溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
數據遷移是DBA的日常工作,對于相應的方法、命令等,相信很多人早已了如指掌。圓滿的數據遷移流程不單單指將數據從數據庫A備份恢復到數據庫B,而且要保證遷移前后數據的完整與服務的可用性。
近日,在給客戶做了單機到集群的數據遷移后,發現集群的在線重做日志切換頻繁,進而產生了大量的歸檔日志,對服務器造成了不小的壓力。本文是對上述問題的分析處理過程。
在遷移完成后,需要對集群進行一段時間的深度觀察。通過v$archived_log視圖,分析數據庫歷史的歸檔情況,可以發現整個庫的業務活動情況。
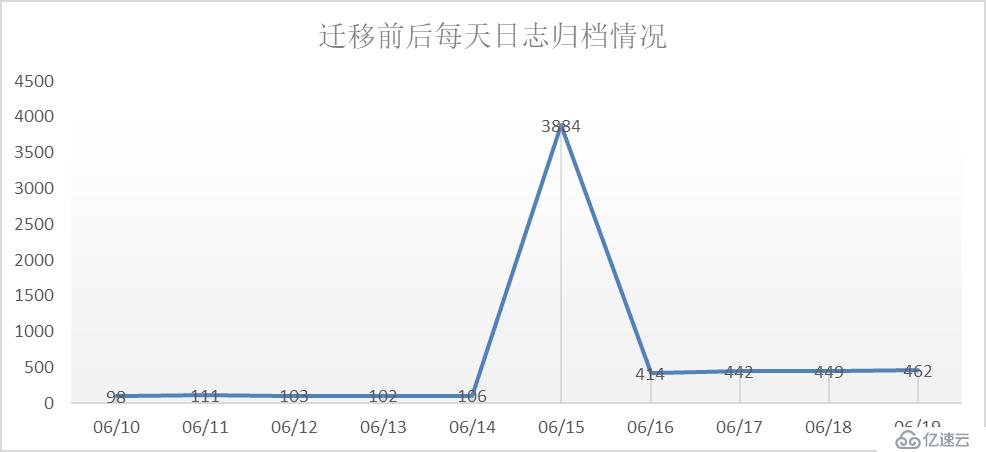
觀察上圖,不難發現遷移(6月15日)前后是一個明顯得變化點,每天日志歸檔頻率由原來的100多次變成400多次。這種情況要么是遷入的系統業務量確實很大,要么是遷入的數據庫用戶配置有問題。
經過與新遷入系統的運維人員溝通確認,該系統的使用人數雖然多,但都是以查詢類的動作偏多,不應該帶來這么大量的日志。因為集群中還有其它系統,不能直接判斷是新系統的問題。假設運維所說情況屬實,那么問題的關鍵點就是要找到產生大量日志的操作語句,進而找到對應的應用,再確認歸檔情況是否正常。
日志歸檔頻繁,說明在線重做日志切換頻繁,一般是由于產生了大量的redo。這里通過awr檢查redo的生成情況。
一天內日志歸檔的詳細情況

這里選擇6月18日上午10點到11點間集群2節點的awr報告
節點1:
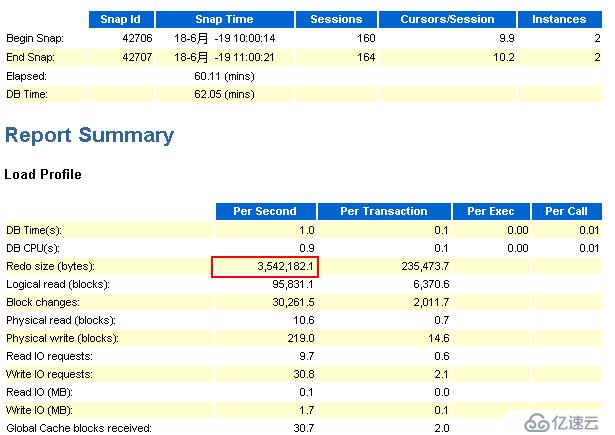
觀察上圖,可以看到在1小時內,節點1的redo的產生速率約為3.38MB/S,那么一小時就有約11.88GB。
節點2:
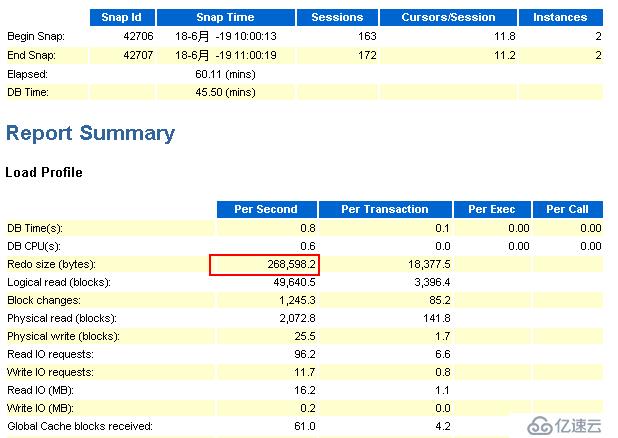
觀察上圖,可以看到在1小時內,節點2的redo的產生速率約為0.26MB/S,那么一小時就有約0.9GB。
通過查詢v$archived_log視圖,分類計算出10點到11點間所產生的歸檔日志大小約為12.3GB,這與根據awr報告推算出來的值12.78GB非常接近,可以說明以上兩份awr報告的可參考性很高。
現在已經確認是歸檔頻繁是由大量的redo引起的,那么就需要看在問題時間區間內,導致數據塊變化的原因(sql),這個可以從awr報告的“Segments by DB Blocks Changes”部分可以找到答案:
節點1:
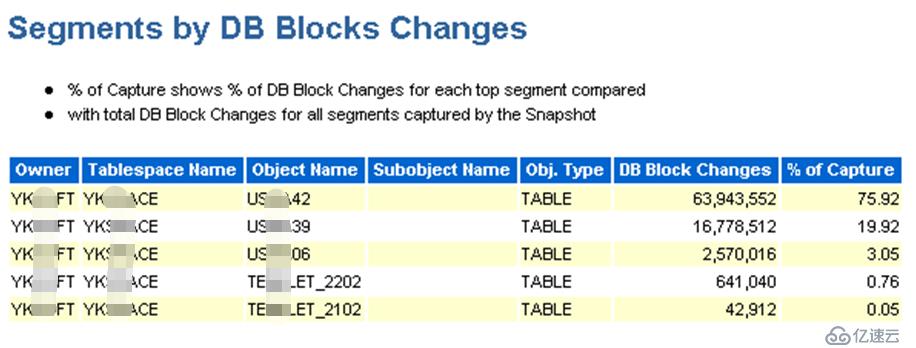
節點2:
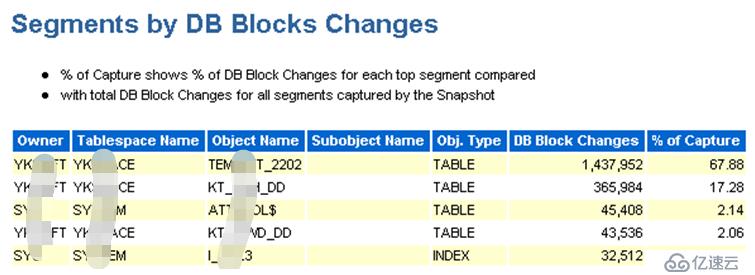
由上邊2個截圖可以發現,用戶YK***FT名下的有3個表(US***42、US***39、US***06)的數據塊被頻繁的操作,而這個用戶正是新遷入系統的數據庫用戶。
為了更進一步了解對該3個表做了哪些操作,可以在awr報告中分別搜索表名稱,找出相關的sql語句。
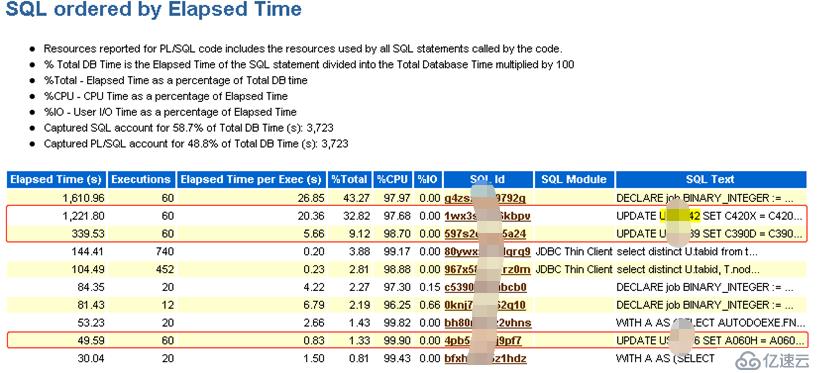
由上圖可以看出,在1小時之內,對該3個表分別執行了60次update操作,具體的sql語句如下:

這里注意到一個數字60,看樣子像是一個定時任務,首先想到的是job。經過查詢,發現yk***ft用戶下確實存在一個job,而且正好是每分鐘執行一次!
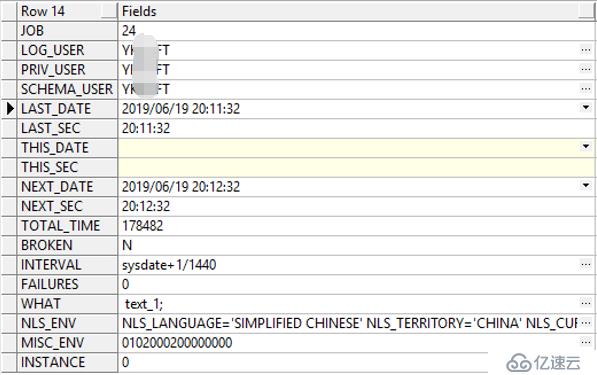
進一步查看job執行的存儲過程發現正是上邊的3條語句:
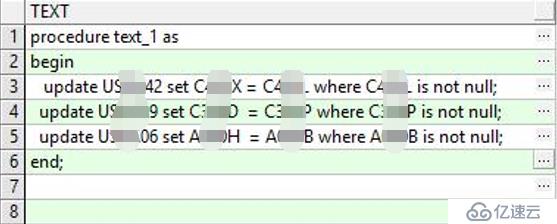
通過分析US***42、US***39、US***06這個3個表和update中的where語句,發現那3條update語句很有問題,符合where的數據量大,且只增不減,必須要調整。

根據前邊找到的線索,跟運維人員確認job(24)的業務作用,得到的反饋是之前有個需求是定期把符合要求的字段A的值寫到字段B,現在該需求已不再需要,可以刪除。
禁用job
雖然業務確認可以刪除,但為了保險起見,這里將job(24)禁用,通過調用dbms_job.broken完成。

觀察redo
這里選擇調整之后的6月20日上午10點到11點間集群2節點的awr報告
節點1:
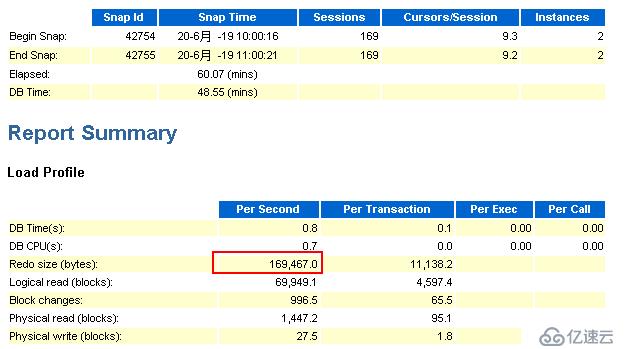
節點2:
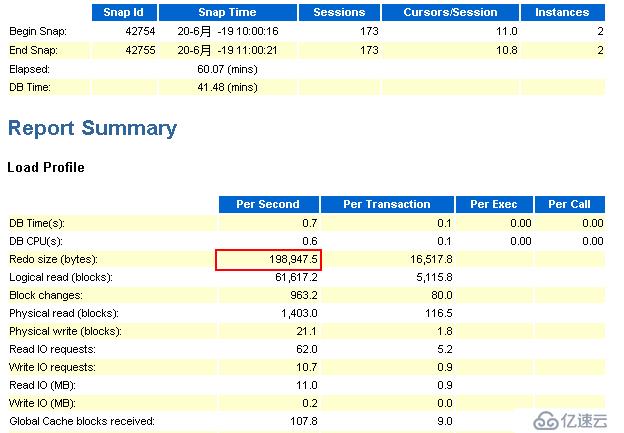
由上述節點1和節點2相同時間內的awr報告的來看,redo產生速率有了很大的降低。通過觀察歸檔日志的生成情況,發現歸檔頻率也降低了。
經過回顧整個問題的發現、分析和解決過程,可以發現其實并沒有什么技術難點,問題的原因主要還是出在業務溝通上。在遷移之前,最好能夠跟應用管理員確認清楚業務的特點,包括現有業務的壓力情況、已發現的性能瓶頸、不再需要的各類數據庫對象(索引、視圖、存儲過程、函數、觸發器等),提前做好應對措施,保證數據遷移的圓滿完成。

免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





