溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
python遍歷迭代器自動鏈式處理數據的代碼怎么寫,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
pytorch.utils.data可兼容迭代數據訓練處理,在dataloader中使用提高訓練效率:借助迭代器避免內存溢出不足的現象、借助鏈式處理使得數據讀取利用更高效(可類比操作系統的資源調控)
書接上文,使用迭代器鏈式處理數據,在Process類的__iter__方法中執行掛載的預處理方法,可以嵌套包裹多層處理方法,類似KoaJs洋蔥模型,在for循環時,自動執行預處理方法返回處理后的數據
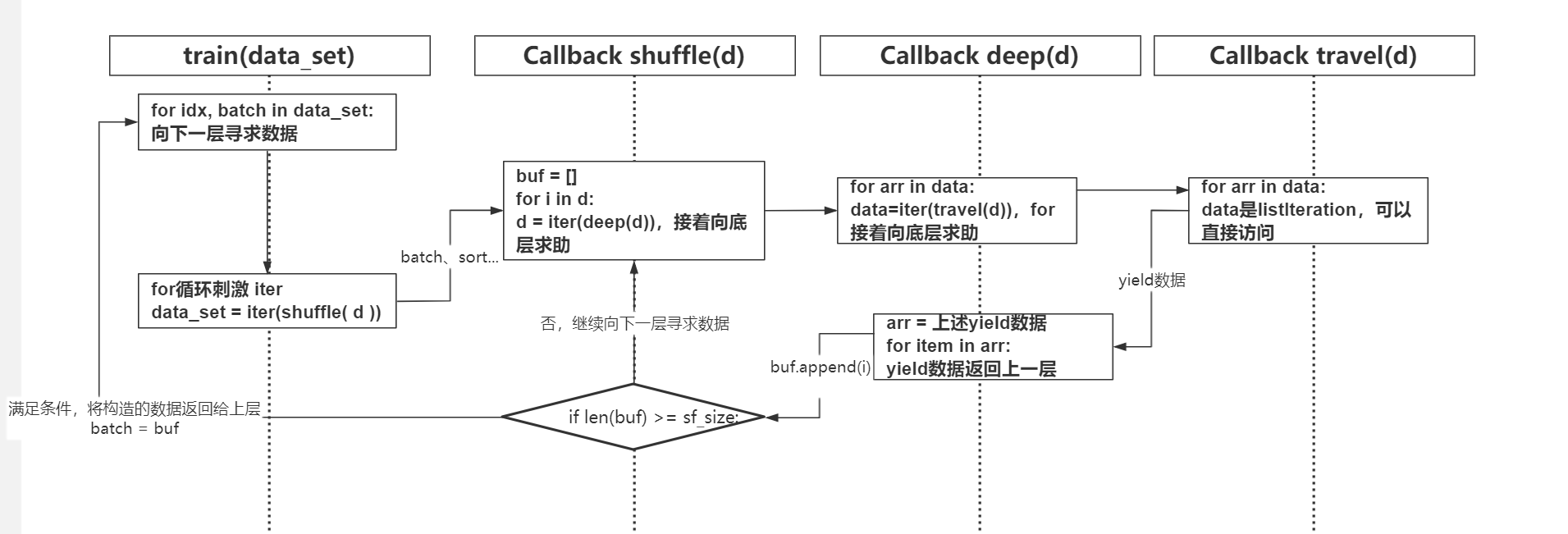
分析下述示例中輸入數據依次執行順序:travel -> deep -> shuffle -> sort -> batch,實際由于嵌套循環或設置緩存的存在,數據流式會有變化,具體如后圖分析
from torch.utils.data import IterableDataset
# ...
import random
class Process(IterableDataset):
def __init__(self, data, f):
self.data = data
# 綁定處理函數
self.f = f
def __iter__(self):
# for循環遍歷時,返回一個當前環節處理的迭代器對象
return self.f(iter(self.data))
a = ['a0', 'a1', 'a2', 'a3', 'a4', 'a5', 'a6', 'a7', 'a8', 'a9']
b = ['b0', 'b1', 'b2', 'b3', 'b4', 'b5', 'b6', 'b7', 'b8', 'b9']
c = ['c0', 'c1', 'c2', 'c3', 'c4', 'c5', 'c6', 'c7', 'c8', 'c9']
# data = [[j + str(i) for i in range(10)] for j in ['a','b', 'c'] ]
data = [a, b, c]
def travel(d):
for i in d:
# print('travel ', i)
yield i
def deep(d):
for arr in d:
for item in arr:
yield item
def shuffle(d, sf_size=5):
buf = []
for i in d:
buf.append(i)
if len(buf) >= sf_size:
random.shuffle(buf)
for j in buf:
# print('shuffle', j)
yield j
buf = []
for k in buf:
yield k
def sort(d):
buf = []
for i in d:
buf.append(i)
if len(buf) >= 3:
for i in buf:
# print('sort', i)
yield i
buf = []
for k in buf:
yield k
def batch(d):
buf = []
for i in d:
buf.append(i)
if len(buf) >= 16:
for i in buf:
# print('batch', i)
yield i
buf = []
# 對訓練數據進行的多個預處理步驟
dataset = Process(data, travel)
dataset = Process(dataset , deep)
dataset = Process(dataset , shuffle)
dataset = Process(dataset , sort)
train_dataset = Process(p, batch)
# 可在此處斷點測試
for i in p:
print(i, 'train')
# train_data_loader = DataLoader(train_dataset,num_workers=args.num_workers,prefetch_factor=args.prefetch)
# train(model , train_data_loader)由上可以構造數據流式方向 :batch(iter(sort(iter(shuffle(iter(deep(iter(travel(iter( d ))))))))))
根據數據流式抽取部分過程畫出時序圖如下:
想遍歷一個可迭代對象中的所有元素,但是卻不想使用for 循環
為了手動的遍歷可迭代對象,使用next() 函數并在代碼中捕獲StopIteration 異常。比如,下面的例子手動讀取一個文件中的所有行
def manual_iter():
with open('/etc/passwd') as f:
try:
while True:
line = next(f)
print(line, end='')
except StopIteration:
pass通常來講, StopIteration 用來指示迭代的結尾。然而,如果你手動使用上面演示的next() 函數的話,你還可以通過返回一個指定值來標記結尾,比如None 。下面是示例:
with open('/etc/passwd') as f:
while True:
line = next(f)
if line is None:
break
print(line, end='')大多數情況下,我們會使用for 循環語句用來遍歷一個可迭代對象。但是,偶爾也需要對迭代做更加精確的控制,這時候了解底層迭代機制就顯得尤為重要了。下面的交互示例向我們演示了迭代期間所發生的基本細節:
>>> items = [1, 2, 3] >>> # Get the iterator >>> it = iter(items) # Invokes items.__iter__() >>> # Run the iterator >>> next(it) # Invokes it.__next__() 1 >>> next(it) 2 >>> next(it) 3 >>> next(it) Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration >>>
看完上述內容,你們掌握python遍歷迭代器自動鏈式處理數據的代碼怎么寫的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





