溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Python切片會索引越界嗎”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Python切片會索引越界嗎”吧!
切片主要用于序列對象中,按照索引區間截取出一段索引的內容。
切片的書寫形式:[i : i+n : m] ;其中,i 是切片的起始索引值,為列表首位時可省略;i+n 是切片的結束位置,為列表末位時可省略;m 可以不提供,默認值是 1,不允許為 0,當 m 為負數時,列表翻轉。
切片的基本含義是:從序列的第 i 位索引起,向右取到后 n 位元素為止,按 m 間隔過濾 。
下面是一些很有代表性的例子,基本涵蓋了切片語法的使用要點:
# @Python貓 li = [1, 4, 5, 6, 7, 9, 11, 14, 16] # 以下寫法都可以表示整個列表,其中 X >= len(li) li[0:X] == li[0:] == li[:X] == li[:] == li[::] == li[-X:X] == li[-X:] li[1:5] == [4,5,6,7] # 從1起,取5-1位元素 li[1:5:2] == [4,6] # 從1起,取5-1位元素,按2間隔過濾 li[-1:] == [16] # 取倒數第一個元素 li[-4:-2] == [9, 11] # 從倒數第四起,取-2-(-4)=2位元素 li[:-2] == li[-len(li):-2] == [1,4,5,6,7,9,11] # 從頭開始,取-2-(-len(li))=7位元素 # 步長為負數時,列表先翻轉,再截取 li[::-1] == [16,14,11,9,7,6,5,4,1] # 翻轉整個列表 li[::-2] == [16,11,7,5,1] # 翻轉整個列表,再按2間隔過濾 li[:-5:-1] == [16,14,11,9] # 翻轉整個列表,取-5-(-len(li))=4位元素 li[:-5:-3] == [16,9] # 翻轉整個列表,取-5-(-len(li))=4位元素,再按3間隔過濾 # 切片的步長不可以為0 li[::0] # 報錯(ValueError: slice step cannot be zero)
像 C/C++ 、Java 和 JavaScript 等語言,雖然也支持某些“切片”功能,例如截取數組或字符串的片段,但是,它們并沒有一種在語法層面上的通用性支持。
根據維基百科資料,Fortran 是最早支持切片語法的語言(1966),而 Python 則是最具代表性的語言之一。
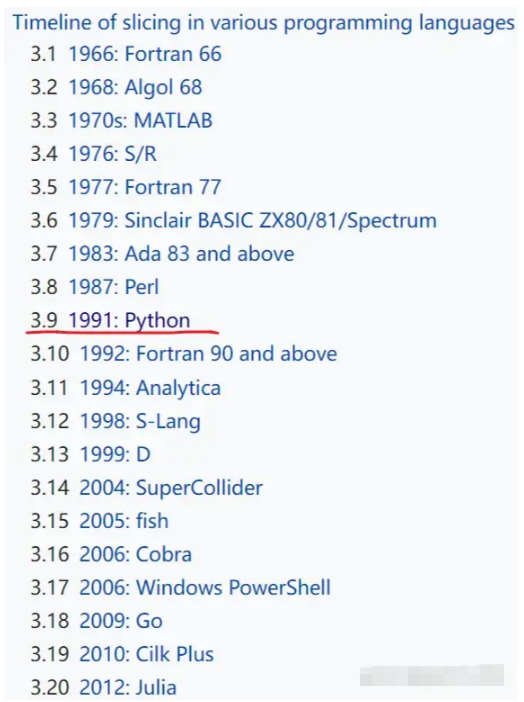
主要編程語言對切片的支持
另外,像 Perl、Ruby、Go 和 Rust 等語言,雖然也有切片,但都不及 Python 那樣靈活和自由(因為它支持 step、負數索引、缺省索引)。
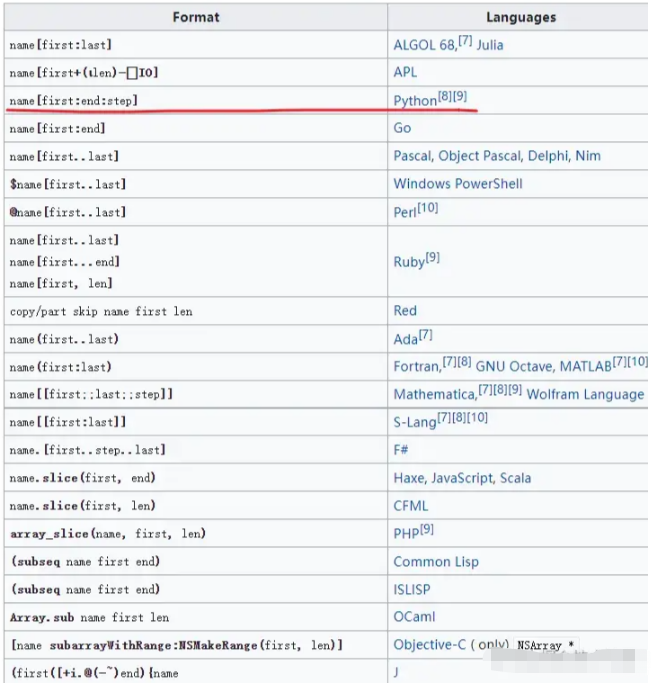
編程語言中切片語法的形式
切片的基本用法就能夠滿足大部分的需求,但是,Python 切片還有一些進階的用法,例如:切片占位符用法(可實現列表的賦值、刪除與拼接操作)、自定義對象實現切片功能、迭代器切片(itertools.islice())、文件對象切片等等。關聯閱讀:Python全面解讀高級特性切片
關于切片的介紹與溫習,就到這里了。
下面進入文章標題的問題:Python 的切片語法為什么不會出現索引越界呢?
當我們根據單個索引進行取值時,如果索引越界,就會得到報錯:“IndexError: list index out of range”。
>>> li = [1, 2] >>> li[5] Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: list index out of range
對于一個非空的序列對象,假設其長度為 length,則它有效的索引值是從 0 到(length - 1)。如果把負數索引也考慮進去,則單個索引值的有效區間是 [-length, length - 1] 閉區間。
但是,當 Python 切片中的索引超出這個范圍時,程序并不會報錯。
>>> li = [1, 2] >>> li[1:5] # 右索引超出 [2] >>> li[5:6] # 左右索引都超出 []
其實,對于這種現象,官方文檔中有所介紹:
The slice of s from i to j is defined as the sequence of items with index k such that i <= k < j. If i or j is greater than len(s), use len(s). If i is omitted or None, use 0. If j is omitted or None, use len(s). If i is greater than or equal to j, the slice is empty.
也就是說:
當左或右索引值大于序列的長度值時,就用長度值作為該索引值;
當左索引值缺省或者為 None 時,就用 0 作為左索引值;
當右索引值缺省或者為 None 時,就用序列長度值作為右索引值;
當左索引值大于等于右索引值時,切片結果為空對象。
對照上面的例子,可以得到:
>>> li = [1, 2] >>> li[1:5] # 等價于 li[1:2] [2] >>> li[5:6] # 等價于 li[2:2] []
歸結起來一句話:Python 解釋器把可能導致索引越界的操作給屏蔽了,你的寫法可以很自由,但是最終的結果會被死死限制在合法的索引區間內。
對于這個現象,我其實是有點疑惑的,為什么 Python 不直接報索引越界呢,為什么要修正切片的邊界值,為什么一定要返回一個值呢,即便這個值可能是個空序列?
當我們使用“li[5:6]”時,至少在字面意義上想表達的是“取出索引從 5 到 6 所對應的值”,就像是在說“取出書架上從左往右數的第 6 和 7 本書”。
如果程序是如實地遵照我們的指令的話,它就應該報錯,就應該說:對不起,書架上的書不夠數。
實話說,我并沒有查到這方面的解釋,這篇文章也不是要給大家科普 Python 在設計上有什么獨到的見解。恰恰相反,這篇文章的主要目的之一是希望得到大家的回復解答。
在 Go 語言中,遇到同樣的場景時,它的做法是報錯“runtime error: slice bounds out of range”。
在 Rust 語言中,遇到同樣的場景時,它的做法是報錯“byte index 5 is out of bounds of ......”。
在其它支持切片語法的語言中,也許還有跟 Python 一樣的設計。但是,我還不知道有沒有(學識淺薄)……
最后,繼續回到標題中的問題“Python 的切片為什么不會索引越界”。我其實想問的問題有兩個:
當切片語法中的索引超出邊界時,為什么 Python 還能返回結果,返回結果的計算原理是什么?
為什么 Python 的切片語法要允許索引超出邊界呢,為什么不設計成拋出索引錯誤?
對于第一個問題的回答,官方文檔已經寫得很明白了。
到此,相信大家對“Python切片會索引越界嗎”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





