溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“如何實現mysql重復記錄數據的排查處理”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
前言
分析
數據總計
重復次數占比
where 和 having 的區別
總結
客戶當時直接一摞重復標簽的盒子碼在我面前,我慌得一匹,這怕不是捅婁子了
稍加思索,現在需要做的就是,在數據庫中查詢出重復的標簽,即對一個標簽進行統計,判斷出計數> 1 的即可
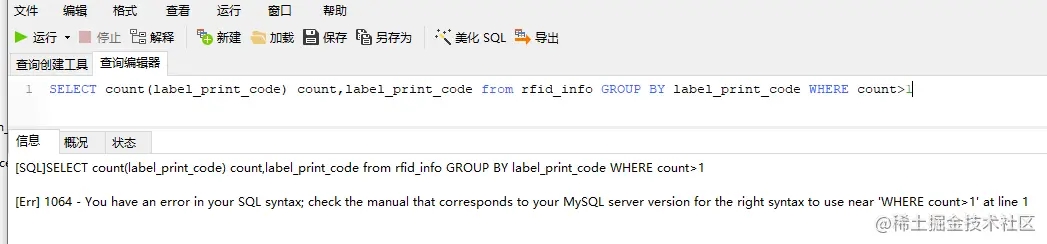
emmm,語法錯誤,我記得還有個Having 來著,換上試試
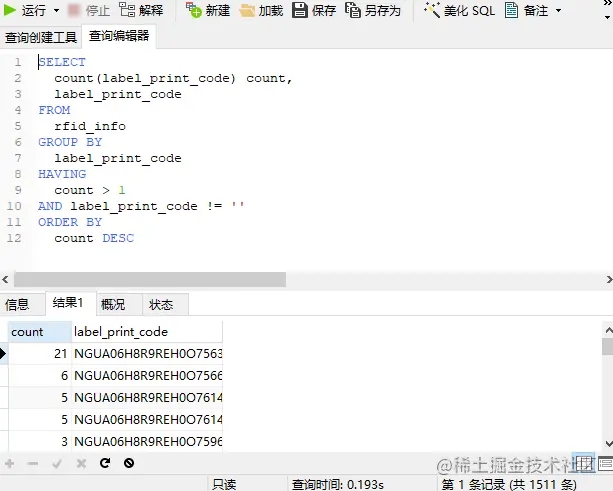
好家伙,重復的標簽有 1500 多條,再統計一下總共問題的記錄數量,以及再分組看看標簽重復次數的占比數據
對了,先把這些重復標簽數據扔個客戶去追溯產品(幸好 navicat 支持復制數據)
以上一條查詢記錄的結果為臨時表,在此基礎上,用 sum() 求和
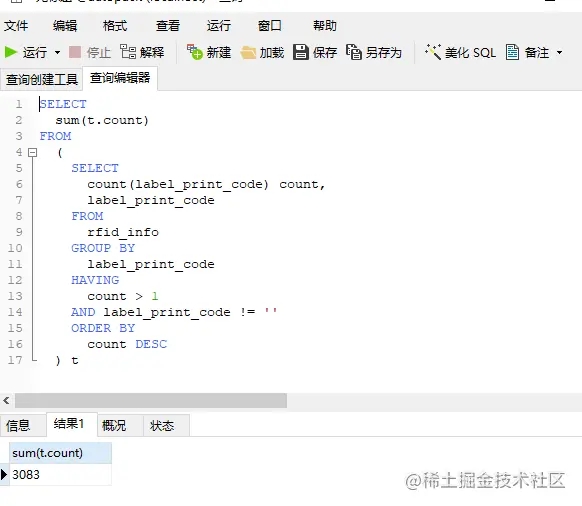
重復的記錄有點多,這問題有一點點大了
對之前的查詢表換一個查詢方式,即對 count 數據再次分組
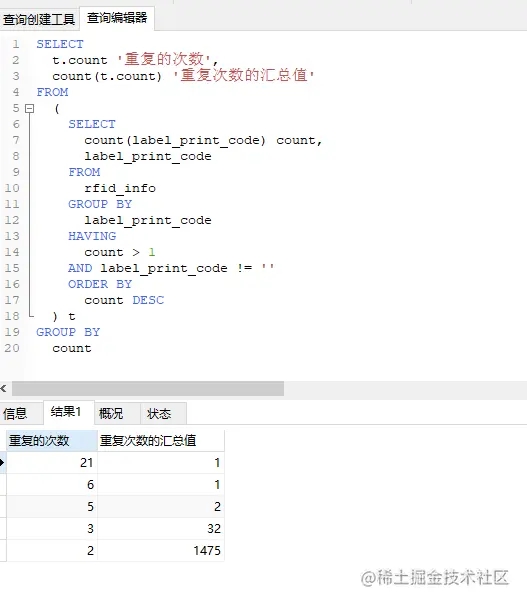
從結果來看,絕大部分問題數據重復了2次
Where是一個 約束聲明,在查詢數據庫的結果返回之前對數據庫中的查詢條件進行約束,即在結果返回之前起作用,且where后面 不能使用聚合函數
Having是一個 過濾聲明,所謂過濾是 在查詢數據庫的結果返回之后進行過濾,即在結果返回之后起作用,并且having后面可以使用聚合函數。
所謂 聚合函數,是對一組值進行計算并且返回單一值的函數:sum---求和,count---計數,max---最大值,avg---平均值等。
“如何實現mysql重復記錄數據的排查處理”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





