量的數據處理,而非低延遲的數據計算。
3、大數據集
HDFS以支持大數據集合為目標,一個存儲在上面的典型文件大小一般都在GB至TB,一個單一HDFS實例應該能支撐數以千萬計的文件。
4、一致性模型
HDFS應用對文件要求的是write-one-read-many訪問模型。一個文件經過創建、寫,關閉之后就不需要改變。這一假設簡化了數據一致性問題,使高吞吐量的數據訪問成為可能。
5、由移動數據到移動計算的轉移
將計算移動到數據附近,比之將數據移動到應用所在顯然更好,HDFS提供給應用這樣的接口。
6、跨異構硬件和軟件平臺的可移植性
HDFS被設計成可輕易從一個平臺移動到另一個平臺。
HDFS Architecture
HDFS采用主/從(master/slave)結構,一個HDFS集群由一個NameNode(簡稱NN)節點和一定數量的DataNode(簡稱DN)節點組成。
NN是HDFS集群的master server,是整個HDFS集群的核心,它管理HDFS集群的名稱空間,并接收客戶端的請求(具體請求還是由DN處理)。DN一般情況下每臺slave機器會配置一個,管理slave機器上存儲的數據。
當用戶上報數據時,數據以數據塊(Block)的形式存儲在數據節點上,一個文件可能被分割為一個或者多個數據塊。
NN執行文件系統的namespace操作,例如打開、關閉、重命名文件和目錄,同時維護了block到DN的映射關系。DN在NN的指揮下進行block的創建、刪除和復制,以及根據NN維護的block和DN的映射關系處理client的數據讀寫請求。
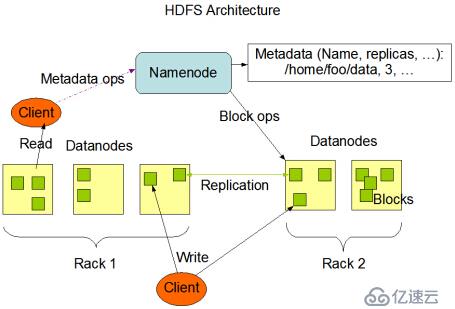
說明:
上述為單NN方式,NN存儲的是元數據信息,一旦出故障,那么整個HDFS集群就掛了。
部署時一個主機可以同時配置NN和DN,也可以配置多個DN,但很少有人那么干。
數據塊是有副本的,默認為3,存儲為本機、同一機架內機器、其他機架內機器(機架感知)。
Client端的讀寫請求都要先和NN打招呼,然后再通過DN真正干活。
HDFS Namespace
HDFS支持傳統的層次型文件組織,與大多數其他文件系統類似,用戶可以創建目錄,并在其間創建、刪除、移動和重命名文件。HDFS不支持user quotas和訪問權限,也不支持鏈接(link),不過當前的架構并不排除實現這些特性。Namenode維護文件系統的namespace,任何對文件系統namespace和文件屬性的修改都將被Namenode記錄下來。應用可以設置HDFS保存的文件的副本數目,文件副本的數目稱為文件的 replication因子,這個信息也是由Namenode保存。
說明:
可以通過hdfs dfsadmin -setQuota可以對目錄進行限額。
hdfs dfs -setrep可以動態調整副本數目。
hdfs上任何的操作都會記錄在edits日志文件中,由參數dfs.namenode.edits.dir指定存放路徑。
HDFS Data Replication
HDFS被設計成在一個大集群中可以跨機器地可靠地存儲海量的文件。它將每個文件存儲成block序列,除了最后一個block,所有的block都是同樣的大小。文件的所有block為了容錯都會被復制。每個文件的block大小和replication因子都是可配置的。Replication因子可以在文件創建的時候配置,以后也可以改變。
HDFS中的文件是write-one,并且嚴格要求在任何時候只有一個writer。Namenode全權管理block的復制,它周期性地從集群中的每個Datanode接收心跳包和一個Blockreport。心跳包的接收表示該Datanode節點正常工作,而Blockreport包括了該Datanode上所有的block組成的列表。
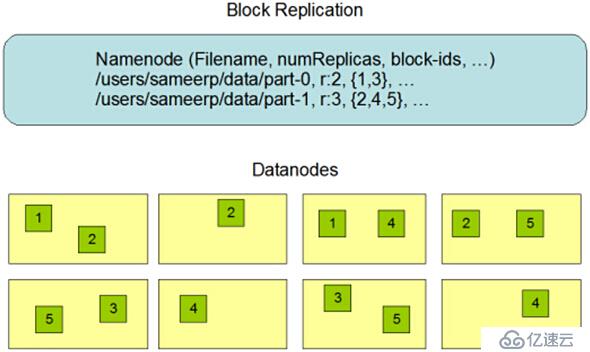
1、副本存放
默認情況下,replication因子是3,HDFS的存放策略是第一個副本存放在client連接到的DN節點,一個副本放在同一機架上的另一個節點,最后一個副本放在不同機架上的一個節點。
說明:
HDFS的機架感知不是自適應的,需要管理人員進行配置。
2、副本選擇
為了降低整體的帶寬消耗和讀延時,HDFS會盡量讓reader讀最近的副本。
3、安全模式
Namenode啟動時會進入一個稱為Safemode的特殊狀態,處在這個狀態的Namenode是不會進行數據塊的復制的。
Namenode從所有的Datanode接收心跳包和Blockreport。Blockreport包括了某個Datanode所有的數據塊列表。
每個block都有指定的最小數目的副本(dfs.namenode.replication.min),當Namenode確認了某個數據塊副本的最小數目,那么該block被認為是安全的。
如果一定百分比(dfs.namenode.safemode.threshold-pct)的數據塊檢測確認是安全的,那么Namenode將退出Safemode狀態,接下來它會確定還有哪些數據塊的副本沒有達到指定數目,并將這些block復制到其他Datanode。
文件系統元數據的持久化
NN存儲HDFS Namespace的元數據,任何對文件元數據的修改操作,NN都使用一個稱為Editlog的事務日志記錄下來。例如,在HDFS中創建一個文件,NN會在Editlog中插入一條記錄來表示;同樣,修改文件的replication因子也將往Editlog中插入一條記錄。NN在本地OS的文件系統上存儲Editlog文件,整個文件系統的namespace,包括block到文件的映射、文件的屬性,都存儲在稱為FsImage的文件中,這個文件也是存放在NN所在的文件系統上。
NN在內存中保存者整個文件系統namespace和文件Blockmap的映射,一個4G內存的NN足夠支持海量的文件和目錄。當NN啟動時,它從硬盤讀取Editlog和FsImage,講所有Editlog中的事務作用于FsImage文件,并將新版本的FsImage從內存中flush到硬盤上,然后再truncate這舊的Editlog,因為這個舊的Editlog已經被作用到FsImage上了,該過程稱為checkpoint。
DN講文件保存在本地的文件系統上,但是它并知道關于文件的任何信息。DN不會在一個目錄中存放所有文件,相反,它用啟發式的方法來確定每個目錄中的最佳文件數目,并且在適當的時候創建子目錄。當一個DN啟動時,它掃描本地文件系統,對這些本地文件產生相應的一個所有HDFS數據塊的列表,然后發送報告到DN,這個報告就是BlockReport。
通信協議
所有的HDFS通信協議都是構建于TCP/IP協議之上。客戶端通過一個可配置的端口與NN通信,通過ClientProtocol與NN通信;而DN使用DatanodeProtocol與NN通信。ClientProtocol與DatanodeProtocol協議都是基于RPC協議進行的封裝。在HDFS的設計中,NN不會主動發起RPC,而只是被動響應DN和Client端的請求。
健壯性
HDFS的主要目標就是實現在失敗情況下數據存儲可靠性,常見的三種失敗為:NN failure、DN failure和網絡分割(network partition)。
(1)硬盤數據錯誤、心跳檢測和重新復制
DN定期向NN發送心跳信息,但是網絡切割可能導致部分DN失去與NN的連接。NN通過心跳包的缺失檢測到這一情況,將這些DN標記為dead,不會再將新的IO請求發給它們。HDFS將無法再訪問處于dead狀態的DN上存儲的數據,因此一些block的副本數將低于配置的閥值。NN不斷跟蹤需要復制的數據塊,并在任何需要的時候啟動復制。在下述情況下可能觸發重新復制:DN失效、某個block損壞、DN節點磁盤錯誤或者副本因子增加。
(2)集群均衡
HDFS集群的自動均衡計劃,即當DN節點的磁盤空間不足時自動將數據移動到其他節點,或者當某個文件的請求數突然增加時, 復制數據到集群中的其他節點已滿足應用需求,但該機制暫未實現。
(3)數據完整性
由于客戶端訪問時,由于存儲設備故障、網絡故障或者軟件BUG,都有可能導致數據塊損壞,HDFS實現了數據內容校驗和,當讀取數據時會自動檢驗數據塊的完整性,若存在問題,會嘗試從其他DN讀取數據。
(4)元數據磁盤錯誤
FsImage和Editlog是HDFS的核心數據結構,它們的損壞將導致整個HDFS集群不可使用。因此,NN可以配置為FsImage和Editlog存儲多個副本(dfs.namenode.name.dir配置以逗號分割的多個路徑),所有的操作都會對多個副本同步更新。
說明:
NN在HDFS集群中存在單獨故障(SPOF)問題。當NN節點失敗時,如果沒有配置HA則必須進行人工處理,或者講NN配置為HA模式。
(5)快照
HDFS does not currently support snapshots but will in a future release.
NameNode
NN節點數據在本地存儲的位置由hdfs-site.xml文件中參數${dfs.namenode.name.dir}指定。
<property> <name>dfs.namenode.name.dir</name> <value>/usr/local/hadoop2.6.0/data/dfs/name</value> </property>
查看${dfs.namenode.name.dir}目錄:
[hadoop@nnode name]$ pwd /usr/local/hadoop2.6.0/data/dfs/name [hadoop@nnode name]$ ls current [hadoop@nnode name]$
在第一次部署好Hadoop集群之后,需要在NN節點上格式化磁盤:
$HADOOP_HOME/bin/hdfs namenode
-format
格式化完成后會在${dfs.namenode.name.dir}/current目錄下生成如下目錄結構:
current目錄下有四類文件:
事務日志記錄文件(edits);
文件系統映像(fsp_w_picpath);
當前文件系統映像應用過的事務號(seen_txid);
VERSION文件。
[hadoop@nnode current]$ ll -h -rw-rw-r-- 1 hadoop hadoop 42 Nov 21 17:21 edits_0000000000000035252-0000000000000035253 -rw-rw-r-- 1 hadoop hadoop 42 Nov 21 17:23 edits_0000000000000035254-0000000000000035255 -rw-rw-r-- 1 hadoop hadoop 42 Nov 21 17:25 edits_0000000000000035256-0000000000000035257 -rw-rw-r-- 1 hadoop hadoop 42 Nov 21 17:27 edits_0000000000000035258-0000000000000035259 -rw-rw-r-- 1 hadoop hadoop 42 Nov 21 17:28 edits_0000000000000035260-0000000000000035261 -rw-rw-r-- 1 hadoop hadoop 231K Nov 21 22:29 fsp_w_picpath_0000000000000035842 -rw-rw-r-- 1 hadoop hadoop 62 Nov 21 22:29 fsp_w_picpath_0000000000000035842.md5 -rw-rw-r-- 1 hadoop hadoop 231K Nov 21 23:29 fsp_w_picpath_0000000000000035930 -rw-rw-r-- 1 hadoop hadoop 62 Nov 21 23:29 fsp_w_picpath_0000000000000035930.md5 -rw-rw-r-- 1 hadoop hadoop 6 Nov 21 17:27 seen_txid -rw-rw-r-- 1 hadoop hadoop 204 Nov 21 23:29 VERSION
VERSION文件是屬性文件:
[hadoop@nnode current]$ cat VERSION #Sat Nov 21 23:29:03 CST 2015 # 文件系統唯一標識,首次format時設置,DN注冊到NN之前是不知道該值的,可以區分新建的DN namespaceID=339614018 # Cluster標識,DN與這里的需要一致 clusterID=CID-61347f43-0510-4b07-ad99-956472c0e49f # NN存儲的創建時間,當NN升級后,該值會更新 cTime=0 # 存儲類型(DATA_NOME/NAME_NODE) storageType=NAME_NODE # block pool標識,后續再介紹(192.168.1.117是原來配置的IP地址,后臺改成192.168.137.117了) blockpoolID=BP-892593412-192.168.1.117-1431598212853 # 用一個負整數來表示HDFS永久數據結構的版本號 layoutVersion=-60 [hadoop@nnode current]$
seen_txid是記錄事務ID的文件,format之后是0,表示NN里面edit-*文件的尾數,事務最后一次被應用到fsp_w_picpath的id。
-rw-rw-r-- 1 hadoop hadoop 42 Nov 21 17:27 edits_0000000000000035258-0000000000000035259 -rw-rw-r-- 1 hadoop hadoop 42 Nov 21 17:28 edits_0000000000000035260-0000000000000035261 -rw-rw-r-- 1 hadoop hadoop 236143 Nov 21 22:29 fsp_w_picpath_0000000000000035842 -rw-rw-r-- 1 hadoop hadoop 62 Nov 21 22:29 fsp_w_picpath_0000000000000035842.md5 -rw-rw-r-- 1 hadoop hadoop 236027 Nov 21 23:29 fsp_w_picpath_0000000000000035930 -rw-rw-r-- 1 hadoop hadoop 62 Nov 21 23:29 fsp_w_picpath_0000000000000035930.md5 -rw-rw-r-- 1 hadoop hadoop 6 Nov 21 17:27 seen_txid -rw-rw-r-- 1 hadoop hadoop 204 Nov 21 23:29 VERSION [hadoop@nnode current]$ cat seen_txid 35260 [hadoop@nnode current]$
edits文件為NN保存的事務日志文件,存儲位置由${dfs.namenode.edits.dir}指定,默認取NN節點數據文件位置${dfs.namenode.name.dir}。
fsp_w_picpath文件存儲的是NN節點的元數據文件。
說明:
當namenode -format命令執行的時候,在namenode節點和datanode節點的VERSION中都會產生一個namespaceID值,并且這兩個值必須相同。如果再次執行格式化,那么namenode會產生一個新的namespaceID,但是datanode不會產生新的值。
示例一:查看edits文件
bin/hdfs oev -i edits_0000000000000000057-0000000000000000186 -o edits.xml
示例二:查看fsp_w_picpath文件
bin/hdfs oiv -p XML -i fsp_w_picpath_0000000000000000055 -o fsp_w_picpath.xml
DataNode
DN節點數據的存儲位置也是通過hdfs-site.xml文件進行配置:
<property> <name>dfs.datanode.data.dir</name> <value>/usr/local/hadoop2.6.0/data/dfs/data</value> </property>
DN節點數據存儲結構:
/usr/local/hadoop2.6.0/data/dfs/data |---current |------BP-892593412-192.168.1.117-1431598212853 |-------current |---------------dfsUsed |-------------------168801504 1448121566578 |---------------finalized |-------------------subdir0 |-----------------------subdir0 subdir1 subdir10 subdir11 subdir2 ...... subdir9(目錄) |------------------------- -rw-rw-r-- 1 hadoop hadoop 1377 Nov 21 16:53 blk_1073744377 |------------------------- -rw-rw-r-- 1 hadoop hadoop 19 Nov 21 16:53 blk_1073744377_3560.meta |------------------------- -rw-rw-r-- 1 hadoop hadoop 1438 Nov 21 16:53 blk_1073744378 |------------------------- -rw-rw-r-- 1 hadoop hadoop 19 Nov 21 16:53 blk_1073744378_3561.meta |------------------------- -rw-rw-r-- 1 hadoop hadoop 1671 Nov 21 16:53 blk_1073744379 |------------------------- -rw-rw-r-- 1 hadoop hadoop 23 Nov 21 16:53 blk_1073744379_3562.meta |---------------rbw(空目錄) |---------------VERSION |-------------------#Sat Nov 28 12:03:36 CST 2015 |-------------------namespaceID=339614018 |-------------------cTime=0 |-------------------blockpoolID=BP-892593412-192.168.1.117-1431598212853 |-------------------layoutVersion=-56 |-----------dncp_block_verification.log.curr |-----------dncp_block_verification.log.prev |-----------tmp(空目錄)---------------- |-------VERSION |-----------#Sat Nov 28 12:03:36 CST 2015 |-----------storageID=DS-e1bf6500-fc2f-4e73-bfe7-5712c9818965 |-----------clusterID=CID-61347f43-0510-4b07-ad99-956472c0e49f |-----------cTime=0 |-----------datanodeUuid=33c2f4cb-cd26-4530-9d9b-40d0b748f8b8 |-----------storageType=DATA_NODE |-----------layoutVersion=-56 |---in_use.lock |-------14187(對應的DataNode進程的進程號,可通過ps -ef|grep DataNode查看)
通過hdfs命令上傳一個文件到hdfs:
[hadoop@dnode1 subdir0]$ ll -h ~/httpdomainscan_192.168.1.101_0_20130913160407.hsl -rwxrwxr-x 1 hadoop hadoop 180M Nov 28 12:06 /home/hadoop/httpdomainscan_192.168.1.101_0_20130913160407.hsl
在DN節點目錄current/finalized/subdir0/subdir14下能看到新創建了兩個bock塊:
-rw-rw-r-- 1 hadoop hadoop 128M Nov 28 12:12 blk_1073745442 -rw-rw-r-- 1 hadoop hadoop 1.1M Nov 28 12:12 blk_1073745442_4628.meta -rw-rw-r-- 1 hadoop hadoop 52M Nov 28 12:12 blk_1073745443 -rw-rw-r-- 1 hadoop hadoop 411K Nov 28 12:12 blk_1073745443_4629.meta
說明:
HDFS中block塊的大小固定為128M,但是當一個數據文件的大小不足一個塊大小時,按實際大小分配空間。
我的HDFS集群有兩個DN節點,副本的參數配置的為2,因此在主機dnode1和dnode2的subdir14目錄下都新創建了兩個節點。
NN節點edits文件
# 此時多了一個edits_inprogress_0000000000000036000的文件 -rw-rw-r-- 1 hadoop hadoop 42 Nov 21 17:28 edits_0000000000000035260-0000000000000035261 -rw-rw-r-- 1 hadoop hadoop 1.0M Nov 28 13:31 edits_inprogress_0000000000000036000 -rw-rw-r-- 1 hadoop hadoop 231K Nov 21 22:29 fsp_w_picpath_0000000000000035842 -rw-rw-r-- 1 hadoop hadoop 62 Nov 21 22:29 fsp_w_picpath_0000000000000035842.md5 -rw-rw-r-- 1 hadoop hadoop 231K Nov 21 23:29 fsp_w_picpath_0000000000000035930 -rw-rw-r-- 1 hadoop hadoop 62 Nov 21 23:29 fsp_w_picpath_0000000000000035930.md5 -rw-rw-r-- 1 hadoop hadoop 6 Nov 21 17:27 seen_txid -rw-rw-r-- 1 hadoop hadoop 204 Nov 21 23:29 VERSION
再次查看:
# 多了兩個事務日志,且seen_txid也更新了(36002) -rw-rw-r-- 1 hadoop hadoop 42 Nov 21 17:28 edits_0000000000000035260-0000000000000035261 -rw-rw-r-- 1 hadoop hadoop 42 Nov 28 13:55 edits_0000000000000036000-0000000000000036001 -rw-rw-r-- 1 hadoop hadoop 42 Nov 28 13:56 edits_0000000000000036002-0000000000000036003 -rw-rw-r-- 1 hadoop hadoop 236143 Nov 21 22:29 fsp_w_picpath_0000000000000035842 -rw-rw-r-- 1 hadoop hadoop 62 Nov 21 22:29 fsp_w_picpath_0000000000000035842.md5 -rw-rw-r-- 1 hadoop hadoop 236027 Nov 21 23:29 fsp_w_picpath_0000000000000035930 -rw-rw-r-- 1 hadoop hadoop 62 Nov 21 23:29 fsp_w_picpath_0000000000000035930.md5 -rw-rw-r-- 1 hadoop hadoop 6 Nov 28 13:55 seen_txid -rw-rw-r-- 1 hadoop hadoop 204 Nov 21 23:29 VERSION
查看DN節點元數據信息:
hdfs oiv -p XML -i fsp_w_picpath_0000000000000035842 -o fsp_w_picpath.xml
下載到本地并打開:
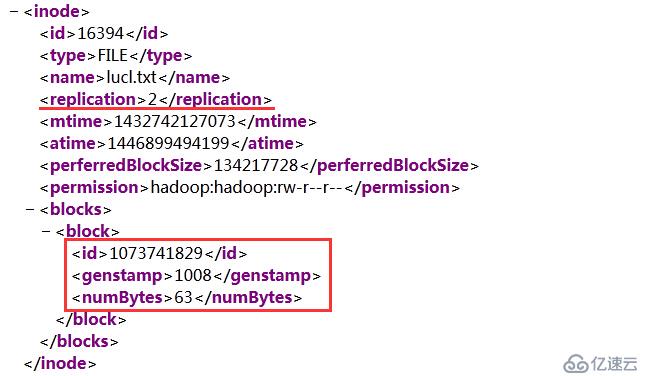
到DN節點查找ID為1073741829的數據塊文件:
# cd current/finalized/subdir0 [hadoop@dnode1 subdir0]$ find . -name "*1073741829*.meta" ./subdir0/blk_1073741829_1008.meta [hadoop@dnode1 subdir0]$ cd subdir0 [hadoop@dnode1 subdir0]$ ll|grep 1073741829 -rw-rw-r-- 1 hadoop hadoop 63 May 27 2015 blk_1073741829 -rw-rw-r-- 1 hadoop hadoop 11 May 27 2015 blk_1073741829_1008.meta [hadoop@dnode1 subdir0]$ cat blk_1073741829 hello world! lucl123456\r\nceshi\r\n123456\r\n ceshi 123456 [hadoop@dnode1 subdir0]$ hdfs dfs -cat lucl.txt hello world! lucl123456\r\nceshi\r\n123456\r\n ceshi 123456 [hadoop@dnode1 subdir0]$
備注:上傳了一個hsl文件,但是從edits中未看到日志記錄,另外就是fsp_w_picpath一直修改時間一直不變。
間隔一段時間后再查看current目錄:
-rw-rw-r-- 1 hadoop hadoop 42 Nov 28 19:38 edits_0000000000000036294-0000000000000036295 -rw-rw-r-- 1 hadoop hadoop 42 Nov 28 19:40 edits_0000000000000036296-0000000000000036297 -rw-rw-r-- 1 hadoop hadoop 1048576 Nov 28 19:40 edits_inprogress_0000000000000036298 -rw-rw-r-- 1 hadoop hadoop 235504 Nov 28 18:08 fsp_w_picpath_0000000000000036205 -rw-rw-r-- 1 hadoop hadoop 62 Nov 28 18:08 fsp_w_picpath_0000000000000036205.md5 -rw-rw-r-- 1 hadoop hadoop 235504 Nov 28 19:08 fsp_w_picpath_0000000000000036263 -rw-rw-r-- 1 hadoop hadoop 62 Nov 28 19:08 fsp_w_picpath_0000000000000036263.md5 -rw-rw-r-- 1 hadoop hadoop 6 Nov 28 19:40 seen_txid -rw-rw-r-- 1 hadoop hadoop 204 Nov 21 23:29 VERSION
查看edits文件:
<?xml version="1.0" encoding="UTF-8"?> <EDITS> <EDITS_VERSION>-60</EDITS_VERSION> <RECORD> <OPCODE>OP_START_LOG_SEGMENT</OPCODE> <DATA> <TXID>36029</TXID> </DATA> </RECORD> <RECORD> <OPCODE>OP_TIMES</OPCODE> <DATA> <TXID>36030</TXID> <LENGTH>0</LENGTH> <PATH>/user/hadoop/lucl.txt</PATH> <MTIME>-1</MTIME> <ATIME>1448694798698</ATIME> </DATA> </RECORD> <RECORD> <OPCODE>OP_END_LOG_SEGMENT</OPCODE> <DATA> <TXID>36031</TXID> </DATA> </RECORD> </EDITS>
查看fsp_w_picpath文件:
<inode> <id>20980</id> <type>FILE</type> <name>httpdomainscan_192.168.1.101_0_20130913160407.hsl</name> <replication>2</replication> <mtime>1448683960850</mtime> <atime>1448683943208</atime> <perferredBlockSize>134217728</perferredBlockSize> <permission>hadoop:hadoop:rw-r--r--</permission> <blocks> <block> <id>1073745442</id> <genstamp>4628</genstamp> <numBytes>134217728</numBytes> </block> <block> <id>1073745443</id> <genstamp>4629</genstamp> <numBytes>53807068</numBytes> </block> </blocks> </inode>
說明:通過fsp_w_picpath能夠了解到文件與數據塊的關系,但是無法知道數據庫與節點的關系。
org.apache.hadoop.hdfs.server.namenode.NameNode
* NameNode serves as both directory namespace manager and
* "inode table" for the Hadoop DFS. There is a single NameNode
* running in any DFS deployment. (Well, except when there
* is a second backup/failover NameNode, or when using federated NameNodes.)
*
* The NameNode controls two critical tables:
* 1) filename->blocksequence (namespace)
* 2) block->machinelist ("inodes")
*
* The first table is stored on disk and is very precious.
* The second table is rebuilt every time the NameNode comes up.
啟動過程會讀取fsp_w_picpath文件:
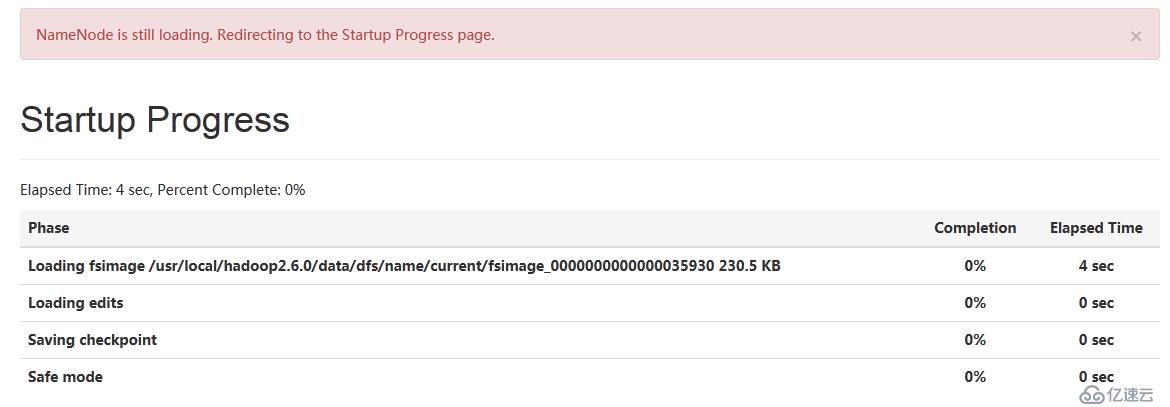
NN在啟動時會去加載fsp_w_picpath中的數據,構造元數據結構。
在啟動的過程中會處于safemode模式,此時HDFS的數據是不看操作的,默認時間是30秒。
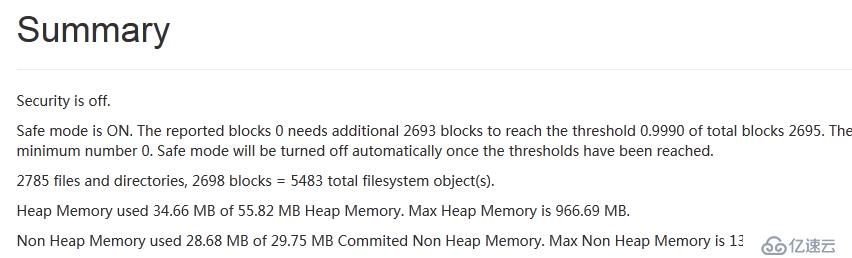
啟動成功后sfaemode會被關閉
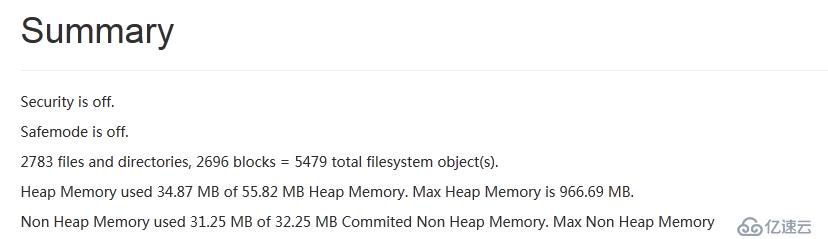
NN節點顯示已啟動
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





