溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹C語言的數據類型有哪些,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
1.整性
char //字符本質上是整型,只是char類型值截斷開辟一個字節 unsigned char signed char short //2字節 unsigned short [int] signed short [int] int //4字節 unsigned int signed int long //4字節 unsigned long [int] signed long [int]
2.浮點型
float double
3.構造類型
數組類型 結構體類型 struct 枚舉類型 enum 聯合類型 union
4.指針類型
int* pi; char* pc; float* pf; void* pv; ...
5.空類型
void
在C語言中,隱式類型轉換是編譯器自發的行為,它往往是從小到大的轉換,在數據類型上表現是少字節數據類型,轉換成多字節數據類型,保證數據的完整性;(面向對象語言也有該概念,并且對于類也會有隱式類型轉換)一般來說,隱式類型轉換大體分為兩種:整性提升和類型轉換
1.定義: C的整型算術運算總是至少以缺省整型類型的精度來進行的。為了獲得這個精度,表達式中的 字符(char類型1字節) 和 短整型(short int類型2字節) 操作數在使用之前被轉換為 普通整型(int類型4字節) ,這種轉換稱為整型提升。
通俗來說:無論數據類型是否為 char 、short int 、…,其在讀取到CPU進行計算時,都會先通過整性提升到32位計算,而結算結果的讀取位數取決于讀取的數據類型,若為char類型,則截斷取8位(bit).
【這里注意:通常CPU在計算時,用的數據是源碼已翻譯后的補碼來計算】
2.整性提升是按照變量的數據類型(指自身類型,而不是數值類型)的符號位來提升
//eg1.負數的整性提升 char a = -1; //char類型默認為有符號類型 //其二進制源碼為:1 000 0001 // 補碼為:1 111 1111 //整性提升時,由于8bit的char類型數據中符號位為1; //故提升為32位后 11111111 11111111 11111111 11111111;(補碼) //eg2.正數的整性提升 char a = 1; //其二進制源碼為:0 000 0001 // 補碼=源碼為:0 000 0001 //整性提升時,由于8bit的char類型數據中符號位為0; //故提升為32位后 00000000 00000000 00000000 00000001;(補碼)
3.截斷的具體體現:
//eg3.
char c = -129;
printf("%d",c);結果為:127
原因是:-129源碼為:1000 0000 0000 0000 0000 0000 1000 0001
在內存中的補碼為:1111 1111 1111 1111 1111 1111 0111 1111
而字符變量c 只截斷8bit位 即c變量保存的是:0111 1111(補碼)
輸出d%位整型,且符號位為0
整型提升為0000 0000 0000 0000 0000 0000 0111 1111(補碼)
轉為源碼即為127
【注意這里的截斷原則與機器大小端有關,且截斷是在內存上對補碼進行操作】
1.概念:操作符兩邊的操作數屬于不同的類型,那么除非其中一個操作數的轉換為另一個操作數的類型,否則操作就無法進行;而這種轉換就是類型轉換(編譯器自發)
2.從下至上,自動轉換
long double double float unsigned long int long int unsigned int int
3.【注意】這種類型轉換只是建立在運算操作符之間,不然會出現不合理問題
eg4. float f = 3.14; int num = f;//隱式轉換,會有精度丟失
賦值情況下導致在高位的float類型轉為低位的int類型,導致精度丟失
小端(存儲)模式,是指數據的底位(低權值)保存在內存的底地址中,而數據的高位(高權值),保存在內存高地址中;
【大多數機器都采用小端模式】
大端(存儲)模式,是指數據的底位(低權值)保存在內存高的地址中,而數據的高位,保存在內存低地址中;
上文的eg3.中出現了截斷,即字符c截斷整型數值-129
//eg3. char c = -129;
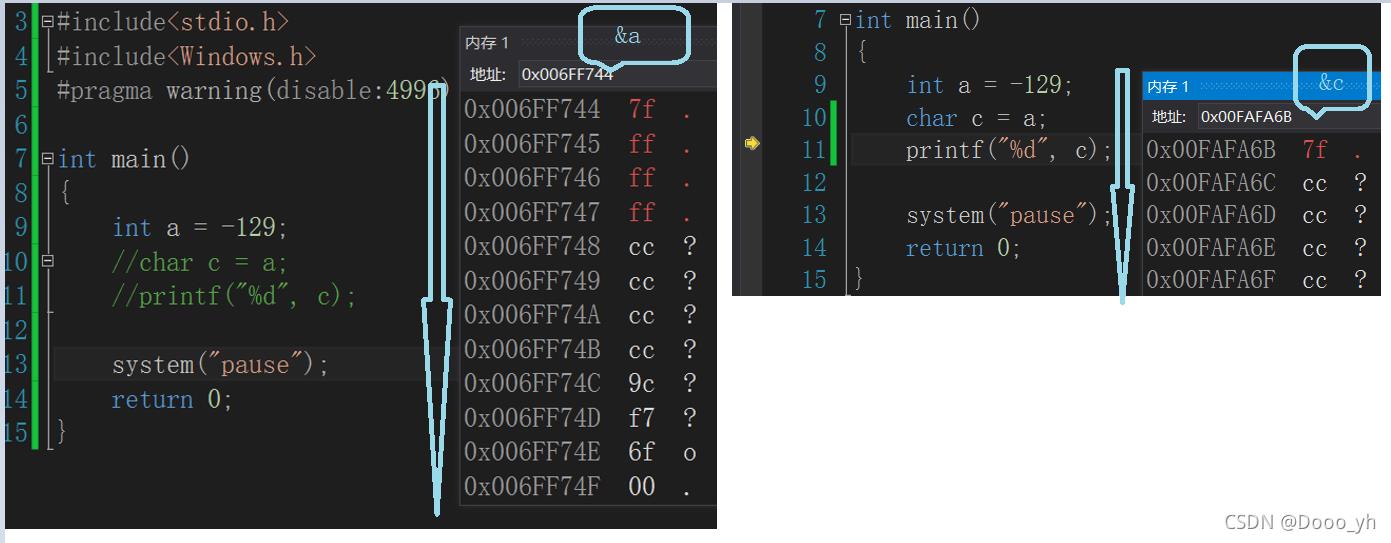
我們將代碼中的整型a變量在內存的地址儲存數據顯示出來,從內存地址可以看出,序列從高到低遞增
a:補碼為 1111 1111 1111 1111 1111 1111 0111 1111
轉為16進制后即為 ff ff ff 7f;(權值左邊最高,右邊最低)
再將字符變量c內存的地址儲存數據顯示出來,可以看出,由于char類型只有一字節,會優先從四字節a中截斷地址最低的一字節
由圖看出它截斷了低地址里的數據7f,而7f也是低權值。
故,在vs2013中,采用的是小端原則
#include<stdio.h>
#include<Windows.h>
#pragma warning(disable:4996)
int check_sys()
{
int i = 1;
return (*(char*)&i);//注意,發生數據類型轉換
}
int main()
{
int ret = check_sys();
if (ret)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
system("pause");
return 0;
}【注意】(*(char*)&i);
這里是對指針的解引用時,從內存所取的字節大小由其指向的數據類型決定。 說白了就是 i 的地址從int *被強轉為char *,再解引用時,其指向的數據類型從int變為char,因此顯示的數據會發生截斷;
由上面的截斷方式我們可以知道,1在內存是以32位存儲的,按一字節來說,其高權值位為0、低權值位為1.故可以通過return傳參的1或0判斷大小端。
一個數在計算機中的二進制表示形式, 叫做這個數的機器數。機器數是帶符號的,在計算機用一個數的最高位存放符號, 正數為0, 負數為1.
比如,十進制中的數 +3 ,計算機字長為8位,轉換成二進制就是00000011;
如果是 -3 ,就是 10000011
在C語言中,整型在計算機的儲存情況是按原反補的規則儲存,即對于整型來說,數據存放在內存中其實是補碼。
計算機采用這種規則可以使數據運算時的+ - * / 運算都通過加法解決,這樣設計的計算機只需設計出加法模塊,大大節省成本。
具體規則如下:
1.正數
正數的原、反、補碼都相同,與原碼一樣
2.負數
原碼:該數的機器數,最高位為符號位
反碼:原碼除符號位不變,其余位按位取反
補碼:反碼+1
//例1.嘗試判斷輸出結果是什么
int main()
{
char a = -1;
signed char b = -1;
unsigned char c = -1;
printf("a=%d,b=%d,c=%d\n", a, b, c);
system("pause");
return 0;
}結果:

例1解析:
-1在內存的補碼:1111 1111 1111 1111 1111 1111 1111 1111
char a 、signed char b 、unsigned char c 存放時發生截斷,其在內存的補碼均為:1111 1111
但是三位在以%d(整型)輸出時,會發生整型提升,由原來的8位整型提升到32位,而整型提升時高位補0還是補1需看數據自身類型(有符號類型補符號位,無符號類型直接補0)
char a 與 signed char b 均屬于有符號型,且符號位為1,補24位1
內存數值為:1111 1111 1111 1111 1111 1111 1111 1111;輸出%d時反向推回原碼,答案即為 -1
unsigned char c 屬于無符號型,補24位0
內存數值為:0000 0000 0000 0000 0000 0000 1111 1111;輸出%d時反向推回原碼,答案即為 255
//例2.嘗試判斷輸出結果是什么
int main()
{
char a = 128;
char b = -128;
printf("a=%u,b=%u\n", a,b);
system("pause");
return 0;
}結果:
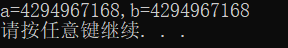
例2解析:
128在內存的補碼:0000 0000 0000 0000 0000 0000 1000 0000
-128的內存補碼: 1111 1111 1111 1111 1111 1111 1000 0000
char a 、char b 存放時發生截斷,其在內存的補碼均為:1000 0000
%u(無符號整型)輸出時,會發生整型提升,由原來的8位整型提升到32位
char a 與 char b 均屬于有符號型,且符號位為1,補24位1
內存數值均為:1111 1111 1111 1111 1111 1111 1000 0000;輸出%u時反碼直接當原碼,
答案即為 :
//例3.嘗試判斷輸出結果是什么
int main()
{
int i = -20;
unsigned int j = 10;
printf("i+j = %d\n", i + j);
system("pause");
return 0;
}結果:

例3解析:
-20在內存的補碼:1111 1111 1111 1111 1111 1111 1110 1100
10在內存的補碼:0000 0000 0000 0000 0000 0000 0000 1010
int i 與 unsigned int j 都是四字節類型變量故存儲時不會發生截斷,
但 ·i + j = 表達式會發生類型轉換,int 會自動轉換為 unsigned int 類型計算
CPU中將兩變量補碼進行相加得到:1111 1111 1111 1111 1111 1111 1111 0110
計算結果以%d(整型)輸出,反向推回原碼:1000 0000 0000 0000 0000 0000 0000 1010
答案即為 -10
//例4.嘗試判斷輸出結果是什么
int main()
{
unsigned int i;
for (i = 9; i >= 0; i--)
{
printf("%u\n", i);
}
system("pause");
return 0;
}結果:
例4解析:
由于 i 變量時 unsinged int 類型,因此其無符號位,
且 ·i >= 0 表達式會發生類型轉換,int 0 會自動轉換為 unsigned int 類型計算
故其比較結果永遠為真,因為無符號類型第32bit位(符號位)永遠為0
for 循環條件永遠滿族,答案即為死循環
//例5.嘗試判斷輸出結果是什么
int main()
{
char a[1000];
int i;
for (i = 0; i <1000; i++)
{
a[i] = -1 - i;
}
printf("%d\n", strlen(a));
system("pause");
return 0;
}結果:

例5解析:
char a[1000]數組的每一位元素都是1字節的 char 類型,有字符位,故其保存的數值范圍:[-128,127];
-1-i 范圍從 -1到 -1000,但在循環體 a[i] = -1 - i中每次賦值都會發生截斷,由下圖可知,char類型保存的數值依次遞減時,-1 繼續減到 -128 ,128 減一位到 127,127 繼續減到0,0再減一位到 -1,繼續下一輪循環;
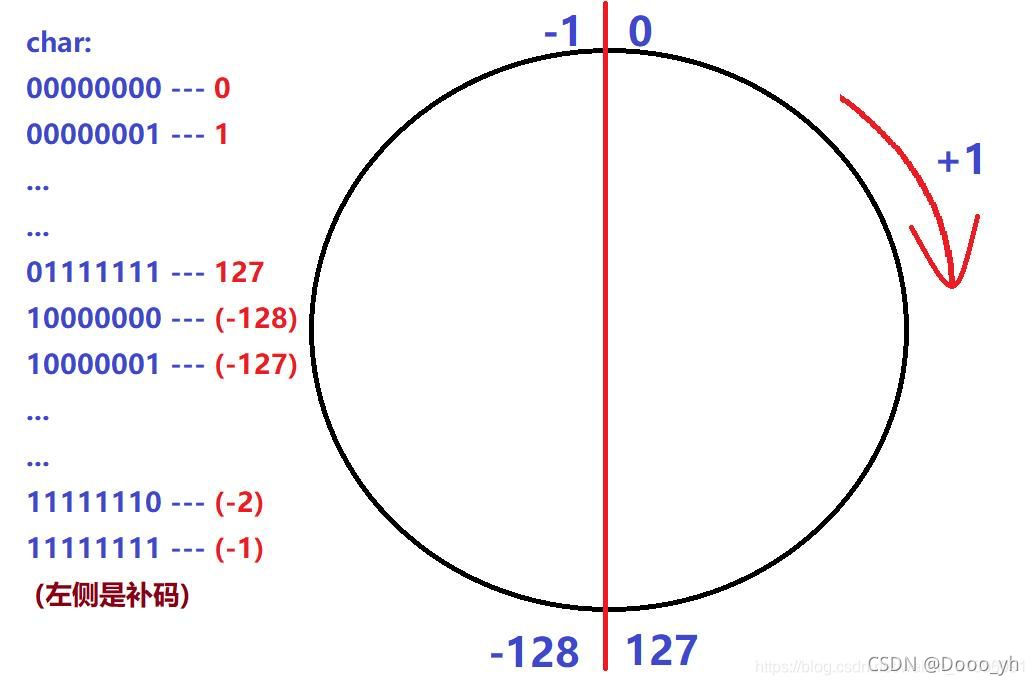
而該題的輸出時數組字符長度,strlen遇 ‘\0'(等價于數值0),而在初始化后的char a[1000]數組中,數值第一次出現0在a[255];
故答案為255
//例6.嘗試判斷輸出結果是什么
int main()
{
unsigned char i = 0;
for (i = 0; i <= 255; i++)
{
printf("%d ", i);
Sleep(30);
}
system("pause");
return 0;
}結果:0-255無限循環
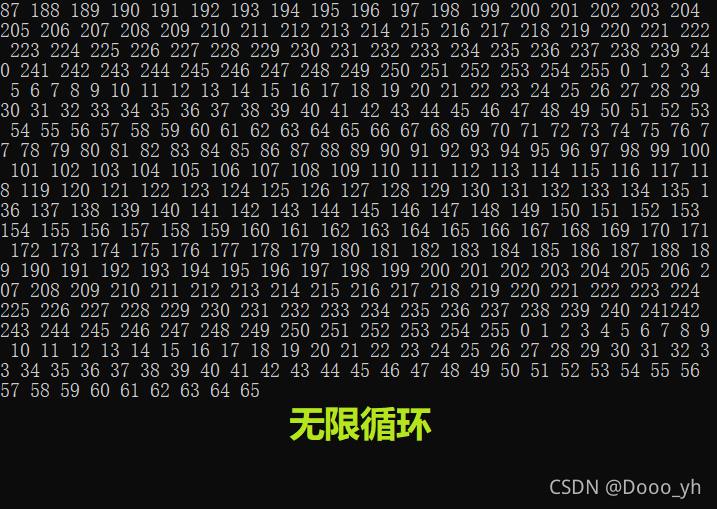
例6解析:
由例5解析的圖可知:unsigned char 類型的變量 i 的取值范圍:[-128,127],永遠小于255;
而%d輸出時,無符號類型直接整型提升補24位0:
0000 0000 (0)轉為 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000(補),補碼轉原碼:符號位為0,原碼與補碼一樣,值為0;
1000 0000(-128)轉為0000 0000 0000 0000 0000 0000 0000 0000 1000 0000(補),補碼轉原碼:1000 0000 0000 0000 0000 0000 1000 0000,值為128;
0111 1111(127)轉為0000 0000 0000 0000 0000 0000 0000 0111 1111(補),補碼轉原碼:符號位為0,原碼與補碼一樣,值為127
由此可知,無符號字符類型變量整型提升后再%d輸出沒有負數
故答案為:0-255循環
以上是“C語言的數據類型有哪些”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





