溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Speech 服務是認知服務的一種,提供了語音轉文本,文本轉語音, 語音翻譯等,今天我們實戰的是語音轉文本(Speech To Text)。
STT支持兩種訪問方式,1.是SDK,2.是REST API。
其中:
SDK方式支持?識別麥克風的語音流 和 語音文件;
REST API方式僅支持語音文件;
準備工作:創建 認知服務之Speech服務:
cdn.nlark.com/yuque/0/2020/png/741540/1580645460436-abeba30d-7098-41ba-a3bf-e932146333c1.png">
創建完成后,兩個重要的參數可以在頁面查看:
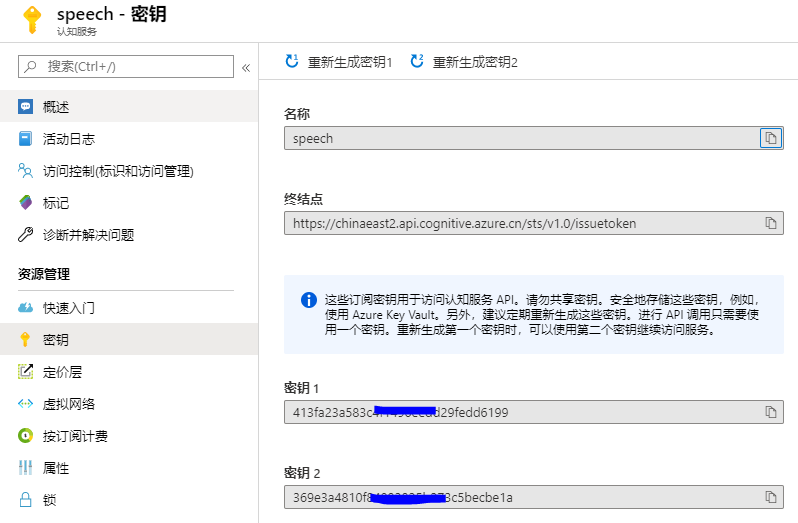
一. REST API方式將語音文件轉換成文本:
Azure global的 Speech API 終結點請參考:
https://docs.microsoft.com/zh-cn/azure/cognitive-services/speech-service/rest-speech-to-text#regions-and-endpoints
Azure 中國區?的 Speech API 終結點:
截至到2020.2月,僅中國東部2區域已開通Speech服務,服務終結點為:
https://chinaeast2.stt.speech.azure.cn/speech/recognition/conversation/cognitiveservices/v1
對于Speech To Text來說,有兩種身份驗證方式:
其中Authorization? Token有效期為10分鐘。
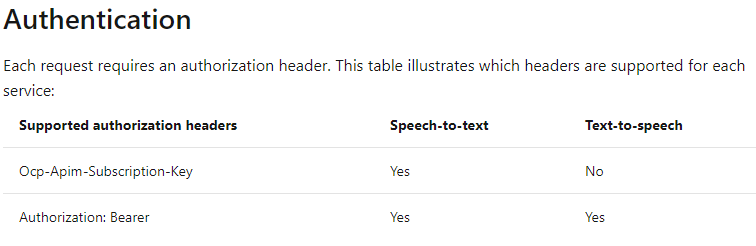
為了簡便,本文使用了Ocp-Apim-Subscription-Key的方式。
注意:如果要實現文本轉語音,按照上表,則必須使用 Authorization Token形式進行身份驗證。
構建請求的其他注意事項:
文件格式: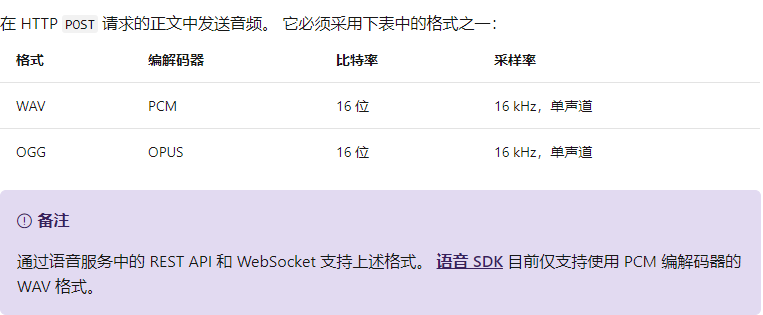
請求頭: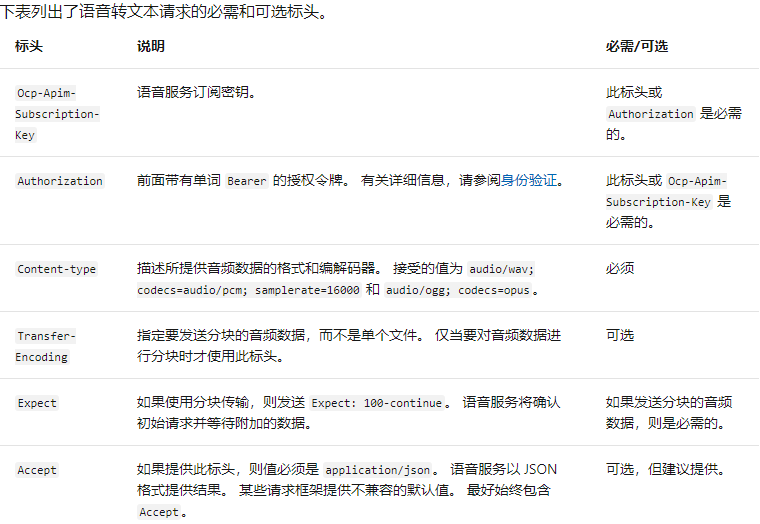
需要注意的是,Key或者Authorization是二選一的關系。
請求參數: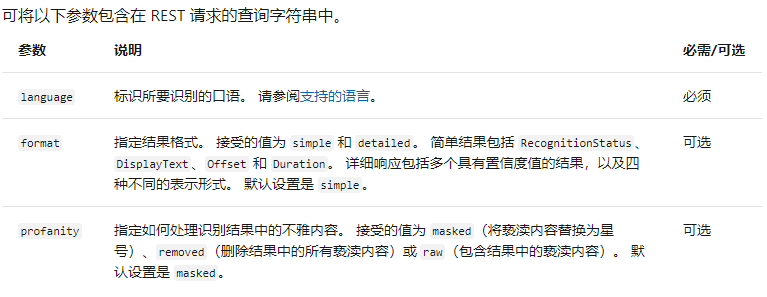
在Postman中的示例如下:
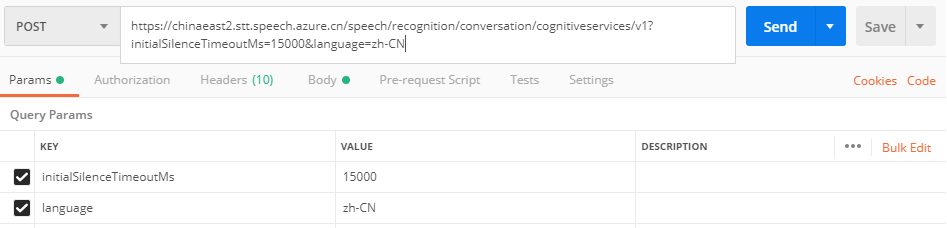
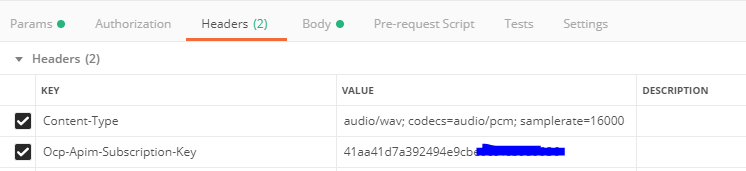
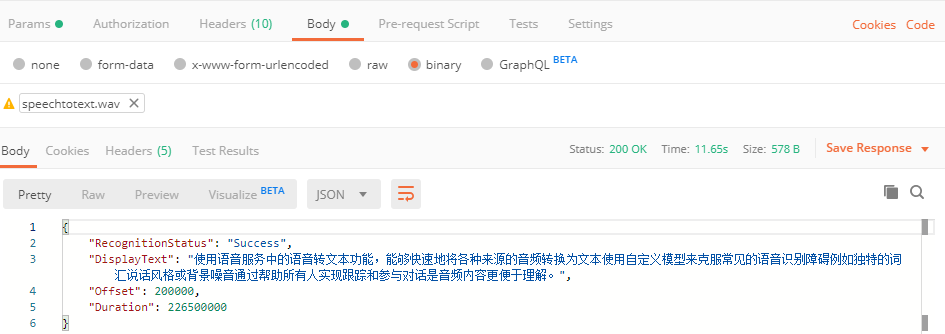
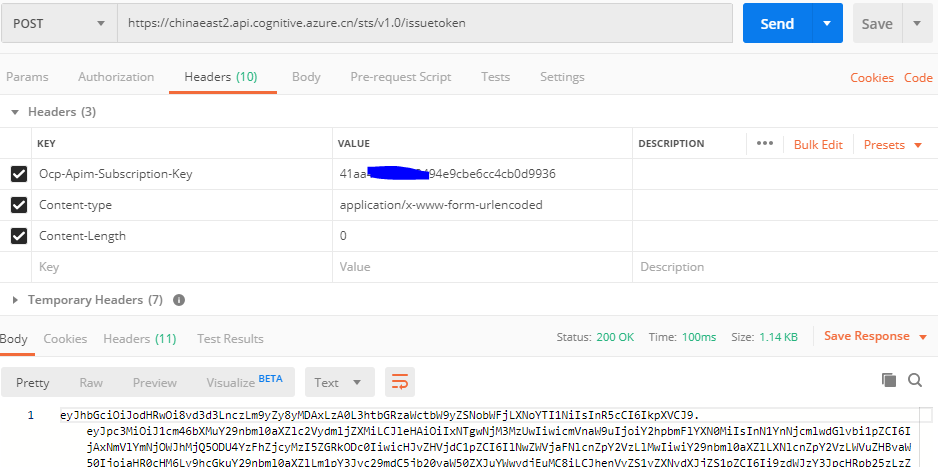
如果要在REST API中使用 Authorization Token,則需要先獲得Token:
Global 獲取Token的終結點:
https://docs.microsoft.com/zh-cn/azure/cognitive-services/speech-service/rest-speech-to-text#authentication
中國區獲取Token的終結點:
截至2020.02,只有中國東部2有Speech服務,其Token終結點為:
https://chinaeast2.api.cognitive.azure.cn/sts/v1.0/issuetoken
Postman獲取Token 參考如下:
二. SDK方式將語音文件轉換成文本(Python示例):
在官網可以看到類似的代碼,但需要注意的是,該代碼僅在Azure Global的Speech服務中正常工作,針對中國區,需要做特定的修改(見下文)。
import azure.cognitiveservices.speech as speechsdk # Creates an instance of a speech config with specified subscription key and service region. # Replace with your own subscription key and service region (e.g., "chinaeast2"). speech_key, service_region = "YourSubscriptionKey", "YourServiceRegion" speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region) # Creates an audio configuration that points to an audio file. # Replace with your own audio filename. audio_filename = "whatstheweatherlike.wav" audio_input = speechsdk.AudioConfig(filename=audio_filename) # Creates a recognizer with the given settings speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_input) print("Recognizing first result...") # Starts speech recognition, and returns after a single utterance is recognized. The end of a # single utterance is determined by listening for silence at the end or until a maximum of 15 # seconds of audio is processed. ?The task returns the recognition text as result. # Note: Since recognize_once() returns only a single utterance, it is suitable only for single # shot recognition like command or query. # For long-running multi-utterance recognition, use start_continuous_recognition() instead. result = speech_recognizer.recognize_once() # Checks result. if result.reason == speechsdk.ResultReason.RecognizedSpeech: ? ?print("Recognized: {}".format(result.text)) elif result.reason == speechsdk.ResultReason.NoMatch: ? ?print("No speech could be recognized: {}".format(result.no_match_details)) elif result.reason == speechsdk.ResultReason.Canceled: ? ?cancellation_details = result.cancellation_details ? ?print("Speech Recognition canceled: {}".format(cancellation_details.reason)) ? ?if cancellation_details.reason == speechsdk.CancellationReason.Error: ? ? ? ?print("Error details: {}".format(cancellation_details.error_details))
代碼提供頁面:
https://docs.azure.cn/zh-cn/cognitive-services/speech-service/quickstarts/speech-to-text-from-file?tabs=linux&pivots=programming-language-python#create-a-python-application-that-uses-the-speech-sdk
針對中國區,需要使用自定義終結點的方式,才能正常使用SDK:
speech_key,?service_region?=?"Your?Key",?"chinaeast2"
template?=?"wss://{}.stt.speech.azure.cn/speech/recognition"?\
???????????????"/conversation/cognitiveservices/v1?initialSilenceTimeoutMs={:d}&language=zh-CN"
speech_config?=?speechsdk.SpeechConfig(subscription=speech_key,
endpoint=template.format(service_region,?int(initial_silence_timeout_ms)))中國區完整代碼為:
#!/usr/bin/env?python
#?coding:?utf-8
#?Copyright?(c)?Microsoft.?All?rights?reserved.
#?Licensed?under?the?MIT?license.?See?LICENSE.md?file?in?the?project?root?for?full?license?information.
"""
Speech?recognition?samples?for?the?Microsoft?Cognitive?Services?Speech?SDK
"""
import?time
import?wave
try:
????import?azure.cognitiveservices.speech?as?speechsdk
except?ImportError:
????print("""
????Importing?the?Speech?SDK?for?Python?failed.
????Refer?to
????https://docs.microsoft.com/azure/cognitive-services/speech-service/quickstart-python?for
????installation?instructions.
????""")
????import?sys
????sys.exit(1)
#?Set?up?the?subscription?info?for?the?Speech?Service:
#?Replace?with?your?own?subscription?key?and?service?region?(e.g.,?"westus").
speech_key,?service_region?=?"your?key",?"chinaeast2"
#?Specify?the?path?to?an?audio?file?containing?speech?(mono?WAV?/?PCM?with?a?sampling?rate?of?16
#?kHz).
filename?=?"D:\FFOutput\speechtotext.wav"
def?speech_recognize_once_from_file_with_custom_endpoint_parameters():
????"""performs?one-shot?speech?recognition?with?input?from?an?audio?file,?specifying?an
????endpoint?with?custom?parameters"""
????initial_silence_timeout_ms?=?15?*?1e3
????template?=?"wss://{}.stt.speech.azure.cn/speech/recognition/conversation/cognitiveservices/v1?initialSilenceTimeoutMs={:d}&language=zh-CN"
????speech_config?=?speechsdk.SpeechConfig(subscription=speech_key,
????????????endpoint=template.format(service_region,?int(initial_silence_timeout_ms)))
????print("Using?endpoint",?speech_config.get_property(speechsdk.PropertyId.SpeechServiceConnection_Endpoint))
????audio_config?=?speechsdk.audio.AudioConfig(filename=filename)
????#?Creates?a?speech?recognizer?using?a?file?as?audio?input.
????#?The?default?language?is?"en-us".
????speech_recognizer?=?speechsdk.SpeechRecognizer(speech_config=speech_config,?audio_config=audio_config)
????
????result?=?speech_recognizer.recognize_once()
????#?Check?the?result
????if?result.reason?==?speechsdk.ResultReason.RecognizedSpeech:
????????print("Recognized:?{}".format(result.text))
????elif?result.reason?==?speechsdk.ResultReason.NoMatch:
????????print("No?speech?could?be?recognized:?{}".format(result.no_match_details))
????elif?result.reason?==?speechsdk.ResultReason.Canceled:
????????cancellation_details?=?result.cancellation_details
????????print("Speech?Recognition?canceled:?{}".format(cancellation_details.reason))
????????if?cancellation_details.reason?==?speechsdk.CancellationReason.Error:
????????????print("Error?details:?{}".format(cancellation_details.error_details))
speech_recognize_once_from_file_with_custom_endpoint_parameters()需要注意的是,如果我們使用SDK識別麥克風中的語音,則將
speech_recognizer?=?speechsdk.SpeechRecognizer(speech_config=speech_config,?audio_config=audio_config)
修改為如下即可(去掉audio_config參數):
speech_recognizer?=?speechsdk.SpeechRecognizer(speech_config=speech_config)
公眾號鏈接:https://mp.weixin.qq.com/s/NA9kQsVDfzTXEqHMTdDExA
語雀地址:https://www.yuque.com/seanyu/azure/blwb5i
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





