溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Python如何手寫KNN算法預測城市空氣質量”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
KNN(K-Nearest Neighbor)最鄰近分類算法是數據挖掘分類(classification)技術中常用算法之一,其指導思想是"近朱者赤,近墨者黑",即由你的鄰居來推斷出你的類別。
KNN最鄰近分類算法的實現原理:為了判斷未知樣本的類別,以所有已知類別的樣本作為參照,計算未知樣本與所有已知樣本的距離,從中選取與未知樣本距離最近的 K 個已知樣本,再根據少數服從多數的投票法則(majority-voting),將未知樣本與 K 個最鄰近樣本中所屬類別占比較多的歸為一類。
KNN算法的核心思想:尋找最近的 k 個數據,推測新數據的分類
KNN算法的關鍵:
1.樣本的所有特征都要做可比較的量化
若是樣本特征中存在非數值的類型,必須采取方法將其量化為數值。例如樣本特征中包含顏色,可通過將顏色轉換為灰度值來實現距離計算。
2.樣本特征要做歸一化處理
樣本有多個參數,每一個參數都有自己的定義域和取值范圍,他們對距離計算的影響不一樣,如取值較大的影響力會蓋過取值較小的參數。所以樣本參數必須做一些 scale 處理,最簡單的方式就是所有特征的數值都采取歸一化處理。
3.需要一個距離函數以計算兩個樣本之間的距離
通常使用的距離函數有:歐氏距離、余弦距離、漢明距離、曼哈頓距離等,一般選歐氏距離作為距離度量,但是這是只適用于連續變量。在文本分類這種非連續變量情況下,余弦距離可以用來作為度量。通常情況下,如果運用一些特殊的算法來計算度量的話,K近鄰分類精度可顯著提高,如運用大邊緣最近鄰法或者近鄰成分分析法。
以計算二維空間中的A(x1,y1)、B(x2,y2)兩點之間的距離為例,常用的歐氏距離的計算方法如下圖所示:

確定K的值
K值選的太大易引起欠擬合,太小容易過擬合,需交叉驗證確定 K 值。
KNN算法的優點:
簡單,易于理解,易于實現,無需估計參數,無需訓練;
適合對稀有事件進行分類;
特別適合于多分類問題(multi-modal,對象具有多個類別標簽), KNN比 SVM 的表現要好。
KNN算法的缺點:
KNN算法在分類時有個主要的不足是:當樣本不平衡時,如一個類的樣本容量很大,而其他類樣本容量很小時,有可能導致當輸入一個新樣本時,該樣本的 K 個鄰居中大容量類的樣本占多數。該算法只計算最近的鄰居樣本,某一類的樣本數量很大,那么或者這類樣本并不接近目標樣本,或者這類樣本很靠近目標樣本。無論怎樣,數量并不能影響運行結果。可以采用權值的方法(和該樣本距離小的鄰居權值大)來改進。
該方法的另一個不足之處是計算量較大,因為對每一個待分類的文本都要計算它到全體已知樣本的距離,才能求得它的 K 個最近鄰點。
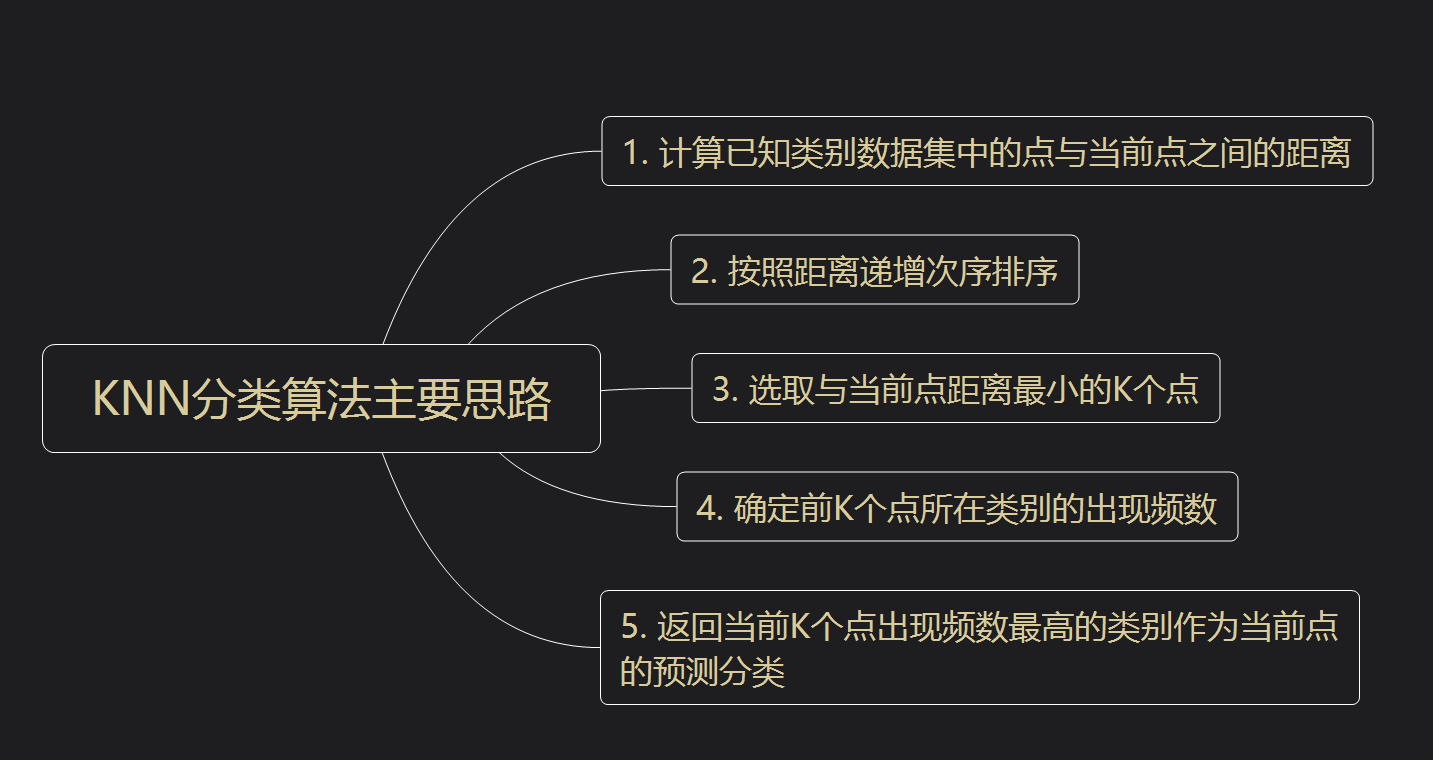
要自己動手用 Python 實現 KNN 算法,主要有以下三個步驟:
算距離:給定待分類樣本,計算它與已分類樣本中的每個樣本的距離。
找鄰居:圈定與待分類樣本距離最近的 K 個已分類樣本,作為待分類樣本的近鄰。
做分類:根據這 K 個近鄰中的大部分樣本所屬的類別來決定待分類樣本該屬于哪個分類。
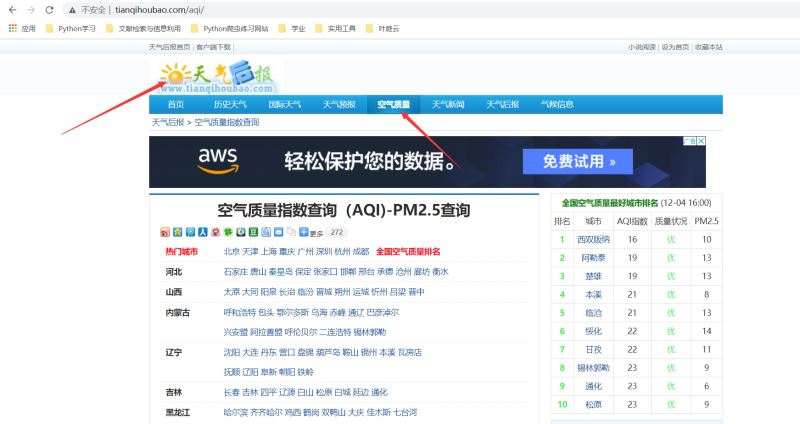
對于這種 Table 表格型數據,可以直接用 pandas 的 read_html() 大法,將數據保存到csv,也就不用再寫爬蟲去解析網頁和提取數據了。
# -*- coding: UTF-8 -*-
"""
@File :spider.py
@Author :葉庭云
@CSDN :https://yetingyun.blog.csdn.net/
@http://www.tianqihoubao.com/aqi/beijing-201901.html
"""
import pandas as pd
import logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
for page in range(1, 13): # 12個月
if page < 10:
url = f'http://www.tianqihoubao.com/aqi/guangzhou-20190{page}.html'
df = pd.read_html(url, encoding='gbk')[0]
if page == 1:
df.to_csv('2019年廣州空氣質量數據.csv', mode='a+', index=False, header=False)
else:
df.iloc[1:,::].to_csv('2019年廣州空氣質量數據.csv', mode='a+', index=False, header=False)
else:
url = f'http://www.tianqihoubao.com/aqi/guangzhou-2019{page}.html'
df = pd.read_html(url, encoding='gbk')[0]
df.iloc[1:,::].to_csv('2019年廣州空氣質量數據.csv', mode='a+', index=False, header=False)
logging.info(f'{page}月空氣質量數據下載完成!')多爬取幾個城市 2019 年歷史空氣質量數據保存到本地
import pandas as pd
# 將2019年成都空氣質量數據作為測試集
df = pd.read_csv('2019年成都空氣質量數據.csv')
# 取質量等級 AQI指數 當天AQI排名 PM2.5 。。。8列數據
# SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame 解決方法
df1 = df[['AQI指數', '當天AQI排名', 'PM2.5', 'PM10', 'So2', 'No2', 'Co', 'O3']].copy()
air_quality = []
# print(df['質量等級'].value_counts())
# 質量等級列數據為字符串 轉為為標簽 便于判斷預測
for i in df['質量等級']:
if i == "優":
air_quality.append('1')
elif i == "良":
air_quality.append('2')
elif i == "輕度污染":
air_quality.append('3')
elif i == "中度污染":
air_quality.append('4')
elif i == "重度污染":
air_quality.append('5')
elif i == "嚴重污染":
air_quality.append('6')
print(air_quality)
df1['空氣質量'] = air_quality
# 將數據寫入test.txt
# print(df1.values, type(df1.values)) # <class 'numpy.ndarray'>
with open('test.txt', 'w') as f:
for x in df1.values:
print(x)
s = ','.join([str(i) for i in x])
# print(s, type(s))
f.write(s + '\n')import pandas as pd
# 自定義其他幾個城市空氣質量數據作為訓練集
df = pd.read_csv('2019年天津空氣質量數據.csv', encoding='utf-8')
# 取質量等級 AQI指數 當天AQI排名 PM2.5 。。。8列數據
# SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame 解決方法
df1 = df[['AQI指數', '當天AQI排名', 'PM2.5', 'PM10', 'So2', 'No2', 'Co', 'O3']].copy()
air_quality = []
# print(df['質量等級'].value_counts())
# 質量等級列數據為字符串 轉為為數字標識
for i in df['質量等級']:
if i == "優":
air_quality.append('1')
elif i == "良":
air_quality.append('2')
elif i == "輕度污染":
air_quality.append('3')
elif i == "中度污染":
air_quality.append('4')
elif i == "重度污染":
air_quality.append('5')
elif i == "嚴重污染":
air_quality.append('6')
print(air_quality)
df1['空氣質量'] = air_quality
# 將數據寫入追加寫入到train.txt
# print(df1.values, type(df1.values)) # <class 'numpy.ndarray'>
with open('train.txt', 'a+') as f:
for x in df1.values:
print(x)
s = ','.join([str(i) for i in x])
# print(s, type(s))
f.write(s + '\n')讀取數據集
def read_dataset(filename1, filename2, trainingSet, testSet): with open(filename1, 'r') as csvfile: lines = csv.reader(csvfile) # 讀取所有的行 dataset1 = list(lines) # 轉化成列表 for x in range(len(dataset1)): # 每一行數據 for y in range(8): dataset1[x][y] = float(dataset1[x][y]) # 8個參數轉換為浮點數 testSet.append(dataset1[x]) # 生成測試集 with open(filename2, 'r') as csvfile: lines = csv.reader(csvfile) # 讀取所有的行 dataset2 = list(lines) # 轉化成列表 for x in range(len(dataset2)): # 每一行數據 for y in range(8): dataset2[x][y] = float(dataset2[x][y]) # 8個參數轉換為浮點數 trainingSet.append(dataset2[x]) # 生成訓練集
計算歐氏距離
def calculateDistance(testdata, traindata, length): # 計算距離 distance = 0 # length表示維度 數據共有幾維 for x in range(length): distance += pow((int(testdata[x]) - int(traindata[x])), 2) return round(math.sqrt(distance), 3) # 保留3位小數
找 K 個相鄰最近的鄰居
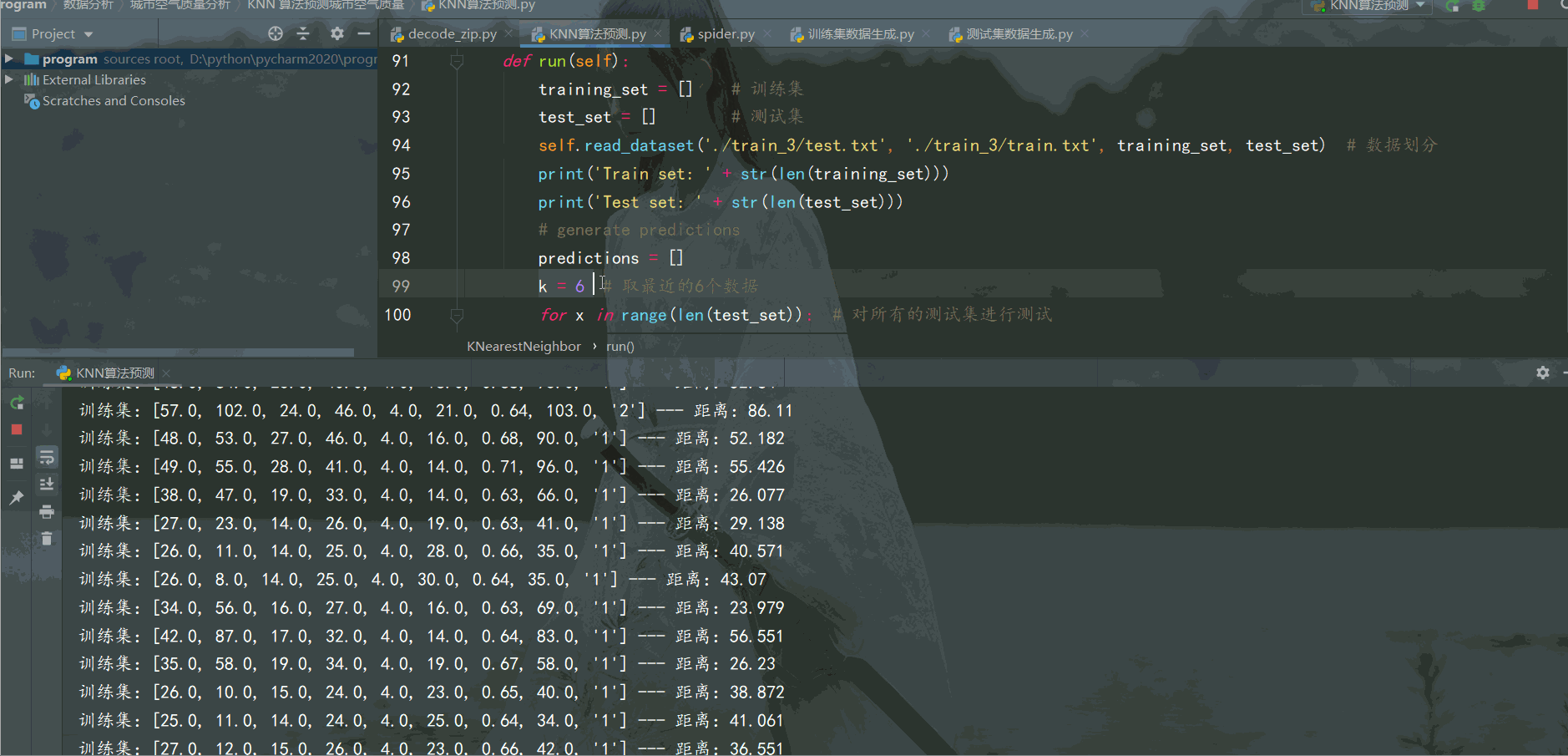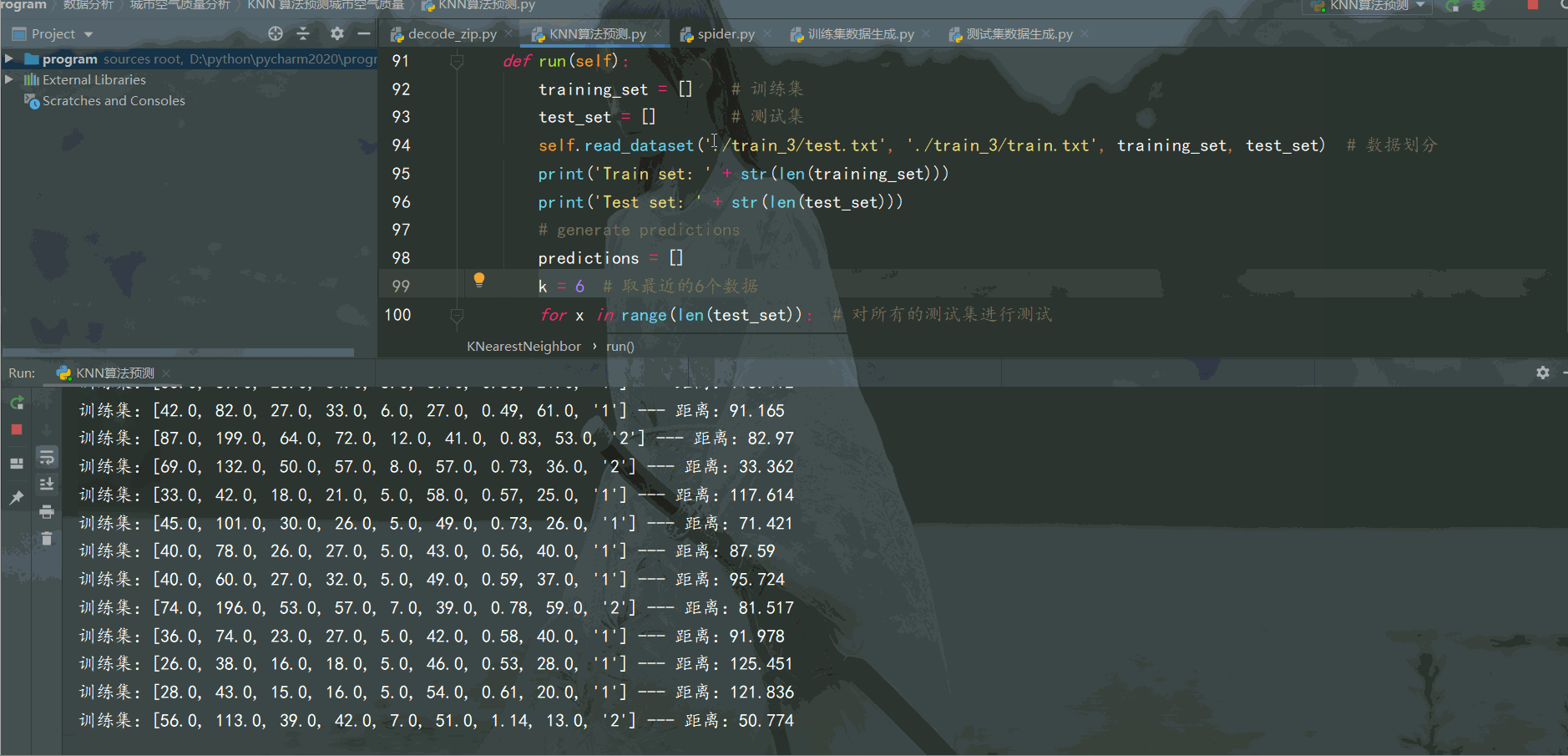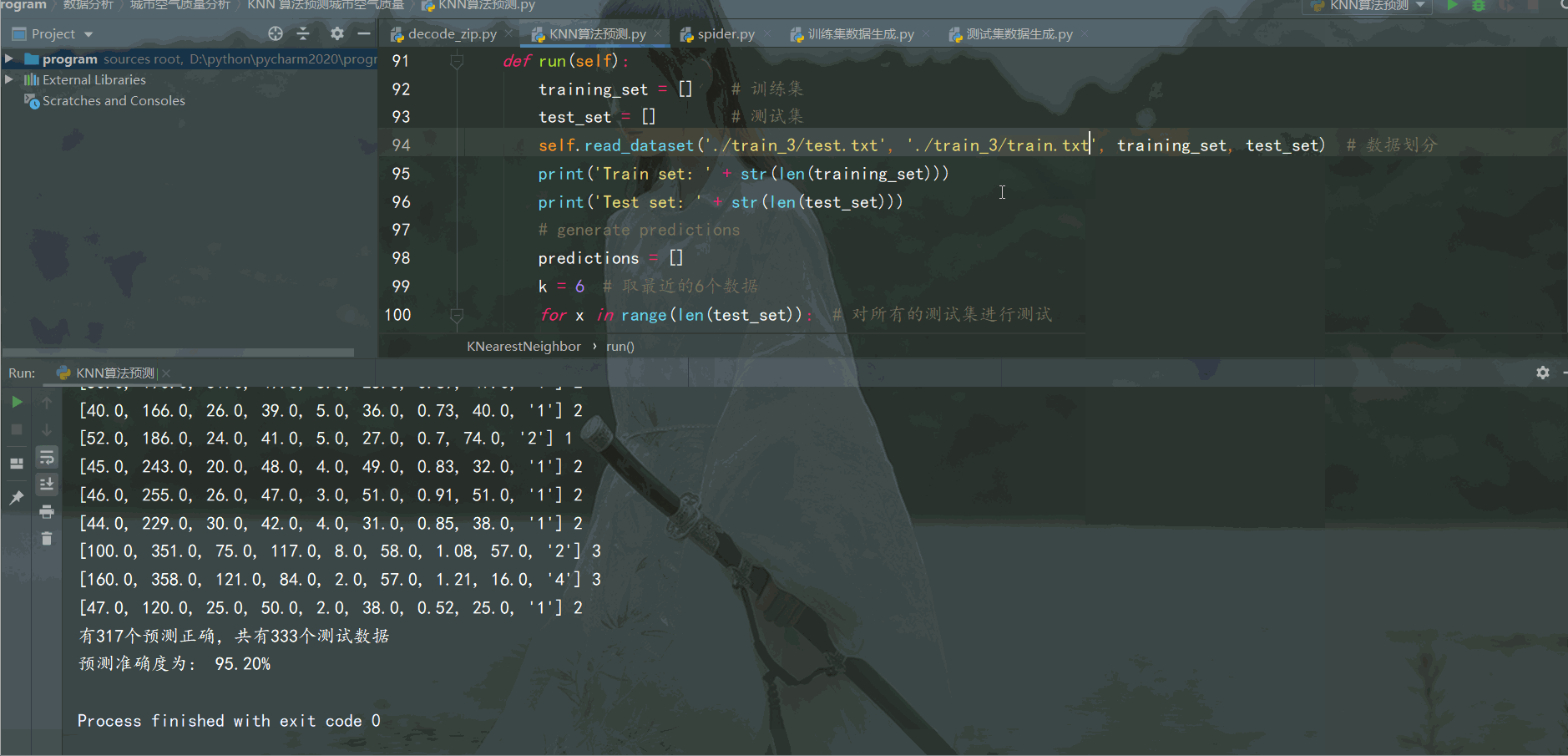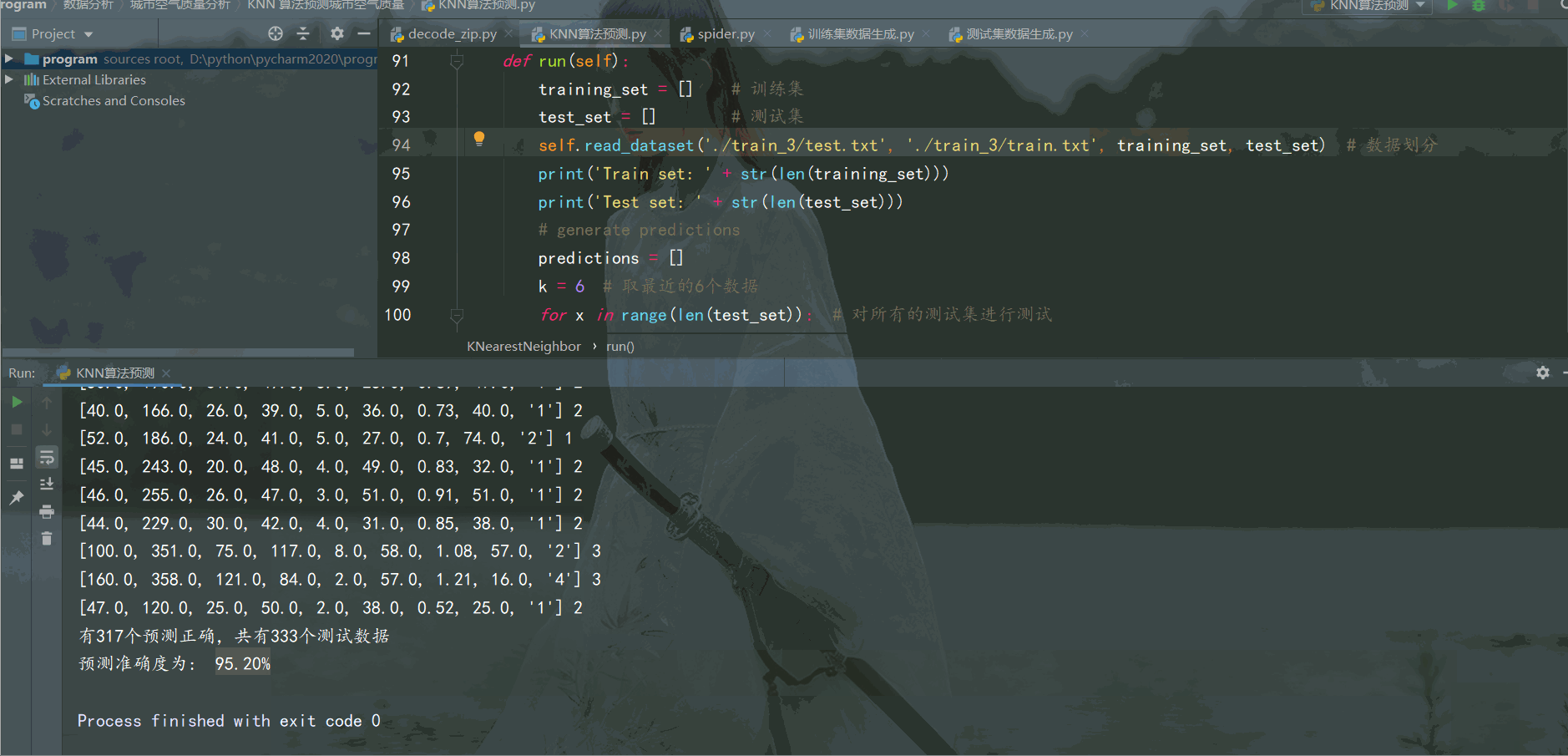
def getNeighbors(self, trainingSet, test_instance, k): # 返回最近的k個邊距
distances = []
length = len(test_instance)
# 對訓練集的每一個數計算其到測試集的實際距離
for x in range(len(trainingSet)):
dist = self.calculateDistance(test_instance, trainingSet[x], length)
print('訓練集:{} --- 距離:{}'.format(trainingSet[x], dist))
distances.append((trainingSet[x], dist))
distances.sort(key=operator.itemgetter(1)) # 按距離從小到大排列
# print(distances)
neighbors = []
# 排序完成后取距離最小的前k個
for x in range(k):
neighbors.append(distances[x][0])
print(neighbors)
return neighbors計算比例最大的分類
def getResponse(neighbors): # 根據少數服從多數,決定歸類到哪一類
class_votes = {}
for x in range(len(neighbors)):
response = neighbors[x][-1] # 統計每一個分類的多少 空氣質量的數字標識
if response in class_votes:
class_votes[response] += 1
else:
class_votes[response] = 1
print(class_votes.items())
sortedVotes = sorted(class_votes.items(), key=operator.itemgetter(1), reverse=True) # 按分類大小排序 降序
return sortedVotes[0][0] # 分類最大的 少數服從多數 為預測結果預測準確率計算
def getAccuracy(test_set, predictions):
correct = 0
for x in range(len(test_set)):
# predictions預測的與testset實際的比對 計算預測的準確率
if test_set[x][-1] == predictions[x]:
correct += 1
else:
# 查看錯誤預測
print(test_set[x], predictions[x])
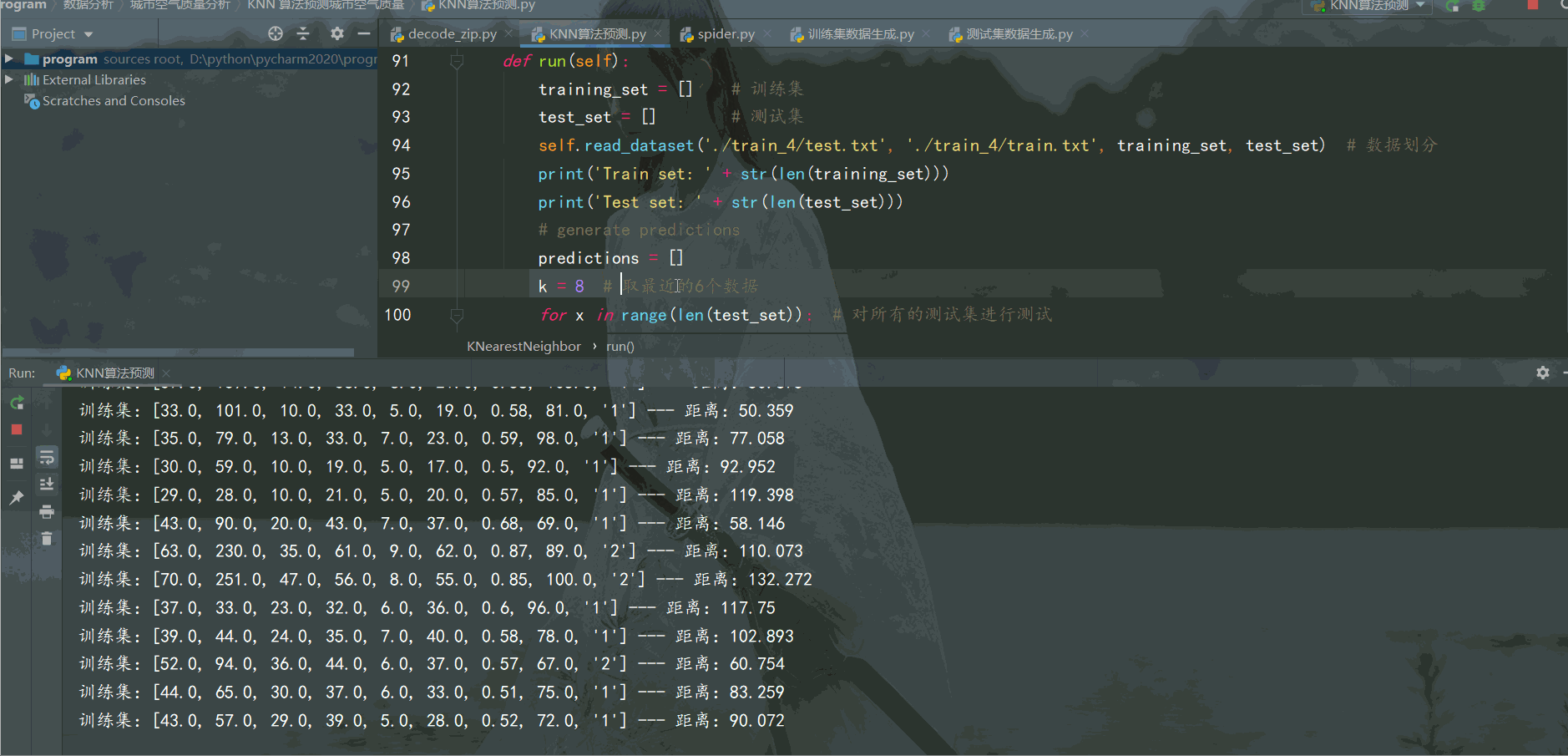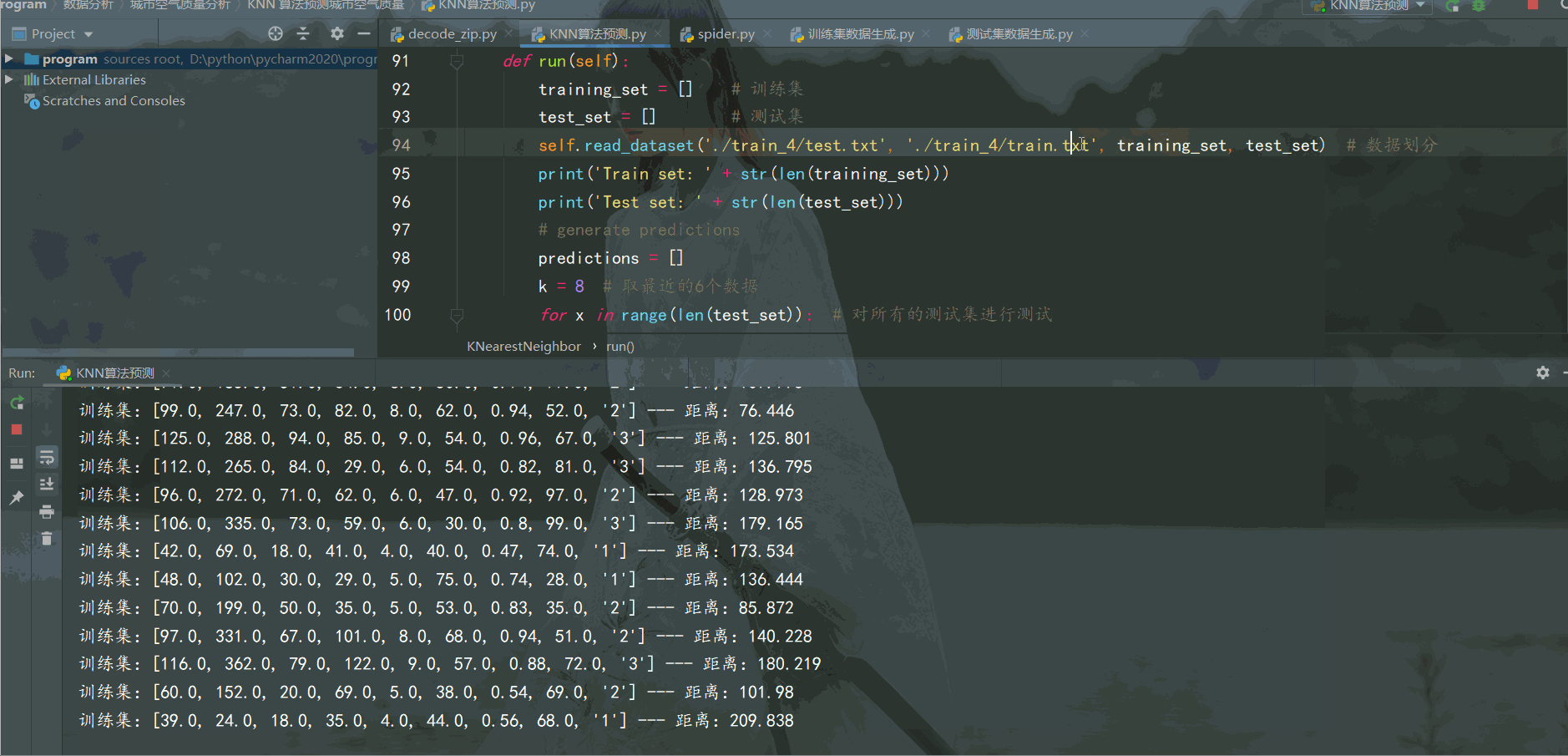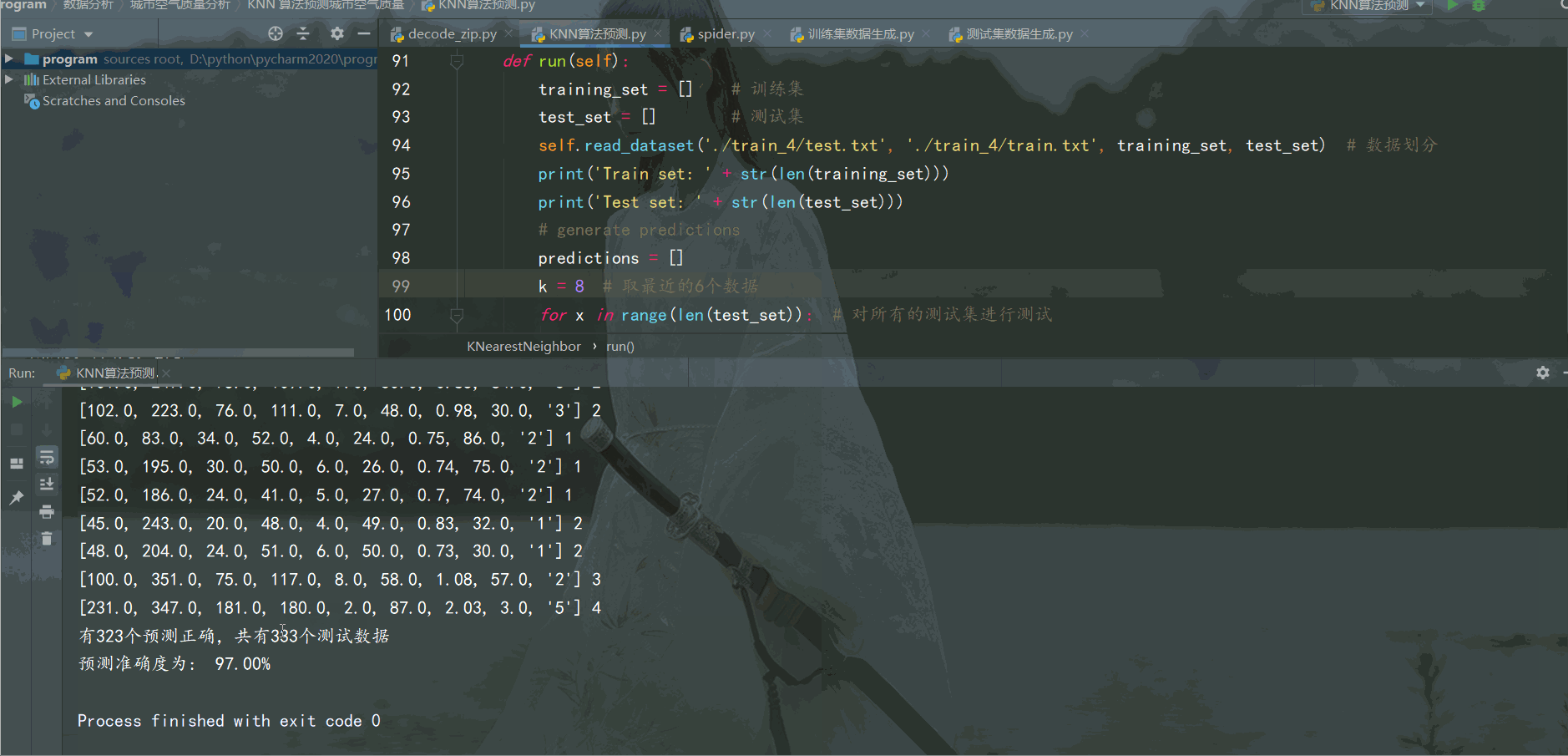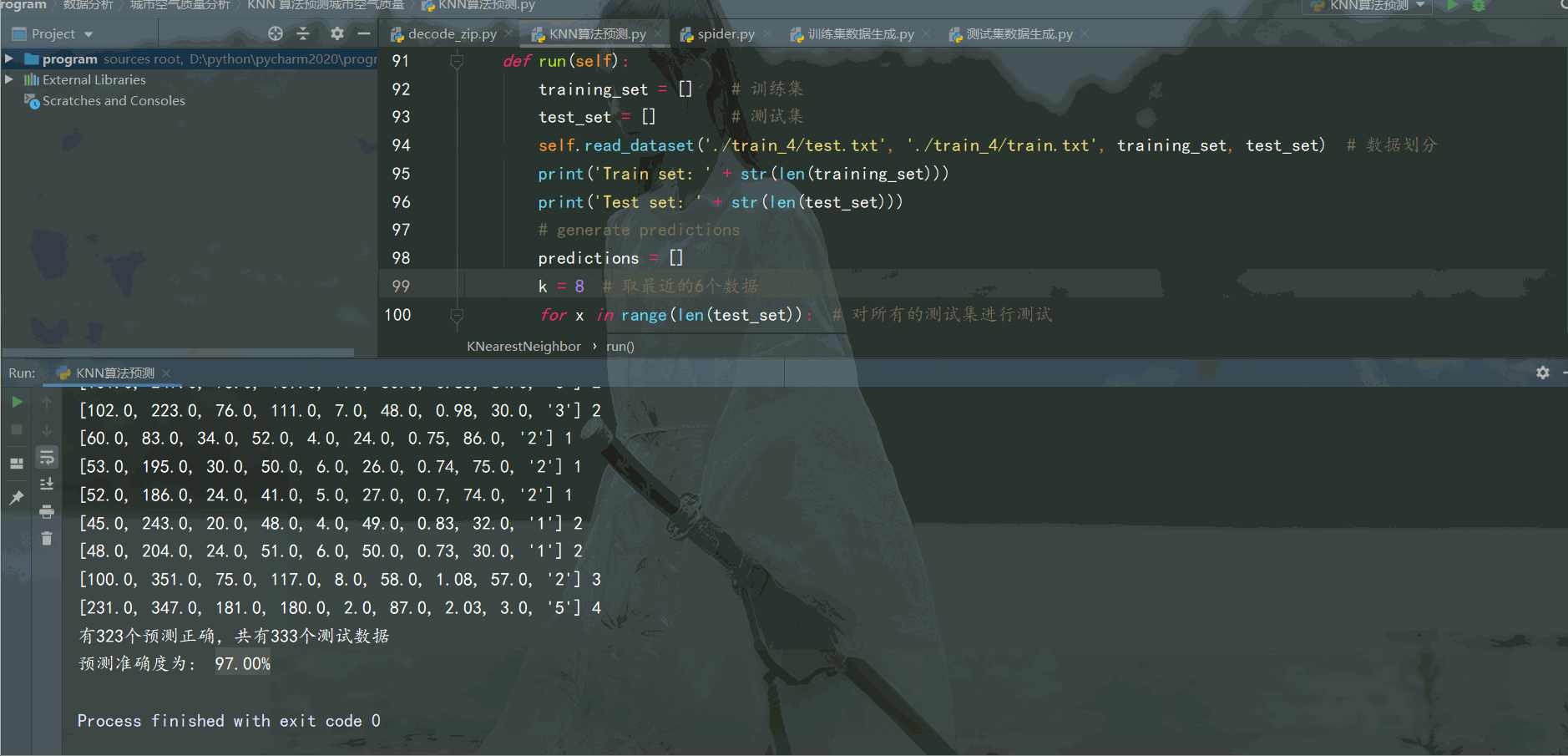
print('有{}個預測正確,共有{}個測試數據'.format(correct, len(test_set)))
return (correct / (len(test_set))) * 100.0run函數調用
# -*- coding: UTF-8 -*-
"""
@Author :葉庭云
@公眾號 :修煉Python
@CSDN :https://yetingyun.blog.csdn.net/
"""
def run(self):
training_set = [] # 訓練集
test_set = [] # 測試集
self.read_dataset('./train_4/test.txt', './train_4/train.txt', training_set, test_set) # 數據劃分
print('Train set: ' + str(len(training_set)))
print('Test set: ' + str(len(test_set)))
# generate predictions
predictions = []
k = 7 # 取最近的6個數據
for x in range(len(test_set)): # 對所有的測試集進行測試
neighbors = self.getNeighbors(training_set, test_set[x], k) # 找到8個最近的鄰居
result = self.getResponse(neighbors) # 找這7個鄰居歸類到哪一類
predictions.append(result)
accuracy = self.getAccuracy(test_set, predictions)
print('預測準確度為: {:.2f}%'.format(accuracy)) # 保留2位小數運行效果如下:
可以通過增加訓練集城市空氣質量數據量,調節找鄰居的數量k,提高預測準確率。
“Python如何手寫KNN算法預測城市空氣質量”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





