溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
vmware虛擬機環境:
192.168.60.128 master 192.168.60.129 node129 192.168.60.130 node130
1、修改每臺虛擬機的/etc/sysconfig/network和/etc/hosts
#修改hostname:vim /etc/sysconfig/network
#修改hosts內容如下:vim /etc/hosts
192.168.60.128 master 192.168.60.129 node129 192.168.60.130 node130
2、配置三臺機器互信(以128機器為例):
2.1 ssh-keygen -t rsa 2.2 ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@192.168.60.129 ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@192.168.60.130 2.3 剩下的每臺機器上都要重復上面的操作
分別在每臺主機上安裝jdk,并配置環境變量。(嫌麻煩的前面可以安裝完jdk后再克隆)
1)下載jdk安裝包(自行百度),并將安裝包拖入到虛擬機當中
2)通過cd命令進入到安裝包的當前目錄,利用如下命令進行解壓縮。
tar -zxvf jdk.....(安裝包名稱)
3)利用如下命令將解壓后的文件夾移到/usr目錄下
#注意,這樣移動到/usr以后就沒有jdk1.8...這個目錄了,是將這個目錄下的所有文件全部移動到/usr/java下,mv jdk1.8...(文件夾名稱) /usr/java
4)配置環境變量
sudo vim /etc/profile
在末尾加上四行:
#java
export JAVA_HOME=/usr/java
export JRE_HOME=/usr/java/jre
export CLASSPATH=$JAVA_HOME/lib
export PATH=:$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
輸入如下命令使配置生效:source /etc/profile
1)解包移動
#解壓hadoop包 tar -zxvf hadoop... #將安裝包移到/home/hadoop目錄下 mv hadoop... /home/hadoop/hadoop
2)新建文件夾
#在/home/hadoop目錄下新建如下目錄 mkdir dfs mkdir dfs/name mkdir dfs/data mkdir tmp
修改JAVA_HOME值(export JAVA_HOME=/usr/java)
4)配置文件:yarn-env.sh
修改JAVA_HOME值(export JAVA_HOME=/usr/java)
5)配置文件:slaves
將內容修改為:
node129 node130
6)配置文件:core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
7)配置文件:hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
8)配置文件:mapred-site.xml
先創建然后編輯
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
9)配置文件:yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
10)將hadoop傳輸到node129和node130 /home/hadoop目錄
scp -r /home/hadoop/hadoop hadoop@node129:/home/hadoop scp -r /home/hadoop/hadoop hadoop@node130:/home/hadoop
5、配置環境變量,并啟動hadoop,檢查是否安裝成功
1)配置環境變量
#編輯/etc/profile sudo vim /etc/profile #以上已經添加過java的環境變量,在后邊添加就可以 export HADOOP_HOME=/home/hadoop/hadoop export PATH=$PATH:$HADOOP_HOME/sbin export PATH=$PATH:$HADOOP_HOME/bin
執行
source /etc/profile
使文件生效。
2)啟動hadoop,進入hadoop安裝目錄
bin/hdfs namenode -format sbin/start-all.sh
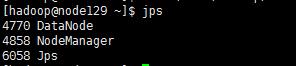
3)啟動后分別在master, node下輸入jps查看進程
看到下面的結果,則表示成功。
Master:

node:
6.向hadoop集群系統提交第一個mapreduce任務(wordcount)
1、 hdfs dfs -mkdir -p /data/input在虛擬分布式文件系統上創建一個測試目錄/data/input
2、 hdfs dfs -put README.txt /data/input 將當前目錄下的README.txt 文件復制到虛擬分布式文件系統中
3、 hdfs dfs-ls /data/input 查看文件系統中是否存在我們所復制的文件
4、 運行如下命令向hadoop提交單詞統計任務
進入jar文件目錄,執行下面的指令。
hadoop jar /home/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /data/input /data/output/result
查看result,結果在result下面的part-r-00000中
hdfs dfs -cat /data/output/result/part-r-00000
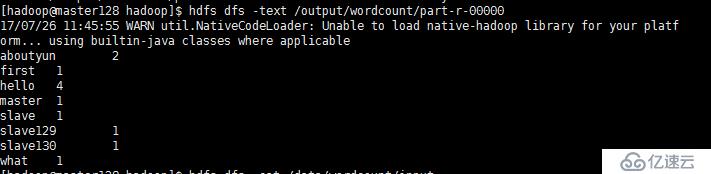
自此,hadoop集群搭建成功!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





