溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
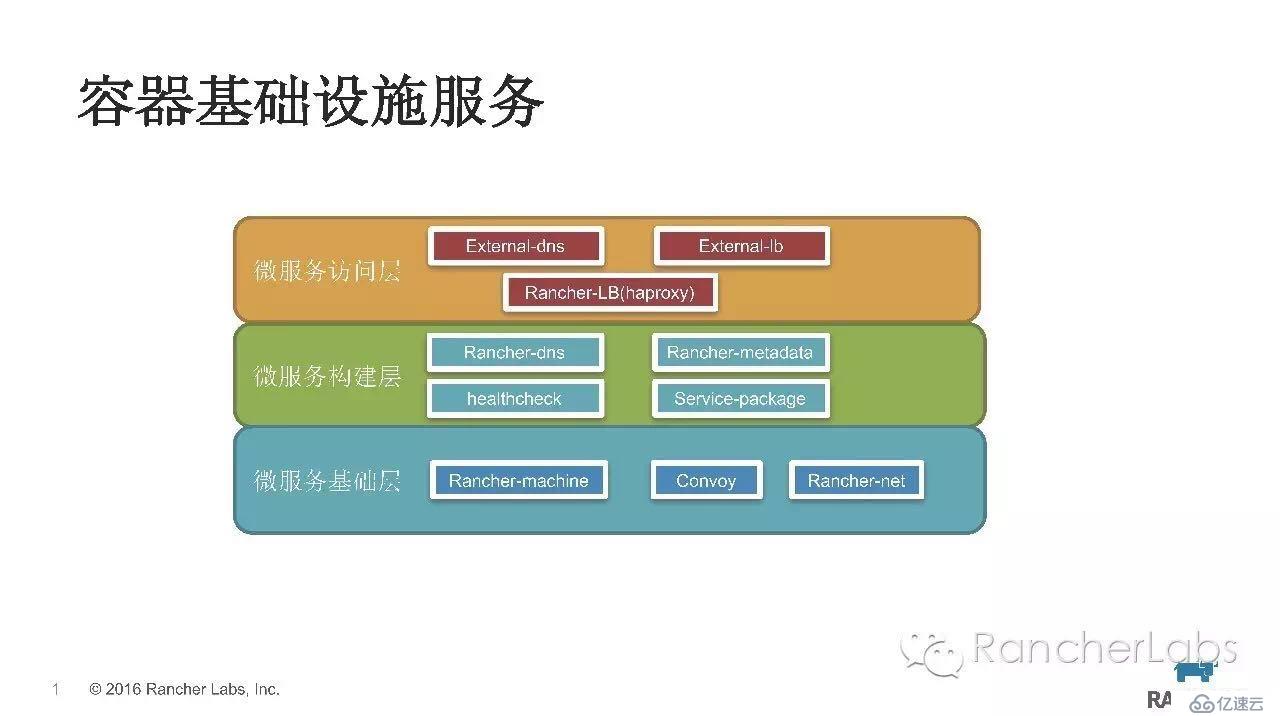
站在微服務的角度看容器的基礎設施服務可以分為三層:
微服務基礎層
微服務構建層
微服務訪問層
Rancher的服務發現就是基于rancher-dns來實現,創建的stack&service都會生成相應的DNS記錄,用戶可以通過相應的規則進行訪問,這樣在微服務之間就可以無需知曉各自的IP地址,直接用服務名進行連接即可。
微服務基礎層主要是為容器提供計算、存儲、網絡等基礎資源。主機計算資源主要是對docker-machine封裝來提供相關服務;容器存儲通過Convoy組件來接入,目前對NFS協議的存儲適配性最佳;容器之間的網絡通過rancher-net組件實現,目前支持ipsec overlay,在Rancher1.2版本會支持CNI標準的網絡插件。
微服務構建層,除了有微服務本身主體程序,還需要有一些額外的輔助工具來完善對應微服務的架構體系。rancher-dns來實現服務發現機制;rancher-metadata可以靈活動態向微服務所在容器中注入一些配置數據;healthcheck來保證微服務的高可用;同時我們還需要有微服務打包的工具,保證微服務可以在任意環境拉起運行。
微服務訪問層,目前服務對外暴露訪問主要以DNS綁定或是負載均衡VIP方式。Rancher提供external-dns、external-lb框架可以讓高級用戶hack自身的場景需求,external-dns除了支持公共的DNS服務(如route53),還支持內部DNS服務器(如bind9),而external-lb目前支持F5設備。除此之外,Rancher內置的負載均衡是基于Haproxy實現的,支持L4-L7。
本次分享,我將會以概念介紹原理講解并穿插一些實際案例這樣的方式進行分享。

Rancher的元數據服務rancher-metadata靈活性非常大,比較復雜的微服務架構可以通過metadata實現一定程度的解耦,尤其是confd+metadata會有意想不到妙用,這部分內容可以參考 http://niusmallnan.github.io/_build/html/_templates/rancher/confd_metadata.html

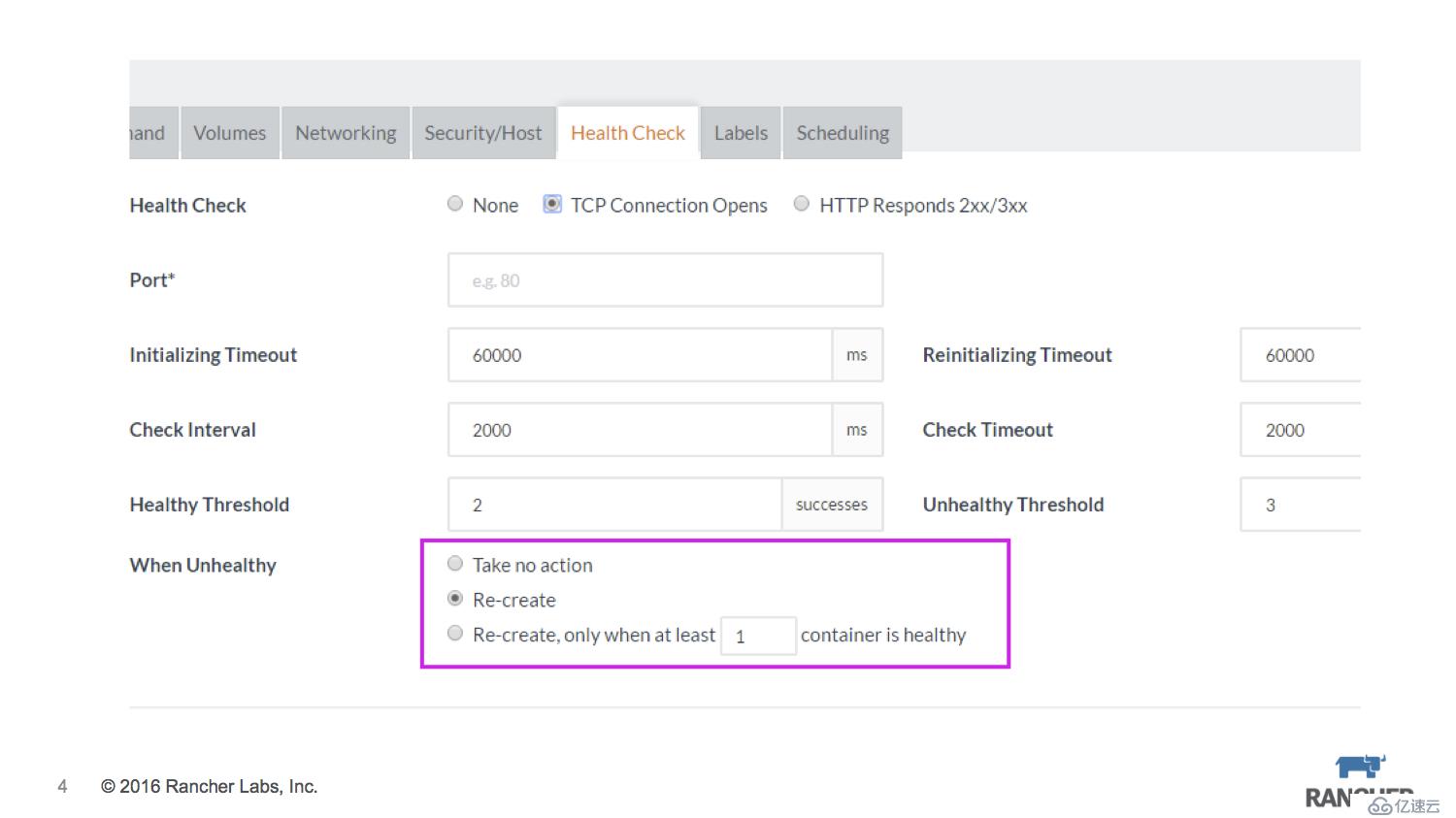
Rancher的healthcheck基于Haproxy實現,支持TCP/HTTP,當unhealthy觸發時按照預先設置的策略執行:
什么也不做
按照scale的容器數量重建
保證至少x個healthy的容器數量
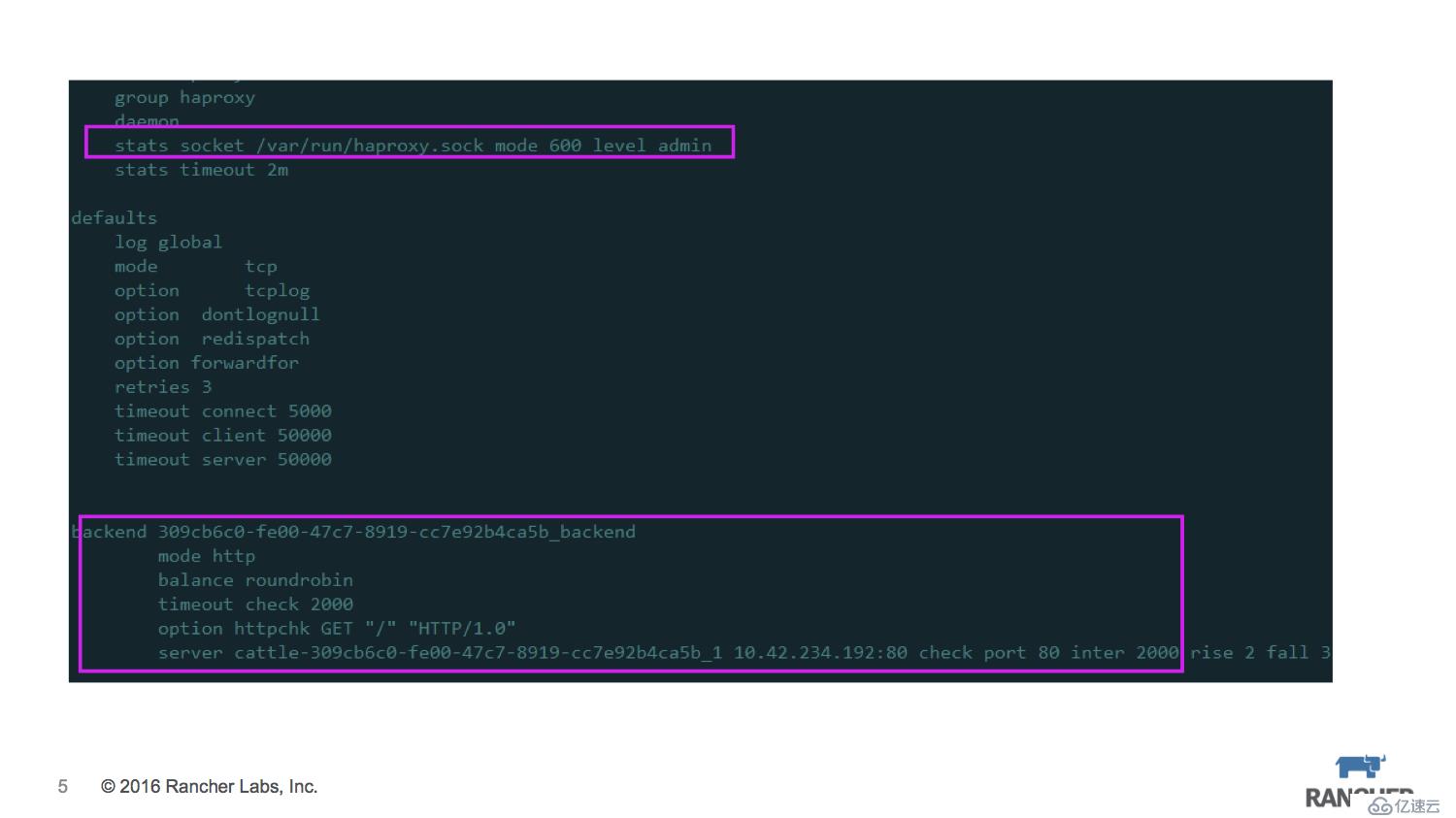
當針對某個service創建healthcheck策略后,service中容器所在的agent節點上會啟動Haproxy服務,同時把healthcheck的配置轉化為Haproxy的配置。如圖中所示添加了backend,其對應的ip就是container的ip。此外還要將Haproxy的stats scket暴露出來,以便讀取backend的狀態信息。
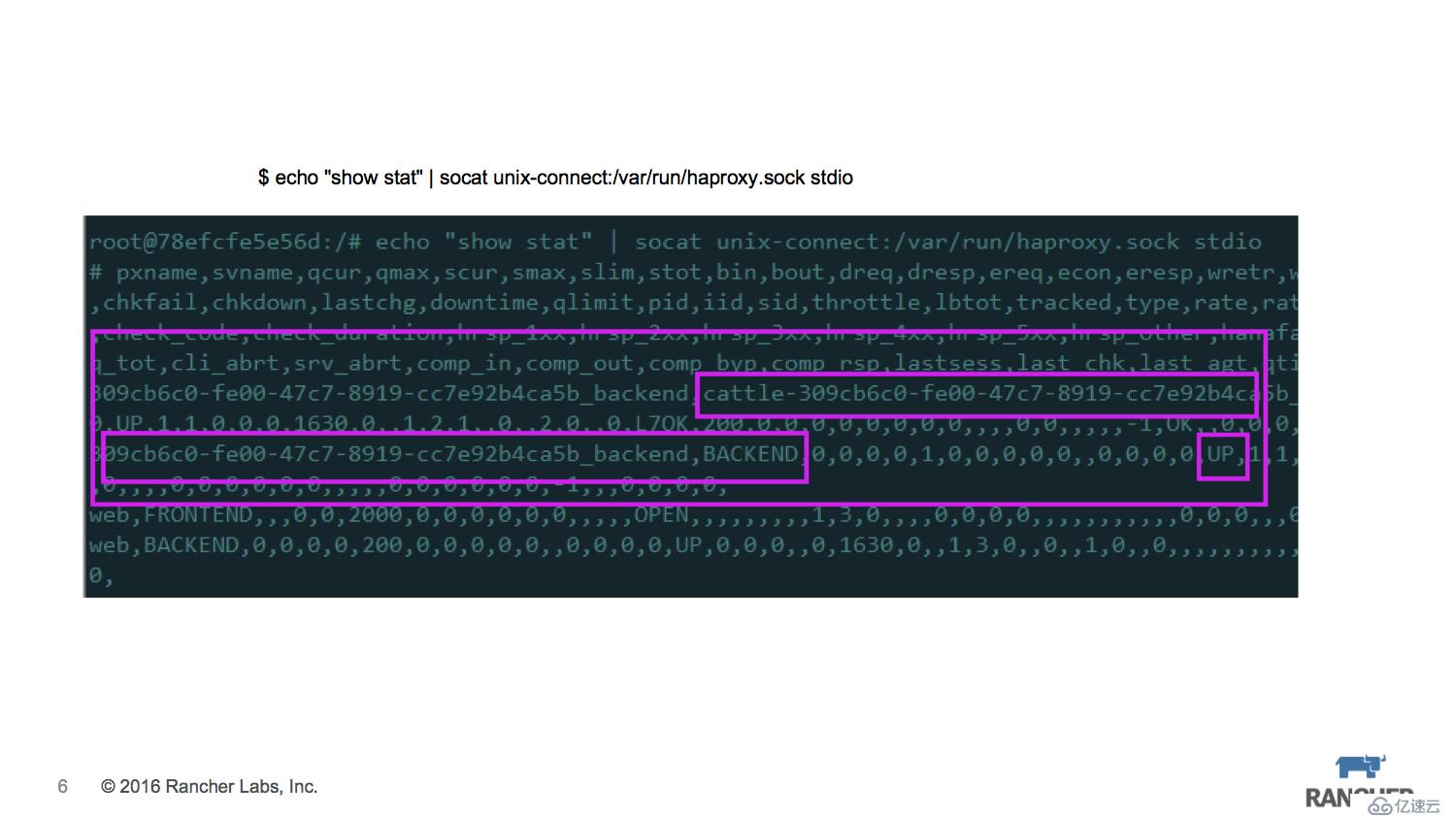
我們可以在外部程序中與Haproxy sock通信,可以獲取相關backend的狀態信息,由于我們在Haproxy中設置check機制,所以backend的狀態是會自動更新的。
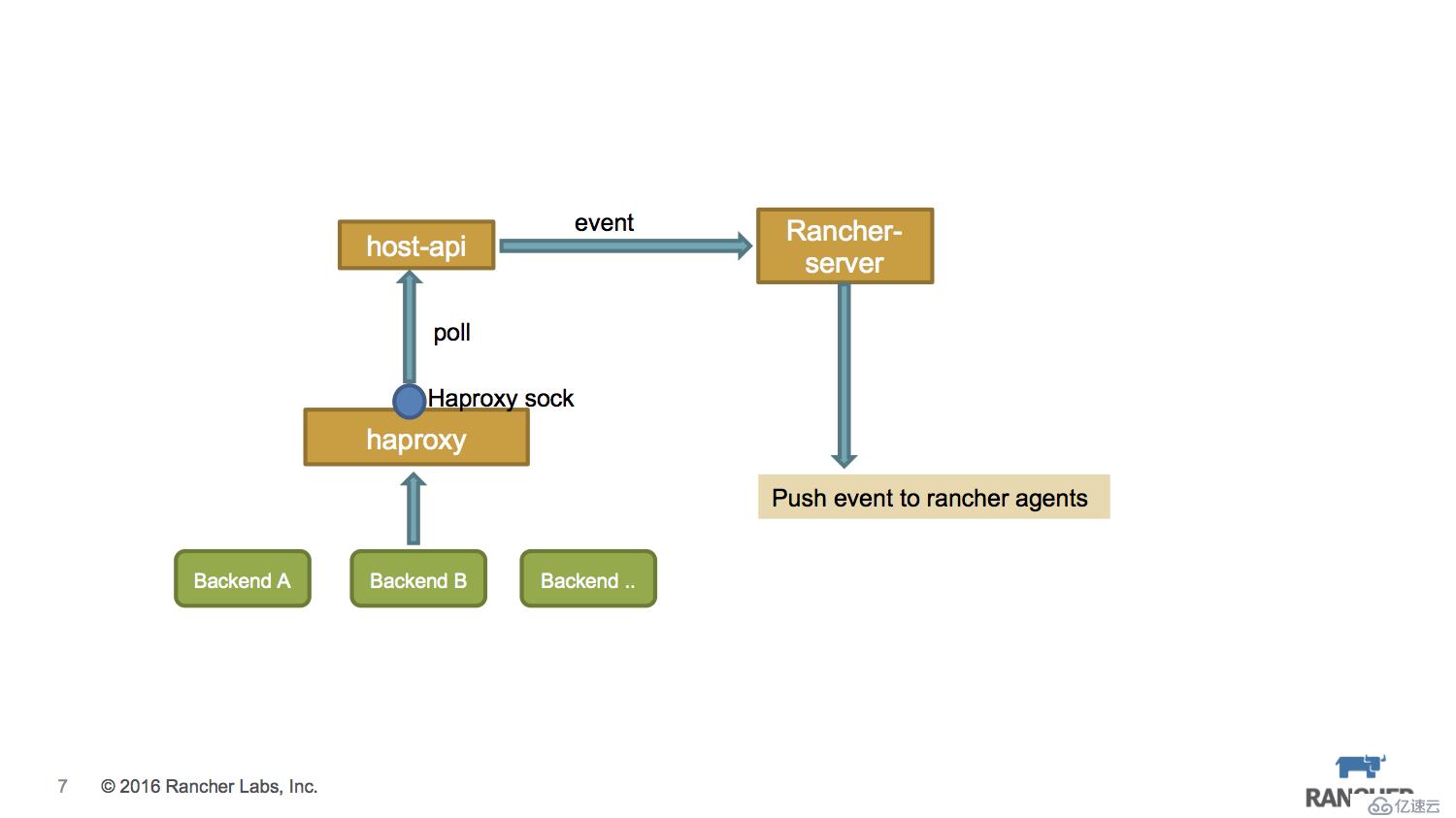
Rancher Agent上運行的host-api組件通過Haproxy sock來讀取backend狀態信息,同時通過rancher event機制把狀態信息push給rancher-server,rancher-server根據之前設置的healthcheck策略,來控制相關的rancher agent執行container recreate操作。
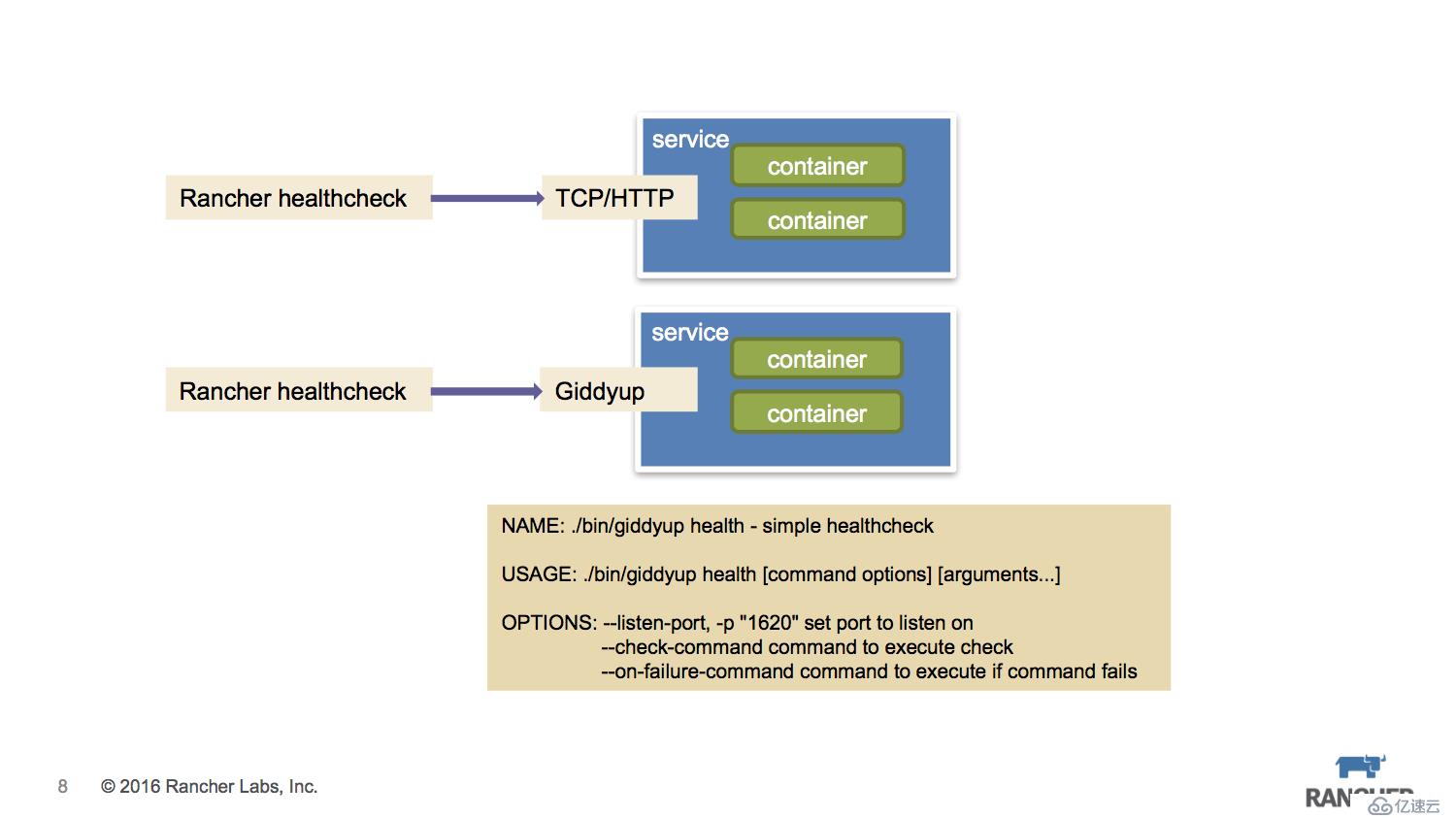
如果微服務本身是自帶服務端口(TCP/HTTP),那么healthcheck規則很好設置,只要正常填寫表單項就可以。但實際應用中有些微服務并不會有端口暴露,它可能只是一個與DB交互的程序,這時我們會考慮讓服務本身不要有大的代碼改造,所以就需要用一些小工具來輔助一下。

微服務的訪問入口,除了我們熟知的LB方式,還可以通過綁定DNS來實現,尤其是在私有云場景下,內部DNS的使用其實比單純使用LB暴露IP+Port方式更加簡潔,因為這樣無需考慮微服務的容器漂移導致的服務IP出現變化。
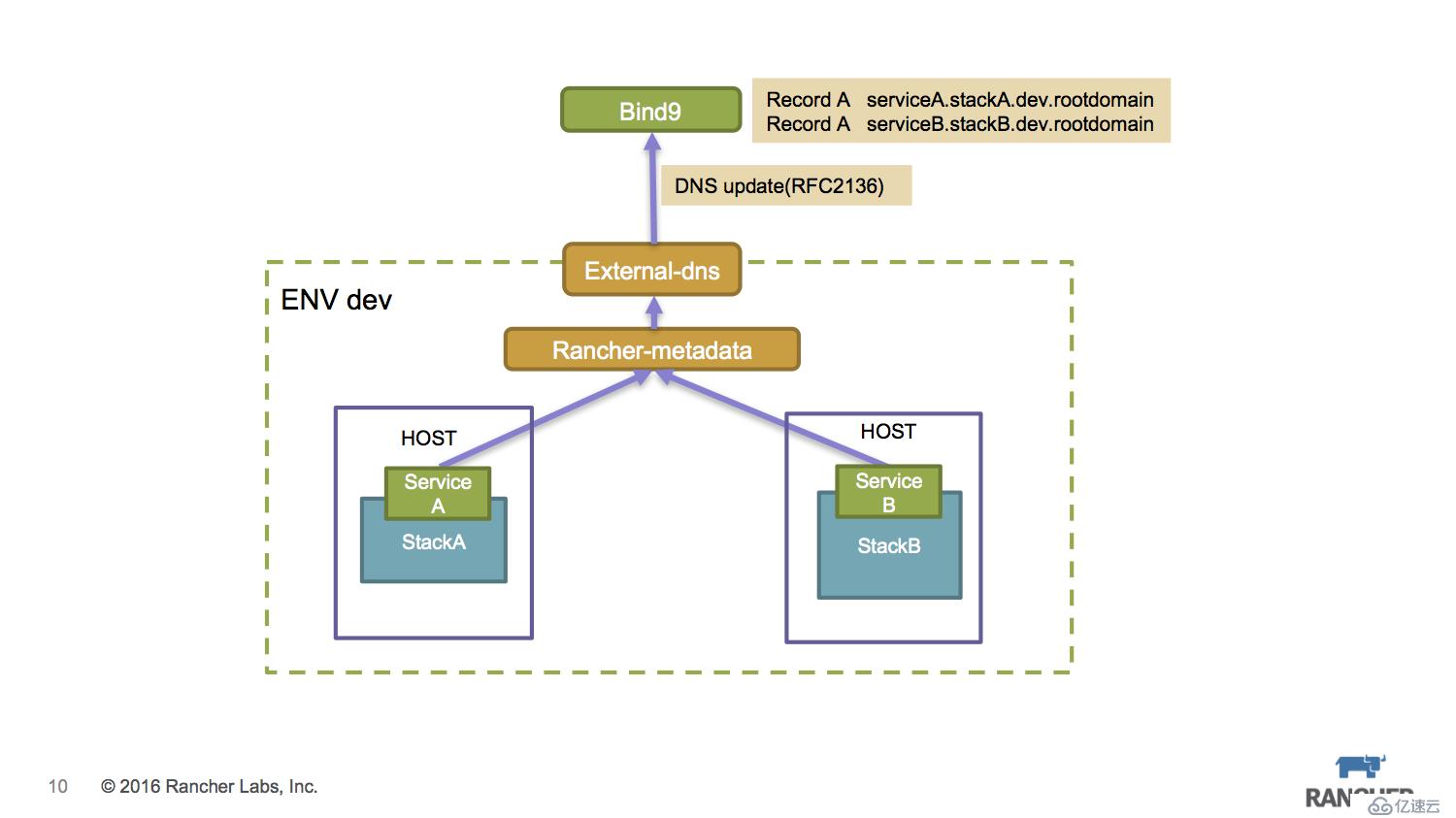
Rancher提供了一個external-dns框架 https://github.com/rancher/external-dns,它可以實現service的服務地址轉換成DNS的記錄。

私有云場景中,很多行業用戶在內部都使用F5硬件負載均衡來暴露服務訪問地址。微服務的改造我們盡量控制在程序架構層面,而原有的網絡結構盡量不要改變,那么就會引來一個微服務場景如何整合F5設備的問題。
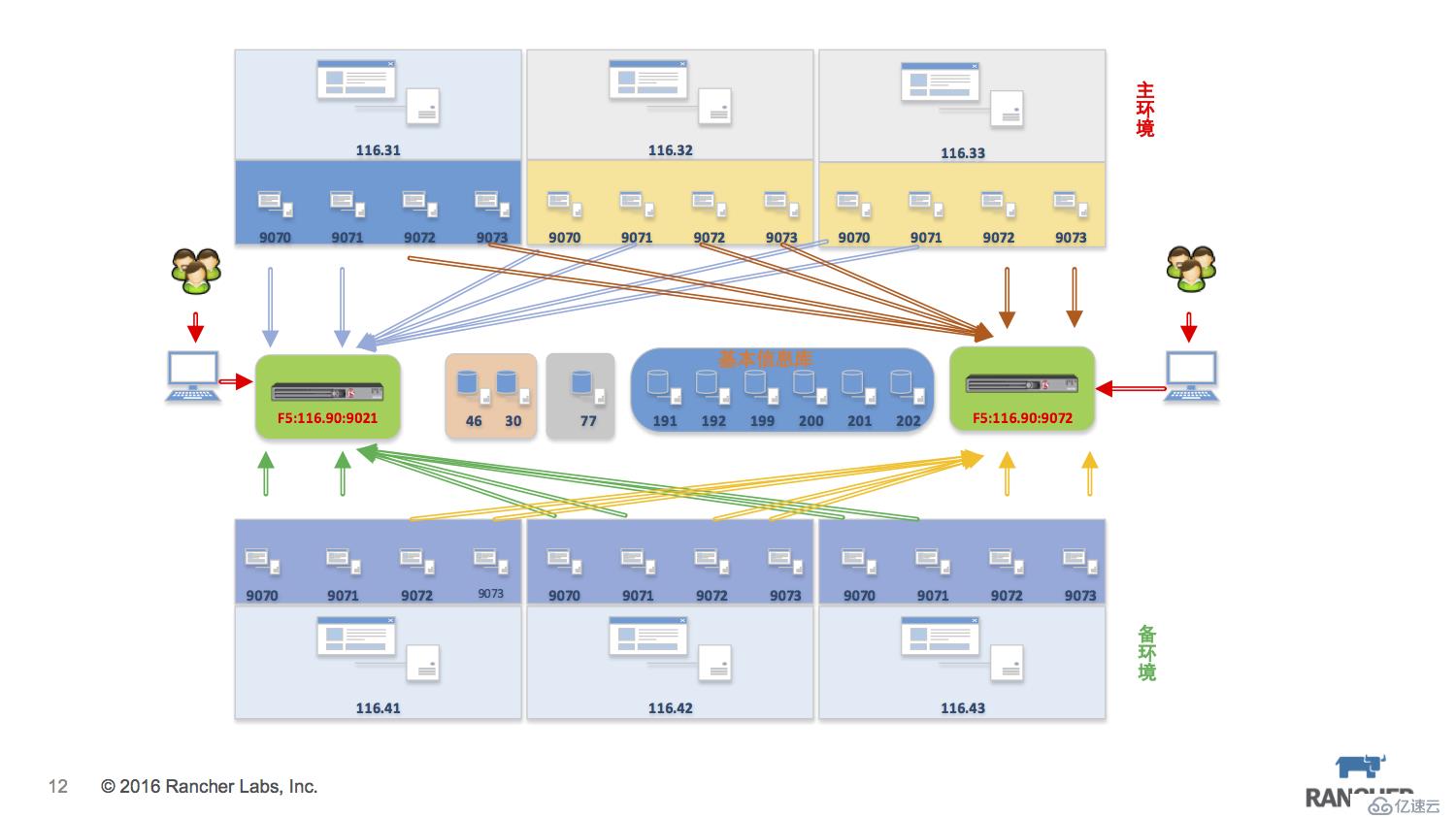
我們以一個應用場景為例,生產環境系統中有4個微服務暴露端口分別是9070、9071、9072、9073,出于容災恢復的考慮需要部署兩套環境主環境和備環境,每個環境三臺主機,所有的數據庫層均放在非容器環境中,所有服務最終通過F5來暴露訪問。
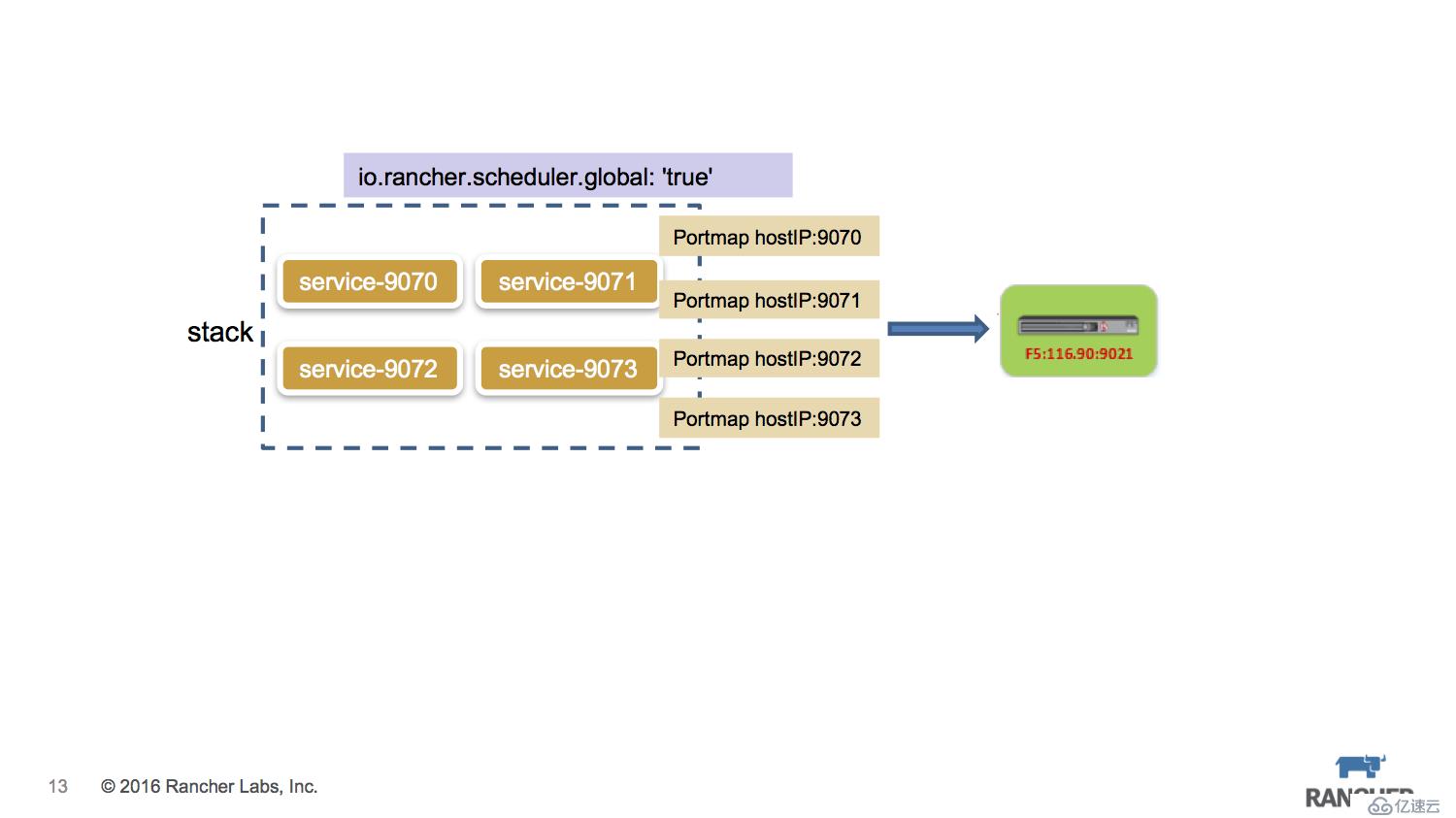
基于Rancher來實現這種應用場景:創建兩個environment分屬主環境和備環境,由于是不同的ENV,所以這兩個環境是從計算存儲網絡層面都是隔離的。每個環境中創建一個stack,stack下創建4個service,service加上global=true的label,保證每臺host上都運行該service,同時通過portmap把service的服務端口直接暴露在host上,外部的F5設備則將VIP配置到這些HostIP+Port上。
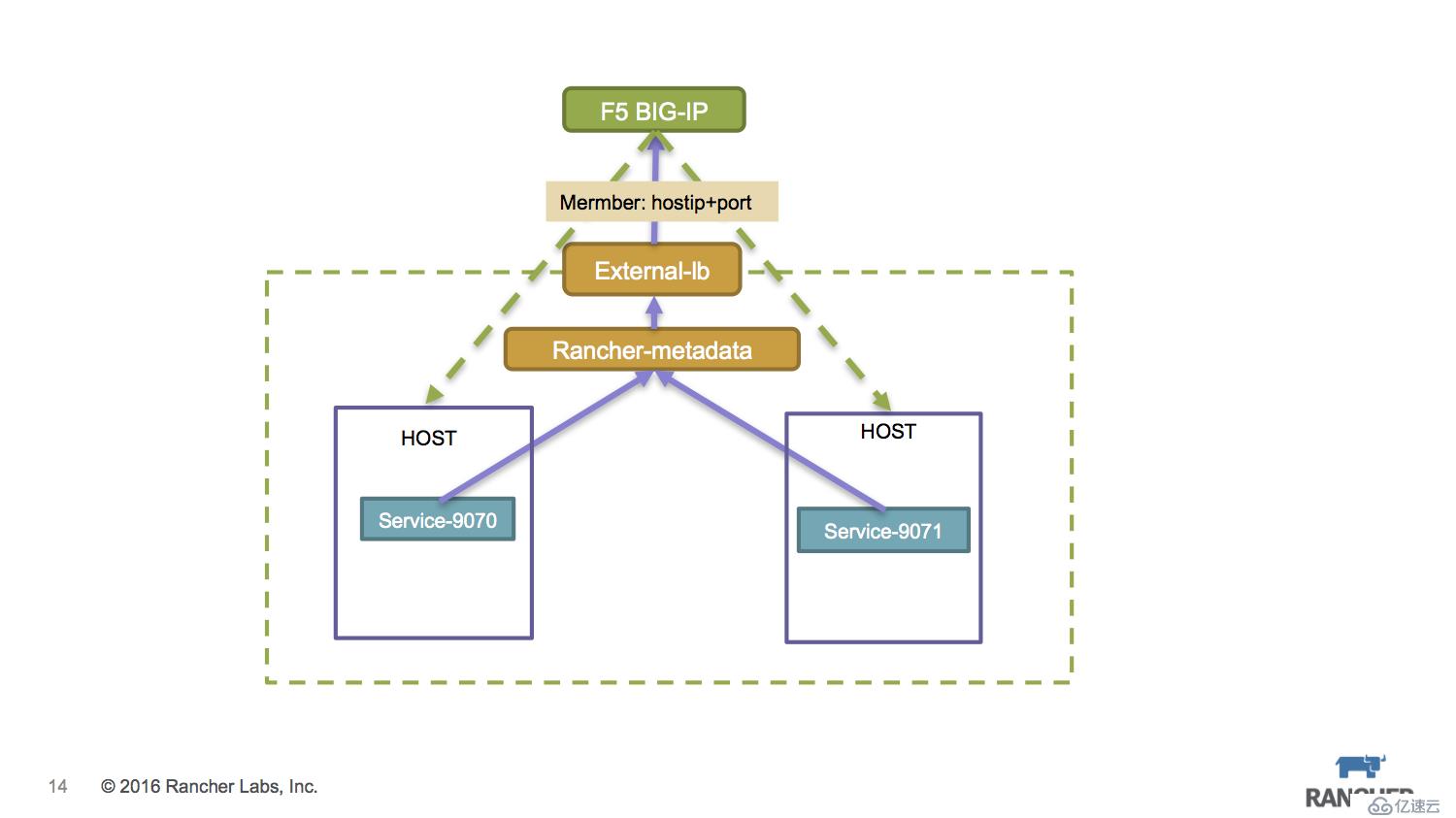
關鍵的F5設置,我們要考慮最好能夠動態設置。Rancher提供了一個external-lb框架 https://github.com/rancher/external-lb來解決此問題,F5的驅動亦位列其中,同樣也是通過rancher-metadata組件來獲取微服務的IP+Port信息。

浮動IP本是Iaas的產物,而Caas仍處在不斷演變的過程中,企業內部的網絡結構仍然需要浮動IP的機制。最主要的場景就是防火墻的規則設置,通常其規則都是針對某個IP,而這個IP就意味著無論后端的服務怎么變換,它要求IP是不能變化的,否則就要不停的修改防火墻規則,這是企業運維人員最無法接受的。
本質上我們需要解決微服務相關的容器發生漂移之后,其對外暴露的IP仍然保持不變。
Rancher的合作伙伴睿云智合提出過一個浮動IP的解決方案,是一個很不錯的思路。
當然我們也可以利用Cattle自有機制來變通地搞定這個問題。
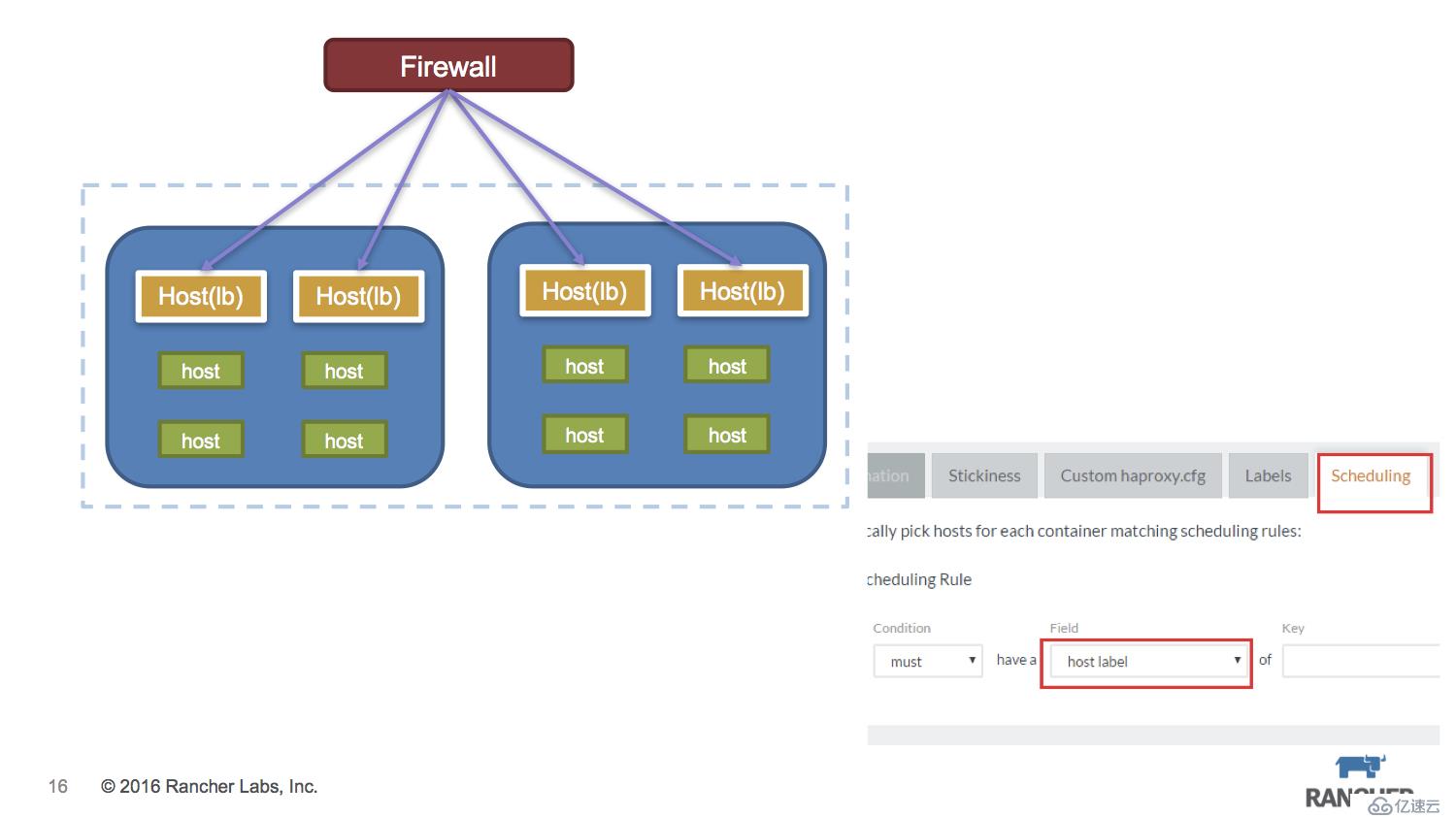
微服務的訪問入口使用內置的rancher-lb方式,可以通過label scheduling方式,讓rancher-lb的容器只落在固定主機上,相關的防火墻只要配置固定的主機IP即可。

最后,我們來一起看一下,比較合適的通用的微服務部署結構。
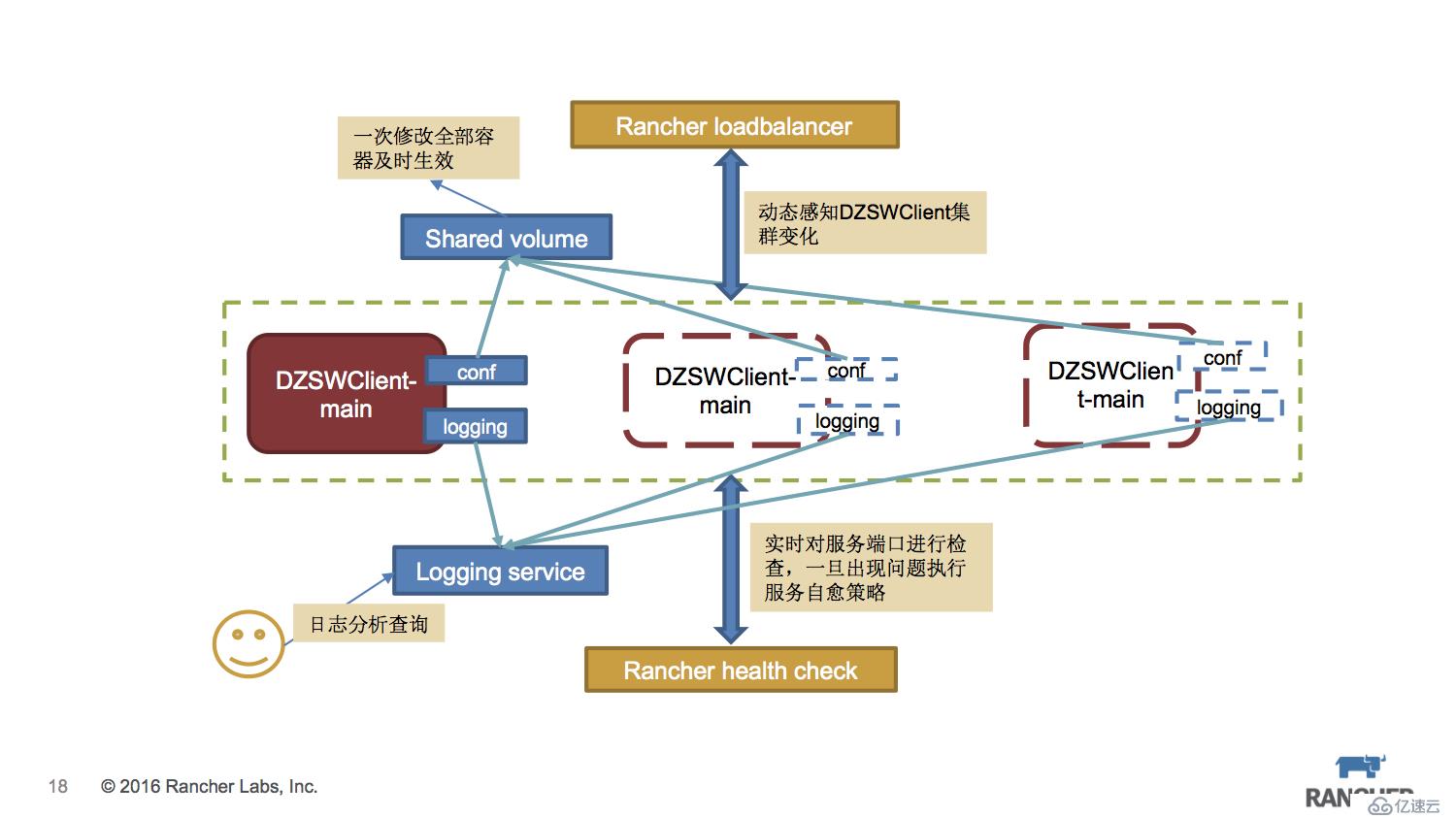
這里面使用sidekick容器來分離主服務的功能,配置文件和日志分別由不同的容器來處理,同時保證整體性,可以完整擴容和克隆。配置文件統一放在 convoy連接的NFS存儲中,保證配置文件的一致性。logging容器會把日志統一發送到ELK日志系統中,便于集中查詢和管理。保證服務的可用性,healthcheck必不可少。外部則使用內置的Rancher LB來暴露訪問。
Q & A
Q:convoy插件的現在有支持ceph或者gluster的catalog么?
A:gluster的catalog 之前有,但是一直有些問題,現在已經被移除了。convoy目前還不支持ceph。
Q:最后一個架構里面,是把日志存到一個volume,然后應用和日志服務,同時掛載的意思么?
A:日志就是通過logging容器發送到ELK中收集起來。
Q:直接用log插件發的么?
A:log driver只能把標準輸入輸出發送出去,而圖中的架構更適合傳統的寫日志文件形式,把日志文件的內容發送到elk中。
Q:具體的操作是不是日志存在一個sidekick 容易中,讓后讓logging容器來解析和發送?
A:是這樣的。
Q:這樣這個volume 需要mount 本地目錄上去么?還是就已一個container的形式存在?
A:一個container足矣。
Q:現在convoy是不是暫時沒有其他方案把一個集群的本地host的磁盤利用起來?
A:Rancher有一個longhorn是你說的場景,還在迭代中。
原文來源:Rancher Labs
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





