溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
1,日志的采集
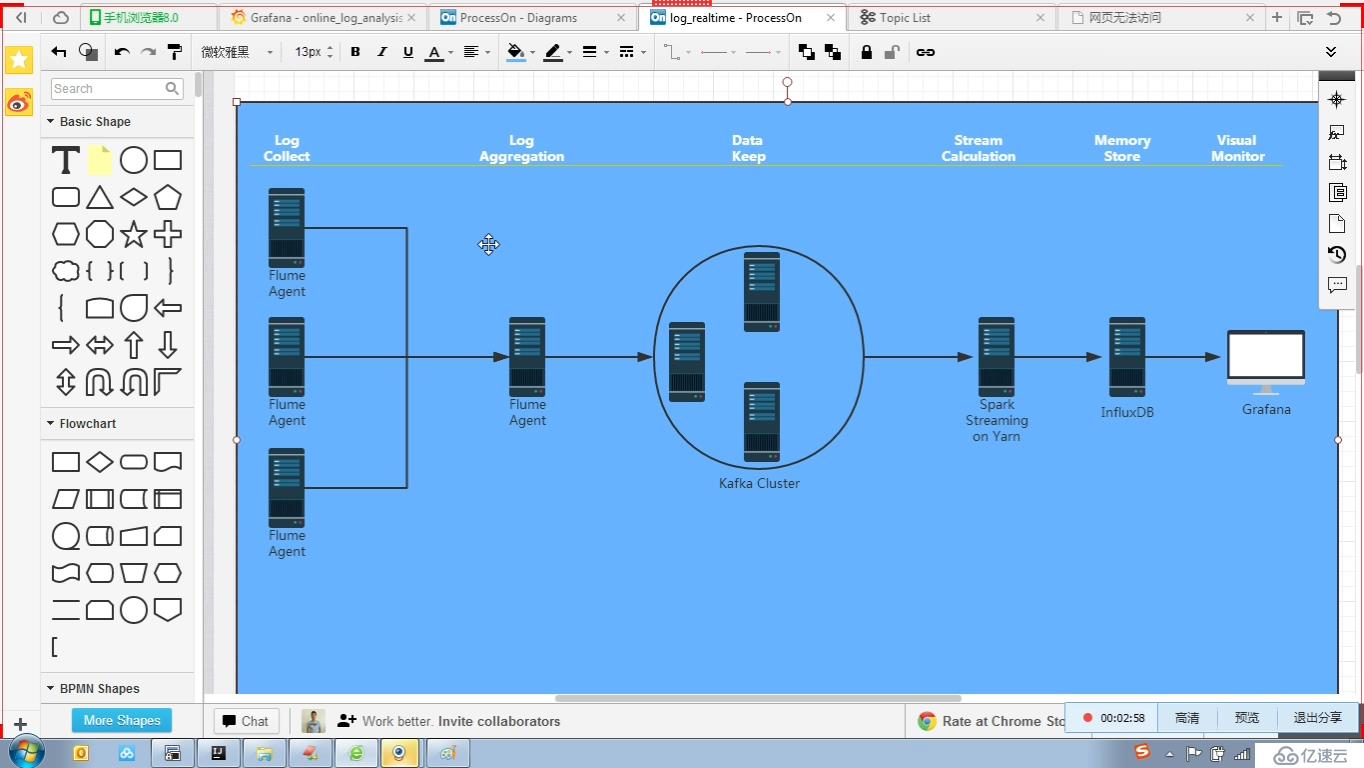
從flume agent 上的數據一般分到兩條線上一條是kafka 集群 ,后期可以用流式處理(spark streaming 或storm 等等)一條是到hdfs,后期可以用hive處理,
業界叫lambda架構 architecture (一般公司的推薦系統,就是用這種架構)
flume-ng agent 采集收集日志后,聚合在一個節點上(也可以不聚合)
為什么要聚合?為什么不直接寫到kafka集群?
假如公司規模比較大,有無數個flume節點,這么多都連kafka,會增加復雜度,有個聚合節點(會是多個節點組成,防止單節點掛了),還可以對日志格式統一處理,篩選不要的數據
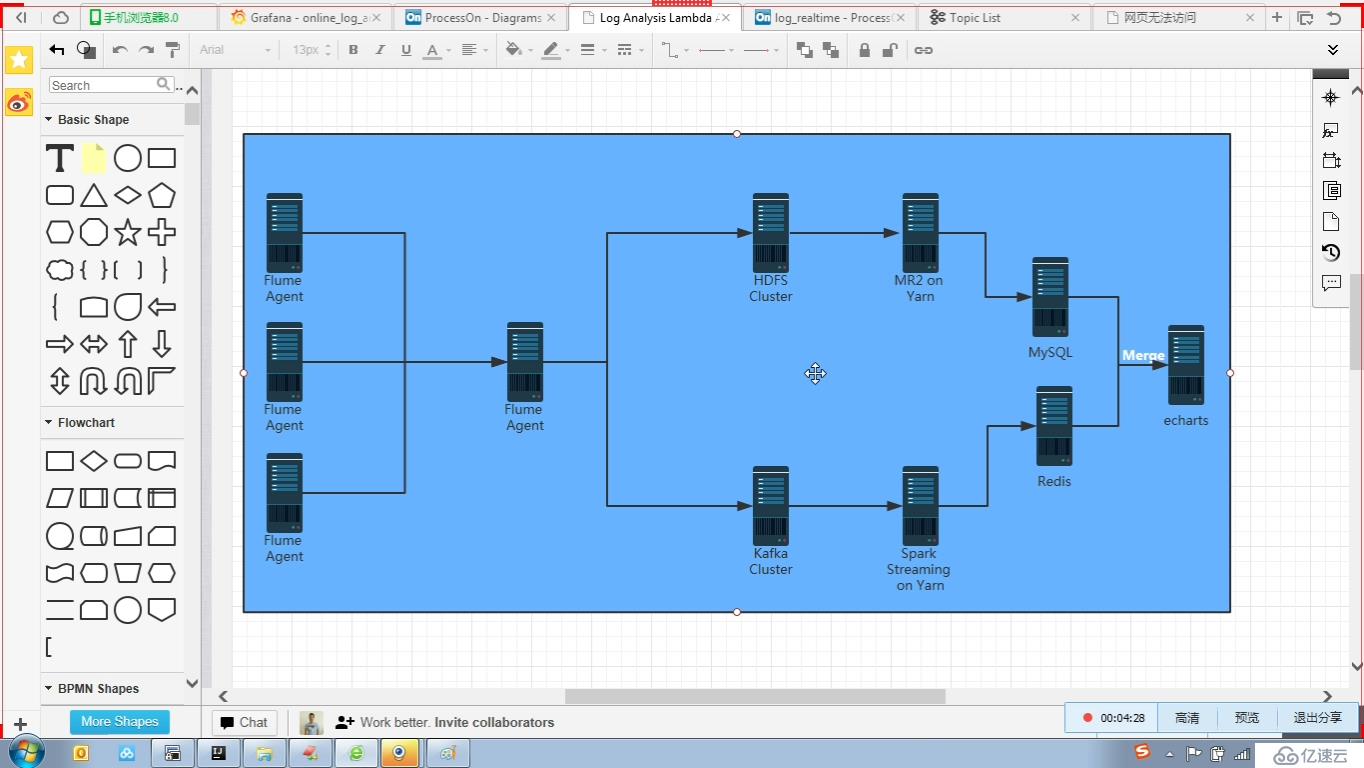
hdfs 可以永久保存數據,mr 可以處理多久數據都行
kafka 集群數據可以存儲一定時間不能長期存儲,sparkstreaming 只能處理一定時間訪問內數據
storm 流
數據源 nginx 日志,mysql 日志,tomcat 日志等等->
flume ->
kafka 消息件 消息發送到這里緩存數據一段時間 ->
spark streaming+spark sql on yarn cluster (實時計算) -> 存儲
1.->redis adminLTE + flask 前端組件 + echarts3 集成到監控的系統上
2.->influxdb 時序分布式數據庫 grafana 可視化組件(這兩種結合比較好)
(elk kibana )
存儲+可視化分析
畫圖工具
http://www.processon.com/
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





