溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了怎么用Python讀取CSV文件,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
典型的數據集stocks.csv:
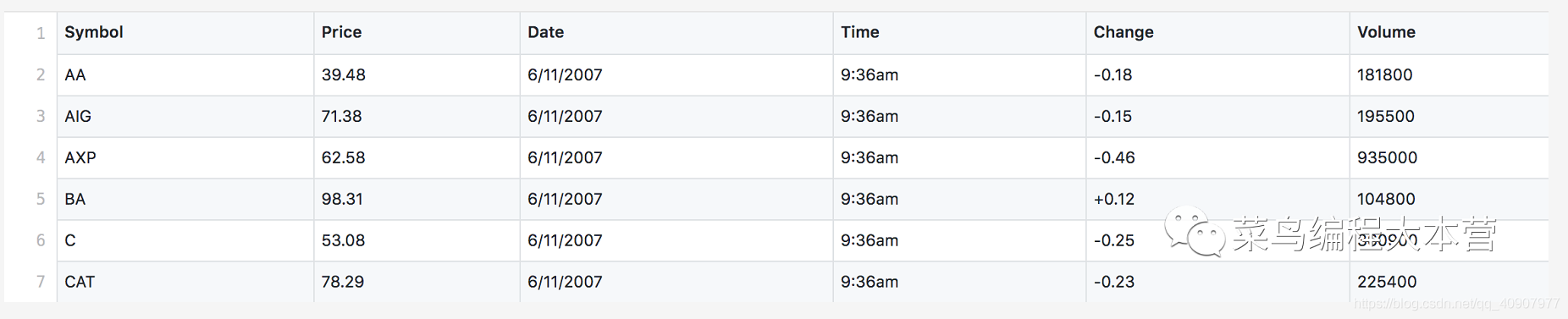
一個股票的數據集,其實就是常見的表格數據。有股票代碼,價格,日期,時間,價格變動和成交量。這個數據集其實就是一個表格數據,有自己的頭部和身體。
我們先來看一種簡單讀取方法,先用csv.reader()函數讀取文件的句柄f生成一個csv的句柄,其實就是一個迭代器,我們看一下這個reader的源碼:
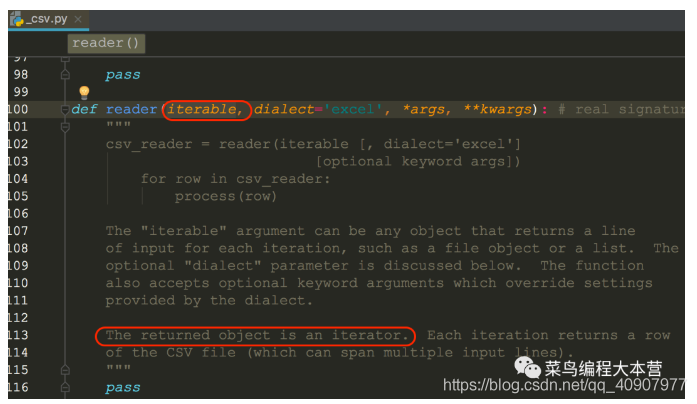
喂給reader一個可迭代對象或者是文件的object,然后返回一個可迭代對象。

首先讀取csv 文件,然后用csv.reader生成一個csv迭代器f_csv
然后利用迭代器的特性,next(f_csv)獲取csv文件的頭,也就是表格數據的頭
接著利用for循環,一行一行打印row的內容,也就是表格數據的身體

上面的第一招其實是最簡單的,下面我們用nametuple 來包裹一下這個生成的row數據。

nametuple其實是一個非常有用的類,這個類屬于collections模塊,而這個模塊簡直就是一個百寶箱里面有非常多的牛逼的庫;
這里我們用next(f_csv)其實就是獲取表格的頭部來初始化這個Row;
然后循環來構造這個Row的數據,把我們表格里面的每一行的數據都喂成nametuple格式的row_info;
這樣做的好處就是你可以隨心所欲的訪問這個row_info里面的數據,就想訪問類數據一樣,比如row_info.price
如果我們對csv數據每一行的類型都非常清楚的話,嘿嘿可以用一個設定好的數據格式轉換頭來對數據進行轉換。
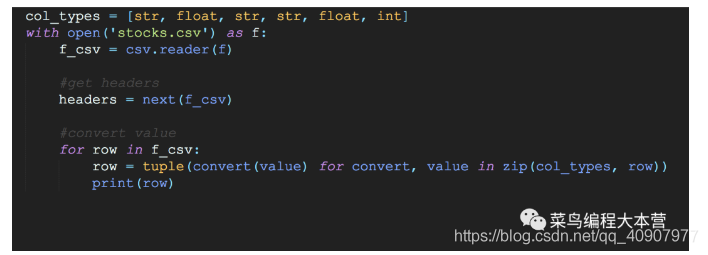
操作的步驟其實跟上面差不多,就是對數據結果的清洗處理稍微不一樣。這里非常巧妙的zip來構造一個嵌套的數據列表,然后用convert(data)把csv文件里面每一行的數據進行類型轉換,這招真的不錯!
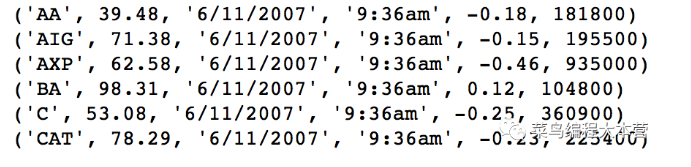
看一下結果:
上面用的nametuple其實也是一個數據的映射,有沒有什么方法可以直接把csv 的內容用映射的方法讀取,直接出來一個字典,還真有的,來看一下代碼:

是不是非常簡捷,原來csv模塊直接內置了DictReader(),按照字典的方法進行讀取,然后生成一個有序的字典,看一下結果:
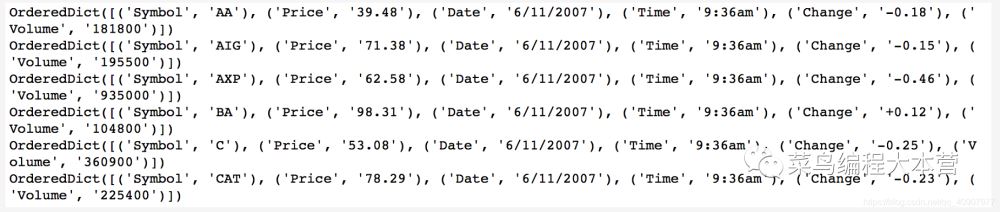
有興趣的可以看一下這個DictReader()的源碼,它其實一個內部構造的迭代器類,在內部的__next__其實也是用的OrderedDict(zip(self.fieldnames, row))來生成的。
如果我們需要對這個csv里面的數據進行清洗,因為讀出來的時候都是字符串,我們需要更新為特定的數據類型,這個時候也可以用字典轉換這一招,也是非常巧妙的,我們看一下源碼:

原來的數據價格Price和成交量,我希望最后讀取生成的是一個浮點型數據和整形的數據,這么搞呢,用一個字典來巧妙的更新key即可。
首先我們聲明一個自定義的類型轉換器field_types;
然后循環生成一個可迭代的對象(key,conversion(row[key]);
最后更新一下字典里面相同的key,比如row[‘price']的內容就會被更新了
感謝你能夠認真閱讀完這篇文章,希望小編分享的“怎么用Python讀取CSV文件”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





