溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
最近在學習Spark的機器學習,由于在機器學習方面Python語言表現不俗,故我選擇使用Python語言作為Spark機器學習的開發語言,也為后續的深度學習打下基礎,故下面是在windows8.1下搭建eclipse4.4.2+Python2.7.14+Spark2.1.0的開發環境,具體過程如下:
到下面這個地址下載對應操作系統的Python安裝文件
https://www.python.org/downloads/release/python-2714/
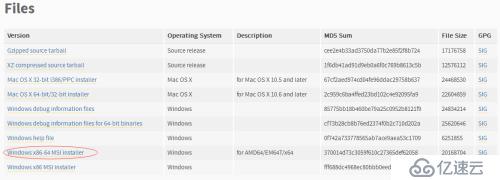
我是windows8.1 64位,故下載Windows x86-64 MSI installer版本的安裝文件。
1)、雙擊 ;
;
2)、在彈出的界面選擇安裝到當前用戶即可,然后點擊Next下一步;
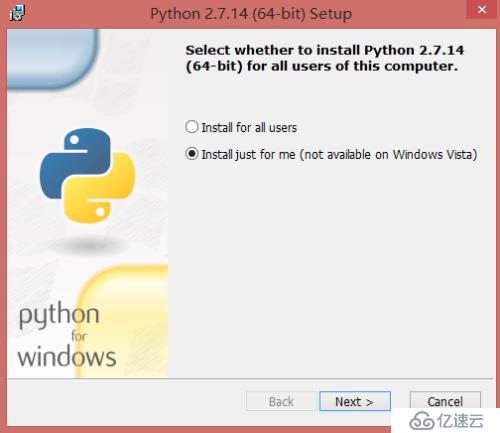
3)、選擇安裝的路徑,我這里選擇安裝到D:\Python27\,然后點擊Next下一步;
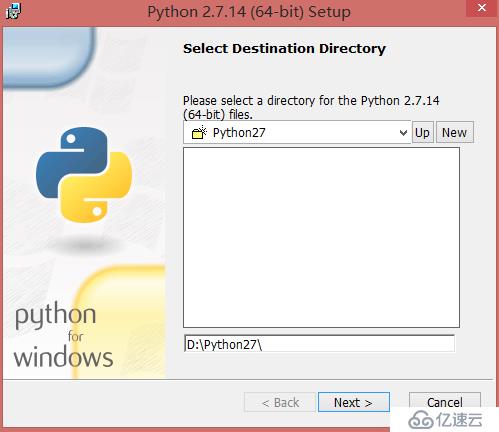
4)、這一步直接點擊Next下一步,然后等待安裝完成;
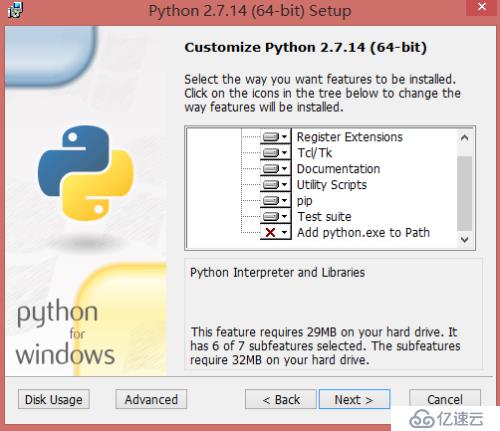
5)、出現如下界面,表示安裝完成,直接點擊Finsh完成。
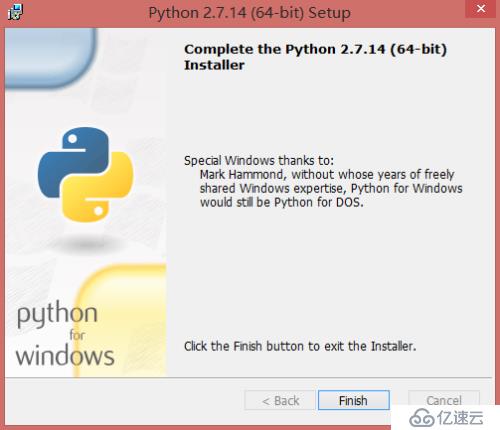
在環境變量中添加Python目錄:
在命令提示框中(cmd) : 輸入
path=%path%;D:\Python27
按下"Enter"。
注意: D:\Python27 是Python的安裝目錄。
也可以通過以下方式設置:
· 右鍵點擊"計算機",然后點擊"屬性"
· 然后點擊"高級系統設置"
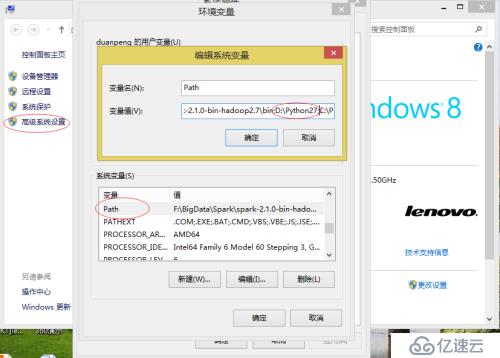
· 選擇"系統變量"窗口下面的"Path",雙擊即可!
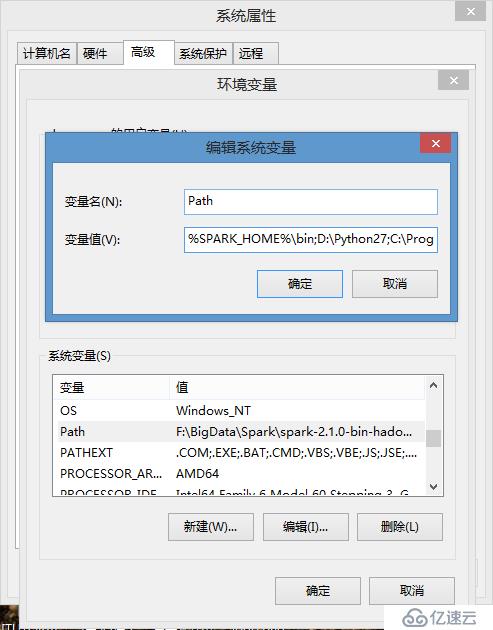
· 然后在"Path"行,添加python安裝路徑即可(我的D:\Python27),所以在后面,添加該路徑即可。 ps:記住,路徑直接用分號";"隔開!
如下圖:
· 最后設置成功以后重啟電腦,重啟電腦完成之后在cmd命令行,輸入命令"python",就可以看到如下圖的相關信息顯示,表示python安裝成功。

下面幾個重要的環境變量,它應用于Python:
變量名 | 描述 |
PYTHONPATH | PYTHONPATH是Python搜索路徑,默認我們import的模塊都會從PYTHONPATH里面尋找。 |
PYTHONSTARTUP | Python啟動后,先尋找PYTHONSTARTUP環境變量,然后執行此文件中變量指定的執行代碼。 |
PYTHONCASEOK | 加入PYTHONCASEOK的環境變量, 就會使python導入模塊的時候不區分大小寫. |
PYTHONHOME | 另一種模塊搜索路徑。它通常內嵌于的PYTHONSTARTUP或PYTHONPATH目錄中,使得兩個模塊庫更容易切換。 |
該步驟簡單,省略,我的Eclipse版本為4.4.2。
注意:安裝Eclipse之前需要安裝JDK。
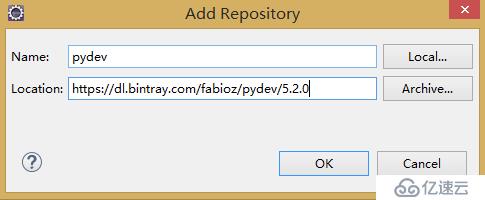
1)、啟動Eclipse, 點擊Help->InstallNew Software... 在彈出的對話框中,點Add按鈕。 Name中填:pydev, Location中填https://dl.bintray.com/fabioz/pydev/5.2.0(因我的Eclipse為4.4.2故安裝對應5.2.0版本的插件,如果是最新的Eclipse,直接使用http://pydev.org/updates),然后一步一步裝下去。 如果裝的過程中,報錯了就重新裝。
2)、下面這步只選擇PyDev節點下的所有,然后點擊Next下一步;
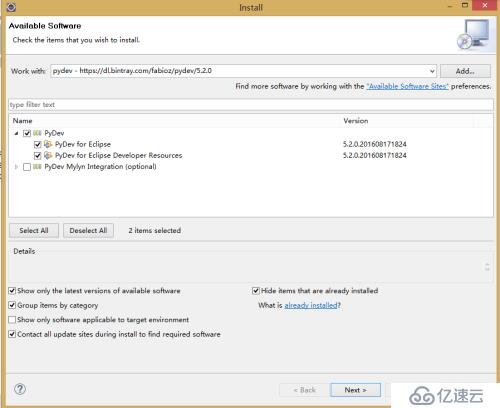
3)、這一步直接點擊Next下一步;
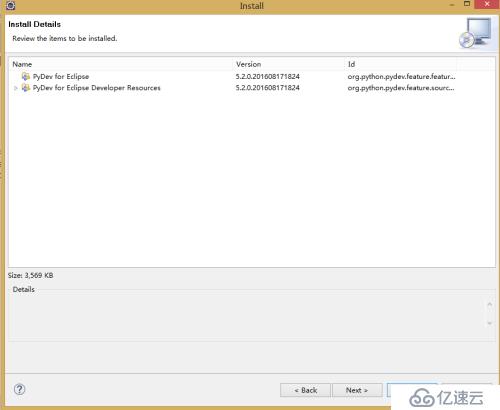
4)、這一步選擇接受Iaccept……,然后點擊Next下一步,然后等待插件安裝完成并重啟Eclipse。

安裝好pydev后, 需要配置Python解釋器。
1)、在Eclipse菜單欄中,點擊Windows->Preferences.
2)、在對話框中,點擊PyDev->Interpreters– Python Interpreter. 點擊New按鈕,選擇python.exe的路徑,然后點擊OK,彈出下一步的窗口;
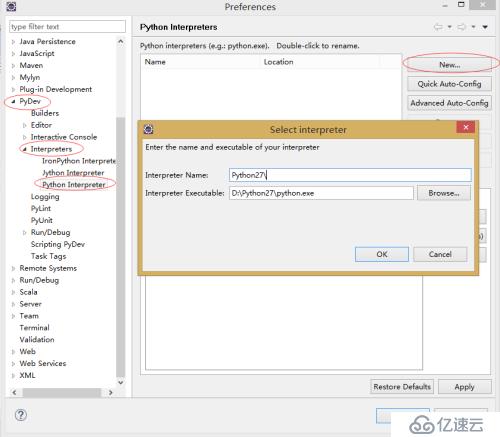
3)、在彈出一個包含很多復選框新的窗口,點OK之后出現下一步的窗口。
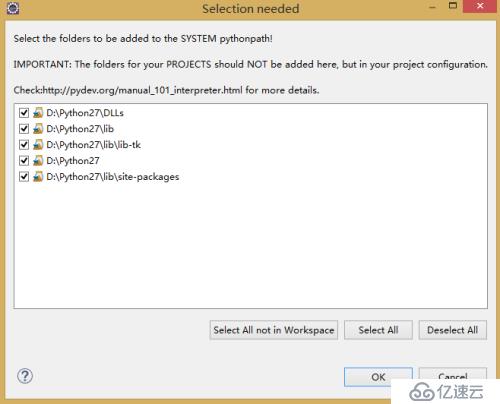
4)、點擊該窗口的OK則完成插件的配置。
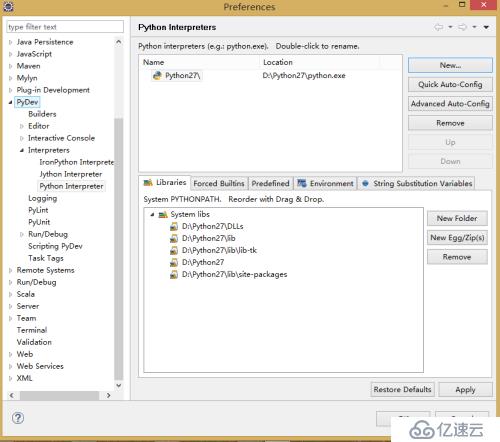
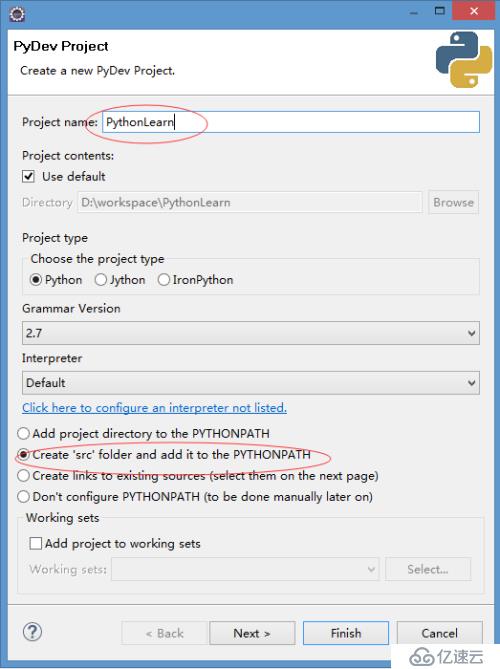
1)、啟動Eclipse,創建一個新的項目,File->New->Projects...選擇PyDev->PyDevProject 輸入項目名稱,如下圖:
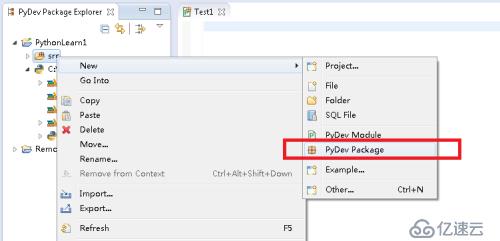
2)、新建 PyDevPackage,輸入包名Test1;
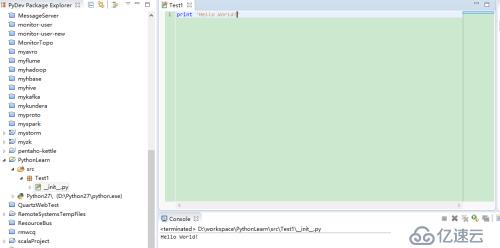
3)、在__init__.py文件中編寫代碼,然后運行,正常在控制臺輸出,表示開發環境搭建完成。
可以從http://spark.apache.org/downloads.html上下載對應的版本,我用的版本是spark-2.1.0-bin-hadoop2.7.tgz,下載完壓縮文件后,解壓。我解壓到F:\BigData\Spark\spark-2.1.0-bin-hadoop2.7;
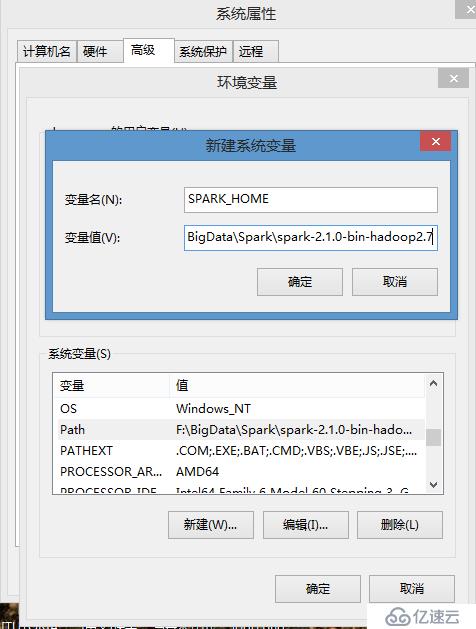
1)、新建SPARK_HOME變量,變量值為:F:\BigData\Spark\spark-2.1.0-bin-hadoop2.7,同時將%SPARK_HOME%\bin添加到系統Path變量,然后重啟電腦;
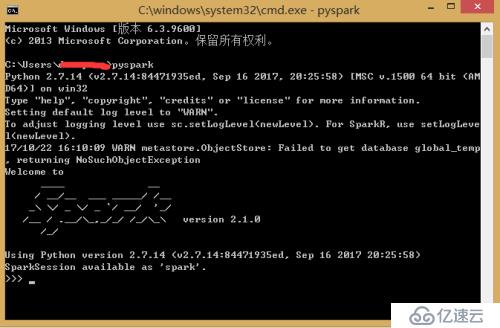
將spark目錄下的pyspark文件夾(F:\BigData\Spark\spark-2.1.0-bin-hadoop2.7\python\pyspark)復制到python安裝目錄D:\Python27\Lib\site-packages里,然后在cmd命令行窗口執行pyspark命令出現如下圖則表示安裝成功:
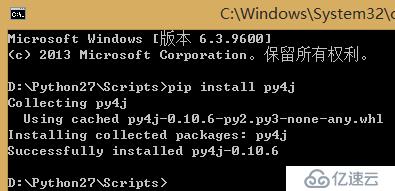
原因:運行python代碼的時候報如題的錯誤信息,表示Python沒有安裝py4j模塊
解決方案:在cmd命令行下運行cd D:\Python27\Scripts(我的python安裝在D:\Python27\盤,這里是切換到pip的安裝目錄下,然后才能執行pip,沒有裝pip的需要預先安裝),然后運行pipinstall py4j安裝相關庫,如下截圖表示安裝成功。
原因:運行python代碼的時候報如題的錯誤信息,表示Python沒有安裝numpy模塊
解決方案:在cmd命令行下運行cd D:\Python27\Scripts(我的python安裝在D:\Python27\盤,這里是切換到pip的安裝目錄下,然后才能執行pip,沒有裝pip的需要預先安裝),然后運行pipinstall numpy安裝相關庫,如下截圖表示安裝成功。

免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





