溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
最近繼續在看《Hadoop 2.X HDFS源碼剖析》,現在看到了第三章NameNode部分。NameNode在hdfs這種文件系統中充當著master的角色,負責的功能有很多比如文件系統目錄管理(命名空間管理)、數據塊管理、數據節點管理、租約管理、緩存管理等等。這次主要寫關于命名空間管理的筆記。
基本類型
hdfs中最基本的類應該就是INode了,無論是最后的目錄、具體文件、軟連接還是添加快照功能之后的引用都是這個類的子類,繼承關系如下圖所示
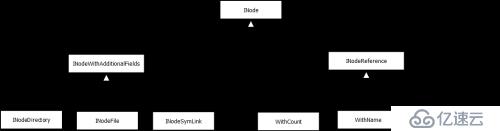
圖表一
INode:包括parent這個字段表明父INode,還提供了isFile()、isDirectory()、isRoot()這些接口;
INodeWithAddtionalFields:包括id、name、permission、features這些字段,進一步拓展基本信息;
INodeFile:在父類的基礎上定義了header以及bolcks(BlockInfo[]類型),對應的feature可以表示是否在構建中(underconstruction),是否有快照(snapshot);
INodeDirectory:在父類的基礎上增加了childern字段,表明所有的子INode,對應的feature可以有是否有快照(snapshot),是否有限額(quota);
INodeReference:這個類以及子類主要是在開啟快照功能的時候使用,在介紹之前首先介紹一下快照,所謂快照就是保存這個目錄當前狀態,這樣不論以后對這個目錄里面的文件做了刪除、增加還是重命名,都可以通過快照獲取這個時間下目錄的所有文件;
就像下面的圖表二所示

圖表二
在t0時,存在文件/A/TXT,并且建立了對應時間/A目錄的快照snapshot:t0,那么當t0之后將TXT移動到/B目錄的時候,直接訪問A是找不到文件的,但是可以通過訪問/A這個INodeWithAdditionalFields對象的feature數組,訪問到t0時刻的快照,接著就可以根據相應的INodeReference對象,找到TXT文件現在對應的位置。
這里WithName可以理解為文件修改之前的位置,DSTReference可以理解為文件修改之后的位置,他們都會指向一個WithCount,但是WithName跟前者可以使多對一的關系,因為可以存在多個保存了TXT這個文件的快照,而只能有一個DstReference表示這個文件當前的路徑(WithCount的parent對象就是DstReference),最后WithCount指向了真正的文件/B/TXT。
關于日志
關于日志的細節很多,但是印象最深的地方只有如下兩點(或許是我看的不夠深入吧、[捂臉]):
1) 日志采用雙緩沖的方式,同時進行邏輯以及物理IO:
這個緩沖區是由Ready(磁盤IO)以及Current(內存IO)兩個部分組成的,寫日志的線程,負責將日志寫入Current中,而當Current寫滿了,需要保存到硬盤上的時候,將兩塊區域調換名字即可,這樣日志持久化的操作不會影響當前日志的寫入操作;
2) 由于可以存在多個寫入日志的地方,調用寫日志的時候使用一個保存所有輸出流的集合journalSet進行調用,很方便:
journalSet對象有一個selectInputStreams的方法,用于選擇需要輸出的日志輸出流,這樣就把journalSet與需要輸出的流綁定到一起了,接著直接調用journalSet.startLogSegment方法開始寫入日志。
關于FSImage
這個類負責保存命名空間到磁盤、啟動時加載fsImage文件以及加載editlog文件:
1) 保存命名空間:
保存的命名空間按照以下格式將內存中的內容,保存到磁盤中,如圖表三所示

圖表三
MagicNumber:魔數已經在很多技術中被采用了,相當于標識這個文件是哪種類型的文件,例如class文件的'CAFEBABE';
Sections:這是真正記錄內存中數據的部分,例如INode信息、cache信息、快照信息等等;
FileSummary:這部分相當于sections的元數據,描述著每個section的長度以及起始位置;
FileSummaryLength:這部分描述FileSummary的長度。
啟動的時候NameNode重后往前,先看FileSummaryLength,然后讀取FileSummary,然后在根據各個section的元數據將Section加載到內存中,MagicNumber對應'HDFSIMG1'。
2) 關于檢查點
為了防止加載過大的editlog文件而導致的namenode啟動太慢,向數據庫里面一樣,hdfs也有自己的檢查點機制(當然沒了數據庫之中的回滾段什么的,所以還比較簡單)。
在非HA的情況下,檢查點操作都是由SecondaryNamenode進程操作的,然而在HA的情況下,都是由standbynamenode進行檢查點操作,操作完成之后再傳遞給active namenode。
以上情況都是hadoop2.6.0中namenode的實現,版本不同具體實現也會不一樣。相關截圖已經打包上傳。
2017.2.19
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





