溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“如何解決Python復雜zip文件的解壓問題”,在日常操作中,相信很多人在如何解決Python復雜zip文件的解壓問題問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”如何解決Python復雜zip文件的解壓問題”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!

廢話不多說,直接看問題,使用過 Python 中的標準庫 zipfile 解壓過 zip 格式壓縮包的朋友們,可能遇到過,當壓縮文件中的目錄或文件名中包含中文等常見 unicode 字符時,典型如下面的例子:
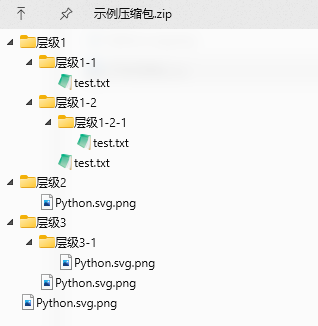
使用 zipfile 的 extract() 或 extractall() 方法直接解壓時,產生的解壓結果名充斥著亂碼,這一點我們通過調用 namelist() 方法就可以看出來:
from zipfile import ZipFile
# 讀入壓縮包文件
file = ZipFile('示例壓縮包.zip')
# 查看壓縮包內目錄、文件名稱
file.namelist()
這是因為 zipfile 中針對壓縮包內容的編碼兼容性差,但我們可以通過下面的函數自行矯正:
def recode(raw: str) -> str:
'''
編碼修正
'''
try:
return raw.encode('cp437').decode('gbk')
except:
return raw.encode('utf-8').decode('utf-8')
for file_or_path in file.namelist():
print(file_or_path, ' -------> ' , recode(file_or_path))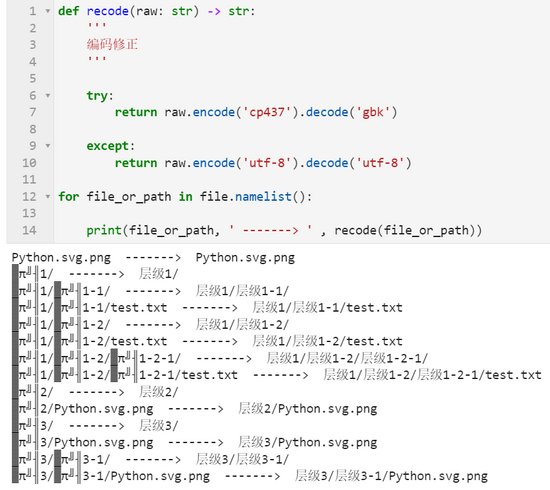
解決了文件名亂碼的問題后,接下來我們就可以配合 shutil 與 os 標準庫中的相關功能,實現將指定任意 zip 壓縮包,完好地解壓到指定的目錄中,代碼如下:
def zip_extract_all(src_zip_file: ZipFile, target_path: str) -> None:
# 遍歷壓縮包內所有內容
for file_or_path in file.namelist():
# 若當前節點是文件夾
if file_or_path.endswith('/'):
try:
# 基于當前文件夾節點創建多層文件夾
os.makedirs(os.path.join(target_path, recode(file_or_path)))
except FileExistsError:
# 若已存在則跳過創建過程
pass
# 否則視作文件進行寫出
else:
# 利用shutil.copyfileobj,從壓縮包io流中提取目標文件內容寫出到目標路徑
with open(os.path.join(target_path, recode(file_or_path)), 'wb') as z:
# 這里基于Zipfile.open()提取文件內容時需要使用原始的亂碼文件名
shutil.copyfileobj(src_zip_file.open(file_or_path), z)
# 向已存在的指定文件夾完整解壓當前讀入的zip文件
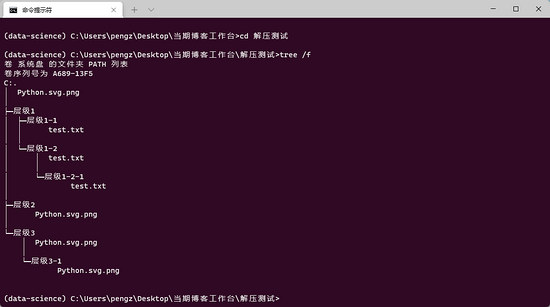
zip_extract_all(file, '解壓測試')可以看到,效果完美 :
到此,關于“如何解決Python復雜zip文件的解壓問題”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





