溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“Python如何實現數據透視表”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“Python如何實現數據透視表”這篇文章吧。
用Python里的Pandas可以實現,雖然感覺Excel更方便
不夠直觀,不好看
對貸款年份,貸款種類創建數據透視
train_data.groupby(['year_of_loan', 'class']).agg(d_roat =('isDefault', 'mean'))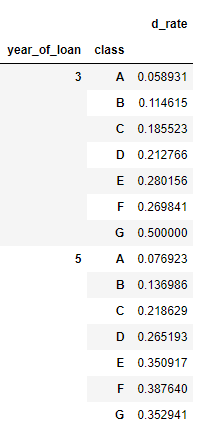
pandas.crosstab(index, columns,values, rownames=None, colnames, aggfunc, margins, margins_name, dropna, normalize)
主要用到的參數:
index:選哪個變量做數據透視表的行
columns:選哪個變量做數據透視表的列
values:要聚合的值
aggfunc:使用的聚合函數
margins:是否添加匯總列/行
margins_name:匯總行/列的名字
例子
對貸款年份,貸款種類創建數據透視
pd.crosstab(train_data['year_of_loan'], train_data['class'], train_data['loan_id'], aggfunc='count',margins = True, margins_name = '合計')
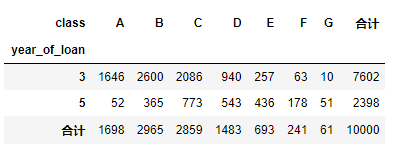
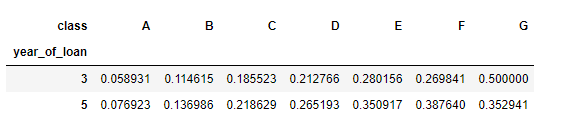
可以直接看出交叉組合之后違約比例
pd.crosstab(train_data['year_of_loan'], train_data['class'], train_data['isDefault'], aggfunc='mean')
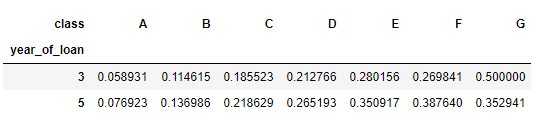
train_data.groupby(['year_of_loan', 'class'], as_index = False)['isDefault'].mean().pivot('year_of_loan', 'class', 'isDefault')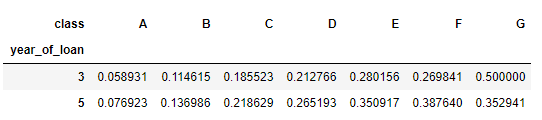
pandas.pivot_table(data, values, index, columns, aggfunc, fill_value, margins, dropna, margins_name, observed, sort)
常用參數與crosstab一致
例子
實現同樣的數據透視表
pandas.pivot_table(data, values, index, columns, aggfunc, fill_value, margins, dropna, margins_name, observed, sort)

pd.pivot_table(train_data[['year_of_loan', 'class', 'isDefault']], values='isDefault', index=['year_of_loan'], columns=['class'], aggfunc='mean')
以上是“Python如何實現數據透視表”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





