溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Python中的lxml模塊指的是什么,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
對html或xml形式的文本提取特定的內容,就需要我們掌握lxml模塊的使用和xpath語法。
lxml模塊可以利用xPath規則語法,來快速的定位HEML \ XML 文檔中特定元素以及獲取節點信息(文本內容、屬性值);XPath (XML Path Language)是一門HTML\XML 文檔中查找信息的語言,可用來在HTML|XML文檔中對元素和屬性進行遍歷。
提取xml、html的數據需要lxml模塊和xpath語法配合使用;
在谷歌瀏覽器中對當前頁面測試xpath語法規則。
谷歌瀏覽器xpath helper插件的安裝和使用
我們以windows為例進行xpath helper的安裝。
xpath helper插件的安裝:
1)、下載Chrome插件 XPath Helper
可以在Chrome應用商城進行下載,如果無法下載,也可以從下面的鏈接進行下載
2)、把文件的后綴名crx改為rar,然后解壓到同名文件夾中;
3)、把解壓后的文件夾拖入到已經開啟開發者模式的chrome瀏覽器擴展程序界面;
學習xpath語法需要先了解xpath中的節點關系。
每個html、xml的標簽我們都稱之為節點,其中最頂層的節點稱為根節點。我們以xml為例、html也是一樣的。、


author 是 title的第一個兄弟節點。
1)、XPath 使用路徑表達式來選取XML文檔中的節點或者節點集。
2)、這些路徑表達式和我們在常規的電腦文件系統中看到的表達式非常相似;
3)、使用chrome插件選擇標簽時候,選中的標簽會添加屬性class=“xh-highlight”;

可以根據標簽的屬性值,下標等來獲取特定的節點。
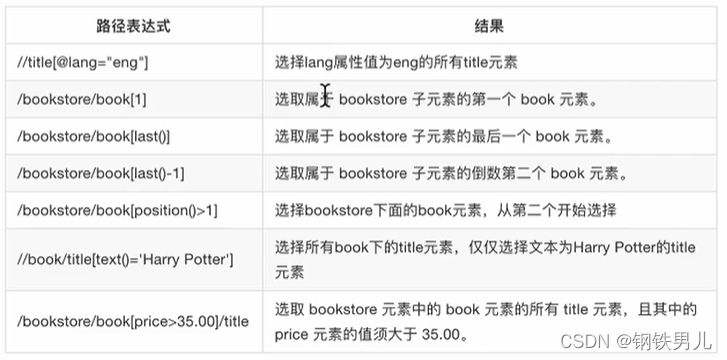
在xpath中,第一個元素的位置是1;
最后一個元素的位置是last();
倒數第二個是last() - 1;
可以同通配符來選取未知的html、xml的元素。

lxml模塊是一個第三方模塊,安裝之后使用。
對發送請求獲取的xml或html形式的響應內容進行提取。
pip install lxml
提取標簽中的文本內容;
提取標簽中的屬性的值;
比如,提取a標簽中href屬性的值,獲取url,進而繼續發起請求。
1)、導入lxml的etree庫
from lxml import etree
2)、利用etree.HTML,將html字符串(bytes類型或str類型)轉化為Element對象,Element對象具有xpath的方法,返回結果的類別。
html = etree.HTML(text)
ret_list = html.xpath("xpath語法規則字符串")3)、xpath方法返回列表的三種情況
返回空列表:根據xpath語法規則字符串,沒有定位到任何元素;
返回由字符串構成的列表:xpath字符串規則匹配的一定是文本內容或某屬性的值;
返回由Element對象構成的列表:xpath規則字符串匹配的是標簽,列表中的Element對象可以繼續進行xpath;
import requests
from lxml import etree
class Tieba(object):
def __init__(self,name):
self.url = "https://tieba.baidu.com/f?ie=utf-8&kw={}".format(name)
self.headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36'
}
def get_data(self,url):
response = requests.get(url,headers=self.headers)
with open("temp.html","wb") as f:
f.write(response.content)
return response.content
def parse_data(self,data):
# 創建element對象
data = data.decode().replace("<!--","").replace("-->","")
html =etree.HTML(data)
el_list = html.xpath('//li[@class="j_thread_list clearfix"]/div/div[2]/div[1]/div[1]/a')
#print(len(el_list))
data_list = []
for el in el_list:
temp = {}
temp['title'] = el.xpath("./text()")[0]
temp['link'] = 'http://tieba.baidu.com' + el.xpath("./@href")[0]
data_list.append(temp)
# 獲取下一頁url
try:
next_url = 'https:' + html.xpath('//a[contains(text(),"下一頁"]/@href')[0]
except:
next_url = None
return data_list,next_url
def save_data(self,data_list):
for data in data_list:
print(data)
def run(self):
# url
# headers
next_url = self.url
while True:
# 發送請求,獲取響應
data = self.get_data(self.url)
# 從響應中提取數據(數據和翻頁用的url)
data_list,next_url = self.parse_data(data)
self.save_data(data_list)
print(next_url)
# 判斷是否終結
if next_url == None:
break
if __name__ == '__main__':
tieba =Tieba("傳智播客")
tieba.run()運行下邊的代碼,觀察對比html的原字符串和打印輸出的結果
from lxml import etree html_str = """<div<<ul> <li class="item-1"><a href="link1.html" rel="external nofollow" >first item</a></li> <li class="item-1"><a href="link2.html" rel="external nofollow" >second item</a></li> <li class="item-inactive"><a href="link3.html" rel="external nofollow" >third item</a></li> <li class="item-1"><a href="link4.html" rel="external nofollow" >fourth item</a></li> <li class="item=0"><a href="link5.html" rel="external nofollow" >fifth item</a> </ur></div> """ html = etree.HTML(html_str) handeled_html_str = etree.tostring(html).decode() print(handeled_html_str)
結論:
lxml.etree.HTML(html_str)可以自動補全標簽;
lxml.etree.tostring 函數可以將轉換位Element對象再轉換回html字符串;
爬蟲如果使用lxml來提取數據,應該以lxml.etree.tostring 的返回結果作為提取數據的依據;
看完上述內容,你們掌握Python中的lxml模塊指的是什么的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





