溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關Python中如何使用PyTorch實現WGAN的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
在GAN中,有兩個模型,一個是生成模型,用于生成樣本,一個是判別模型,用于判斷樣本是真還是假。但由于在GAN中,使用的JS散度去計算損失值,很容易導致梯度彌散的情況,從而無法進行梯度下降更新參數,于是在WGAN中,引入了Wasserstein Distance,使得訓練變得穩定。本文中我們以服從高斯分布的數據作為樣本。
這里從2維數據,最終生成2維,主要目的是為了可視化比較方便。也就是說,在生成模型中,我們輸入雜亂無章的2維的數據,通過訓練之后,可以生成一個贗品,這個贗品在模仿高斯分布。
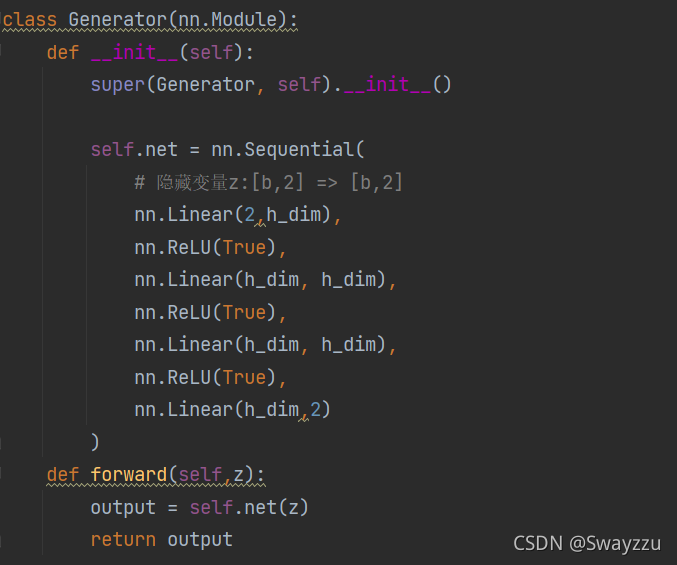
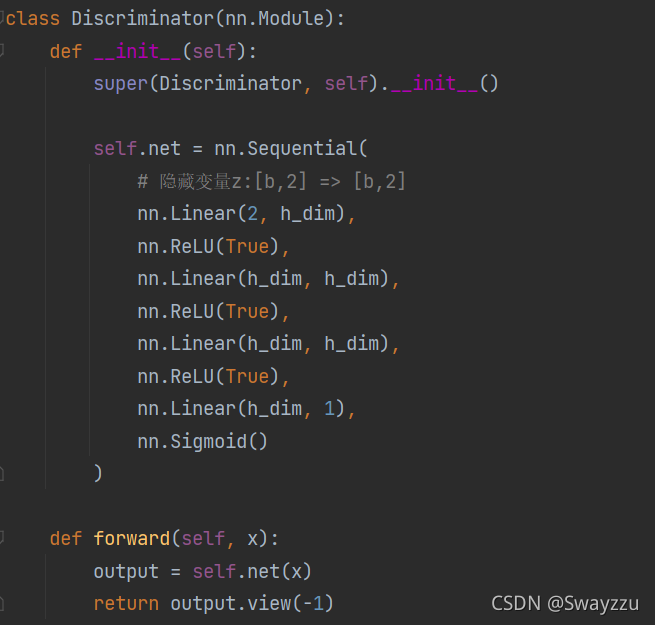
判別器同樣輸入的是2維的數據。比如我們上面的生成器,生成了一個2維的贗品,輸入判別器之后,它能夠最終輸出一個sigmoid轉換后的結果,相當于是一個概率,從而判別,這個贗品到底能不能達到以假亂真的程度。
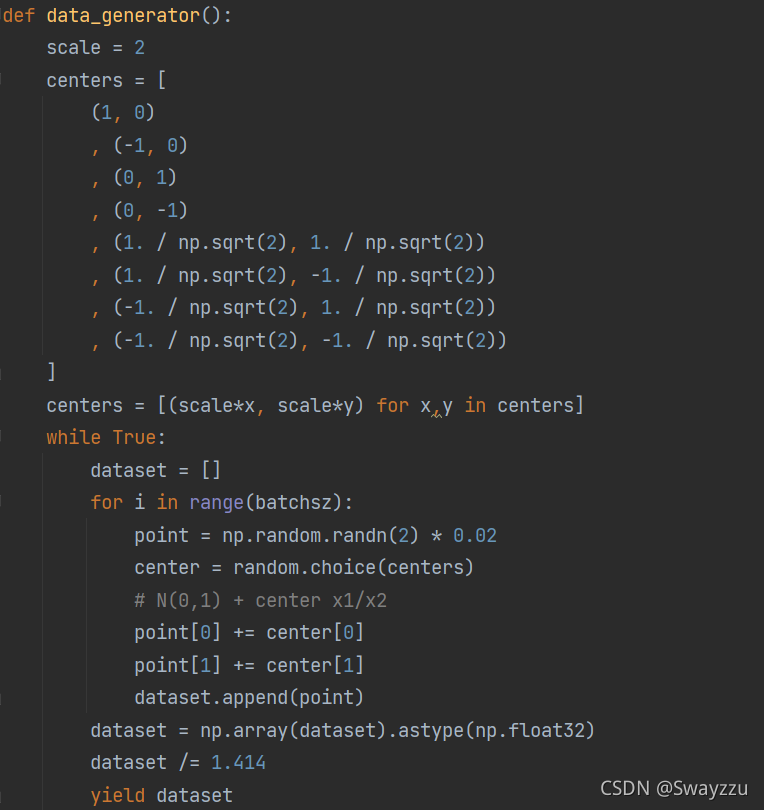
由于我們使用的是高斯模型,因此,直接生成我們需要的數據即可。我們在這個模塊中,生成8個服從高斯分布的數據。
由于使用JS散度去計算損失的時候,會很容易出現梯度極小,接近于0的情況,會使得梯度下降無法進行,因此計算損失的時候,使用了Wasserstein Distance,去度量兩個分布之間的差異。因此我們假如了梯度懲罰的因子。
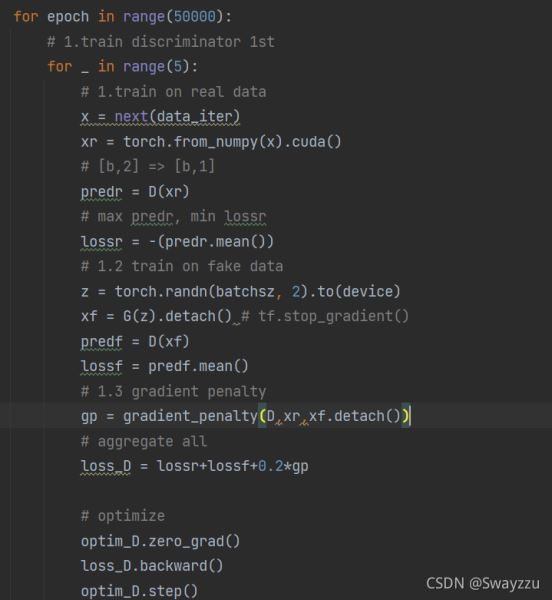
其中,梯度懲罰的模塊如下:
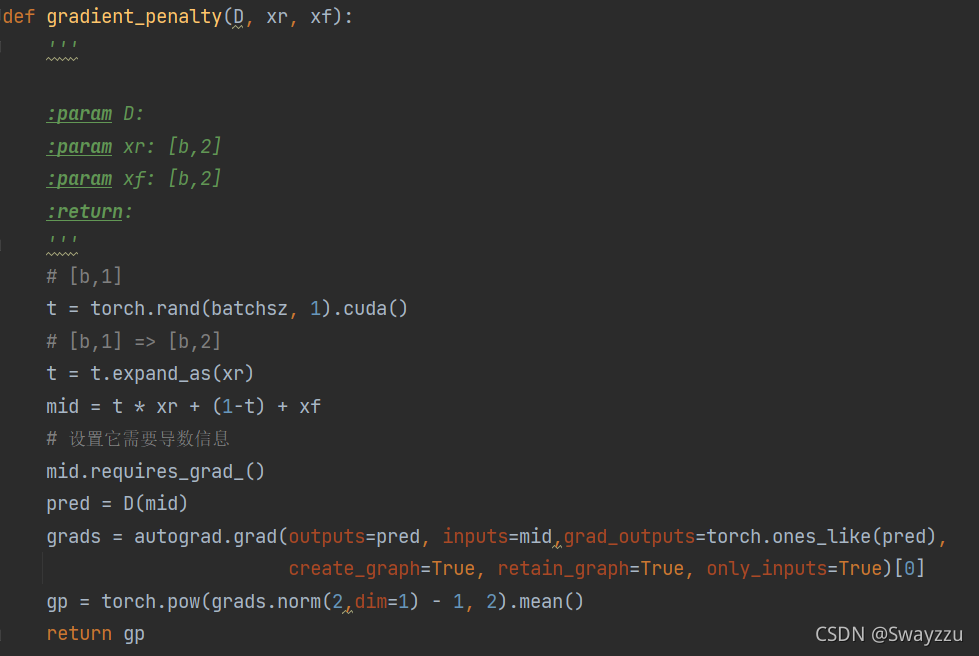
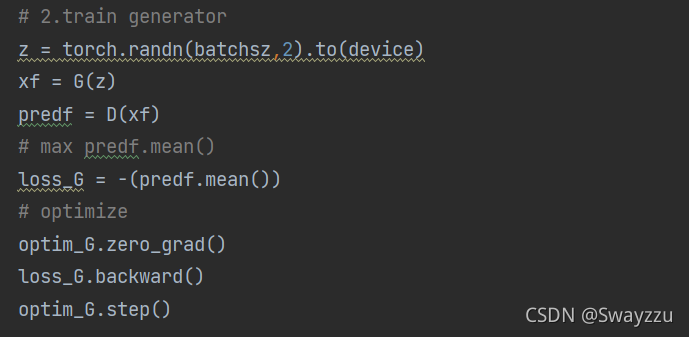
這里的訓練是緊接著判別器訓練的。也就是說,在一個周期里面,先訓練判別器,再訓練生成器。
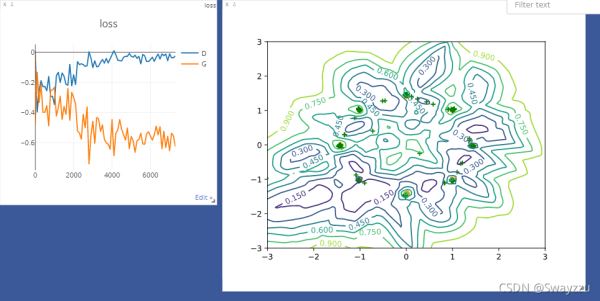
通過visdom可視化損失值,通過matplotlib可視化分布的預測結果。
感謝各位的閱讀!關于“Python中如何使用PyTorch實現WGAN”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





