溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了Java中關于數據庫的面試題有哪些,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
首先解釋一下,什么是聚集索引和非聚集索引。這里我想起網上看到的一個典型的例子:
說索引像一個漢語字典,聚集索引是根據拼音查詢,而非聚集索引是根據偏旁部首查詢,你想想哪個查的快?
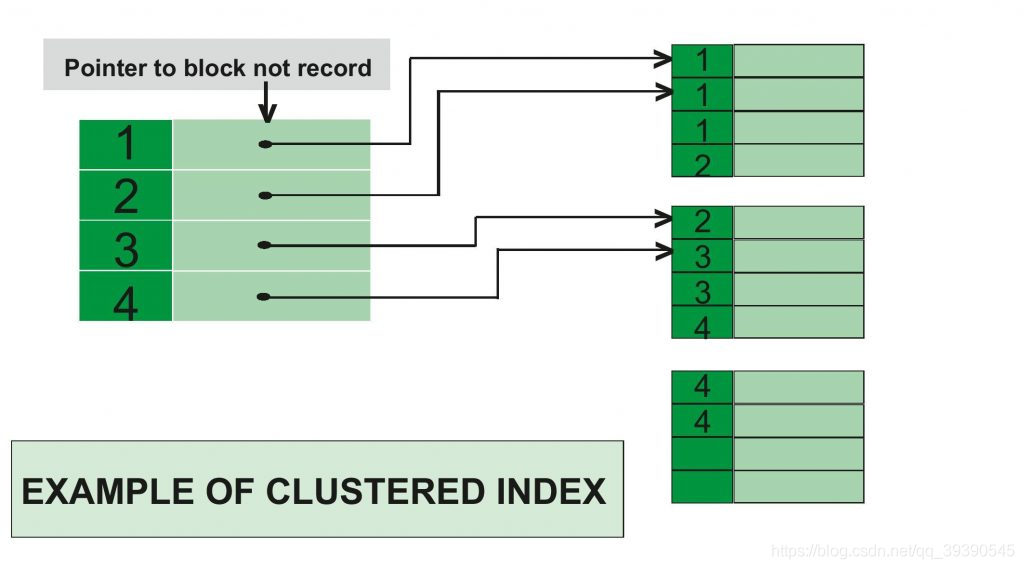
漢語字典的正文本身就是一個聚集索引。比如,我們要查“啊”字,拼音是“a”,按照拼音排序是以“a”開頭“z”結尾的,那么“啊”字就自然地排在字典的前部。如果翻完了所有以“a”開頭的內容仍然找不到這個字,那么就說明字典中就沒有這個字。我們知道,其實字典的正文部分本身就是一個目錄,不需要再去查其他目錄來找到我們需要找的內容。我們把這種正文內容本身就按照一定規則排列(有序)的目錄稱為“聚集索引”。
問題來了,遇到不認識的字,不知道它的發音,怎么辦?
這時候,就得用“偏旁部首”查了吧,然后根據這個偏旁后的頁碼來找字。這種結合“部首目錄”和“檢字表”查到的字的排序并不是真正的正文的排序方法,比如查“張”字,我們可以看到在查部首之后的檢字表中“張”的頁碼是672頁,檢字表中“張”的上面是“馳”字,但頁碼卻是63頁,“張”的下面是“弩”字,頁面是390頁。很顯然,這些字并不是真正的分別位于“張”字的上下方,現在看到的連續的“馳、張、弩”三字實際上就是他們在非聚集索引中的排序,是字典正文中的字在非聚集索引中的映射。
我們可以通過這種方式來找到我們所需要的字,但它需要兩個過程,先找到目錄中的結果,然后再翻到相應頁碼。我們把這種目錄純粹是目錄,正文純粹是正文的排序方式(無序)稱為“非聚集索引”。
聚集索引是我們常用的一種索引,該索引中鍵值的邏輯順序決定了表中相應行的物理順序,我們葉子結點直接對應的實際數據,當索引值唯一(unique)時,使用聚集索引查找特定的行效率很高。例如,使用唯一店員 ID 列 emp_id 查找特定雇員的最快速的方法,是在 emp_id 列上創建聚集索引或 PRIMARY KEY 約束。可見,自增主鍵就是一個標準的聚集索引。
當某列滿足兩個條件時,我們可以創建聚集索引:
數據存儲有序(如自增)
key值應當唯一
聚簇索引像字典,字典按字母順序排列數據,有序。在聚集索引中,索引包含指向數據存儲的塊而不是數據存儲地址的指針,和非聚集索引(Normal)相反。

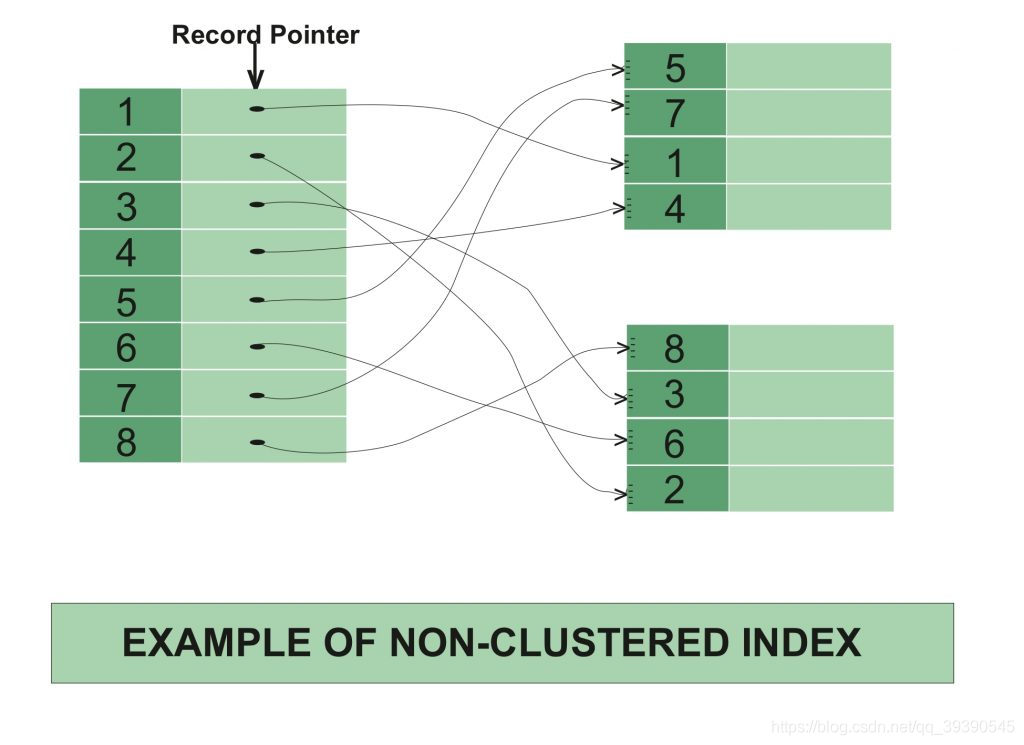
非聚集索引就是索引類型為Normal的普通索引啦,我們在《聊聊MySQL索引“B+Tree”的前世今生》這篇文章中提到,B+Tree(這里是索引類型是Normal)所有關鍵字存儲在葉子節點,但不存儲真正的data,葉子結點存的是一個指向磁盤data的指針,需要到磁盤數據頁中取。
非聚集索引的數據存儲在一個位置,索引存儲在另一位置。由于數據和非聚集索引是分開存儲的,因此在一個表中可以有多個非聚集索引。
聚集索引 和 非聚集索引的區別:
單表中只能有一個聚集索引,而非聚集索引單表可以存在多個。
聚集索引,索引中鍵值的邏輯順序決定了表中相應行的物理順序;非聚集索引,索引中索引的邏輯順序與磁盤上行的物理存儲順序不同。
索引是通過二叉樹的數據結構來描述的,我們可以這么理解聚簇索引:索引的葉節點就是數據節點。而非聚簇索引的葉節點仍然是索引節點,只不過有一個指針指向對應的數據塊。
聚集索引:物理存儲按照索引排序;非聚集索引:物理存儲不按照索引排序;
乍一看,這還真是和聚集索引的約束相背,但實際情況真可以創建聚集索引。
其原因是:如果未使用 UNIQUE 屬性創建聚集索引,數據庫引擎將向表自動添加一個四字節 uniqueifier列。必要時,數據庫引擎 將向行自動添加一個 uniqueifier 值,使每個鍵唯一。此列和列值供內部使用,用戶不能查看或訪問。
如果想查詢學分在60-90之間的學生的學分以及姓名,在學分上創建聚集索引是否是最優的呢?
并不是。既然只輸出兩列,我們可以在學分以及學生姓名上創建聯合非聚集索引,此時的索引就形成了覆蓋索引,即索引所存儲的內容就是最終輸出的數據,這種索引當然比以學分為聚集索引做查詢性能好,算是相當于聯合聚集索引~~靈活運用即可。
B樹是一種多路自平衡搜索樹,它類似普通的二叉樹,但是B書允許每個節點有更多的子節點。B樹示意圖如下:值得注意的是,B樹的非葉子節點和葉子結點的data數據都是分開存儲的,那么針對范圍查詢、排序等常用特性就很不友好了。
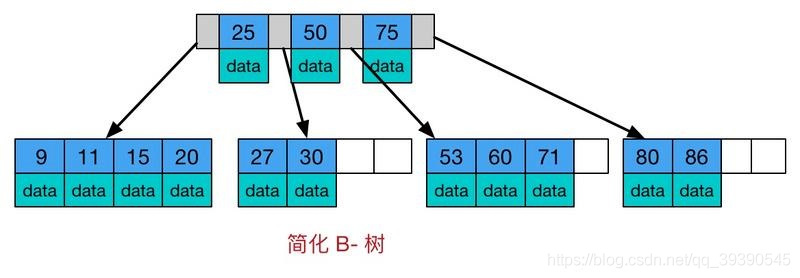
B樹的特點:
所有鍵值分布在整個樹中
任何關鍵字出現且只出現在一個節點中
搜索有可能在非葉子節點結束
在關鍵字全集內做一次查找,性能逼近二分查找算法
為了提升效率,要盡量減少磁盤I/O的次數。實際過程中,磁盤并不是每次嚴格按需讀取,而是每次都會預讀。
磁盤讀取完需要的數據后,會按順序再多讀一部分數據到內存中,這樣做的理論依據是計算機科學中注明的局部性原理:
由于磁盤順序讀取的效率很高(不需要尋址時間,只需很少的旋轉時間),因此對于具有局部性的程序來說,預讀可以提高I/O效率.預讀的長度一般為頁(page)的整倍數。
MySQL(默認使用InnoDB引擎),將記錄按照頁的方式進行管理,每頁大小默認為16K(可以修改)。
B-Tree借助計算機磁盤預讀機制:
每次新建節點的時候,都是申請一個頁的空間,所以每查找一個節點只需要一次I/O;因為實際應用當中,節點深度會很少,所以查找效率很高.
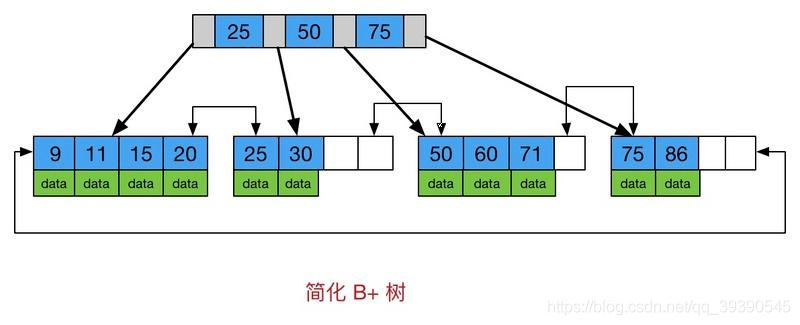
從圖中也可以看到,B+樹與B樹的不同在于:
所有關鍵字存儲在葉子節點,非葉子節點不存儲真正的data,從而可以快速定位到葉子結點。
為所有葉子節點增加了一個鏈指針,意味著所有的值都是按順序存儲的,并且每一個葉子頁到根的距離相同,很適合查找范圍數據。說明支持范圍查詢和天然排序。
因此,B+Tree可以對<,<=,=,>,>=,BETWEEN,IN,以及不以通配符開始的LIKE使用索引。且如果用到了該索引,排序功能的消耗大大減少。
B+樹的優點:
比較的次數均衡,減少了I/O次數,提高了查找速度,查找也更穩定。
B+樹的磁盤讀寫代價更低
B+樹的查詢效率更加穩定
??要知道的是,你每次創建表,系統會為你自動創建一個基于ID的聚集索引(上述B+樹),存儲全部數據;你每次增加索引,數據庫就會為你創建一個附加索引(上述B+樹),索引選取的字段個數就是每個節點存儲數據索引的個數,注意該索引并不存儲全部數據。
通常我們在建立聯合索引的時候,相信建立過索引的同學們會發現,無論是Oracle還是 MySQL 都會讓我們選擇索引的順序,比如我們想在a,b,c三個字段上建立一個聯合索引,我們可以選擇自己想要的優先級,(a、b、c),或是 (b、a、c) 或者是(c、a、b) 等順序。
為什么數據庫會讓我們選擇字段的順序呢?不都是三個字段的聯合索引么?這里就引出了數據庫索引的最重要的原則之一,最左匹配原則。
在我們開發中經常會遇到這種問題,明明這個字段建了聯合索引,但是SQL查詢該字段時卻不會使用這個索引。難道這索引是假的?白嫖老子資源?!

比如索引abc_index:(a,b,c)是a,b,c三個字段的聯合索引,下列sql執行時都無法命中索引abc_index;
select * from table where c = '1'; select * from table where b ='1' and c ='2';
以下三種情況卻會走索引:
select * from table where a = '1'; select * from table where a = '1' and b = '2'; select * from table where a = '1' and b = '2' and c='3';
從上面兩個例子大家有木有看出點眉目呢?
是的,索引abc_index:(a,b,c),只會在where條件中帶有(a)、(a,b)、(a,b,c)的三種類型的查詢中使用。其實這里說的有一點歧義,其實當where條件只有(a,c)時也會走,但是只走a字段索引,不會走c字段。
那么這都是為什么呢?我們一起來看看其原理吧。
MySQL 建立多列索引(聯合索引)有最左匹配的原則,即最左優先:
如果有一個 2 列的索引 (a, b),則已經對 (a)、(a, b) 上建立了索引;
如果有一個 3 列索引 (a, b, c),則已經對 (a)、(a, b)、(a, b, c) 上建立了索引;
假設數據 表 LOL (id,sex,price,name) 的物理位置(表中的無序數據)如下:
(注:下面數據是測試少量數據選用的,只為了方便大家看清楚。實際操作中,應按照使用頻率、數據區分度來綜合設定索引順序~)
主鍵id sex(a) price(b) name(c) (1) 1 1350 AAA安妮 (2) 2 6300 MMM盲僧 (3) 1 3150 NNN奈德麗 (4) 2 6300 CCC錘石 (5) 1 6300 LLL龍女 (6) 2 3150 EEE伊澤瑞爾 (7) 2 6300 III艾克 (8) 1 6300 BBB暴走蘿莉 (9) 1 4800 FFF發條魔靈 (10) 2 3150 KKK卡牌大師 (11) 1 450 HHH寒冰射手 (12) 2 450 GGG蓋倫 (13) 2 3150 OOO小提莫 (14) 2 3150 DDD刀鋒之影 (15) 2 6300 JJJ疾風劍豪 (16) 2 450 JJJ劍圣
當你在LOL表創建一個聯合索引 abc_index:(sex,price,name)時,生成的索引文件邏輯上等同于下表內容(分級排序):
sex(a) price(b) name(c) 主鍵id 1 450 HHH寒冰射手 (11) 1 1350 AAA安妮 (1) 1 3150 NNN奈德麗 (3) 1 4800 FFF發條魔靈 (9) 1 6300 BBB暴走蘿莉 (8) 1 6300 LLL龍女 (5) 2 450 GGG蓋倫 (12) 2 450 JJJ劍圣 (16) 2 3150 DDD刀鋒之影 (14) 2 3150 EEE伊澤瑞爾 (6) 2 3150 KKK卡牌大師 (10) 2 3150 OOO小提莫 (13) 2 6300 CCC錘石 (4) 2 6300 III艾克 (7) 2 6300 JJJ疾風劍豪 (15) 2 6300 MMM盲僧 (2)
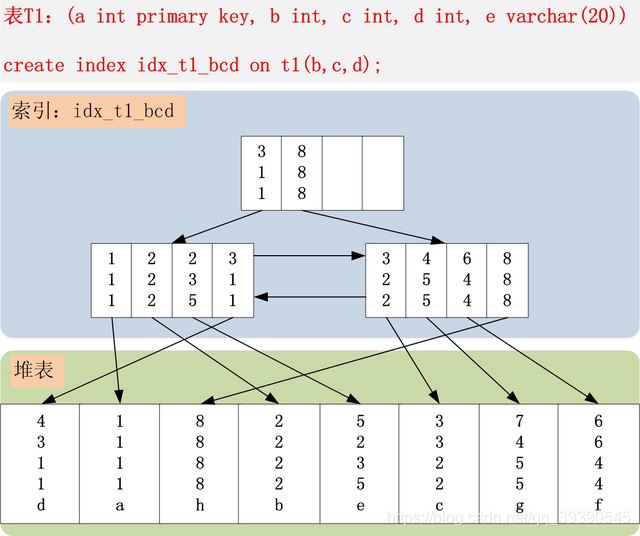
小伙伴兒們有沒有發現B+樹聯合索引的規律?感覺還有點模糊的話,那咱們再來看一張索引存儲數據的結構圖,或許更明了一些。
 ??
??
這是一張來自思否上的圖片,層次感很清晰,小伙伴可以看到,對于B+樹中的聯合索引,每級索引都是排好序的。聯合索引 bcd_index:(b,c,d) , 在索引樹中的樣子如圖 , 在比較的過程中 ,先判斷 b 再判斷 c 然后是 d 。
由上圖可以看出,B+ 樹的數據項是復合的數據結構,同樣,對于我們這張表的聯合索引 (sex,price,name)來說 ,B+ 樹也是按照從左到右的順序來建立搜索樹的,當SQL如下時:
select sex,price,name from LOL where sex = 2 and price = 6300 and name = 'JJJ疾風劍豪';
B+ 樹會優先比較 sex 來確定下一步的指針所搜方向,如果 sex 相同再依次比較 price 和 name,最后得到檢索的數據;
(下面以聯合索引 abc_index:(a,b,c) 來進行講解,便于理解)
當 where b = 6300 and c = 'JJJ疾風劍豪' 這種沒有以 a 為條件來檢索時;B+樹就不知道第一步該查哪個節點,從而需要去全表掃描了(即不走索引)。因為建立搜索樹的時候 a 就是第一個比較因子,必須要先根據 a 來搜索,進而才能往后繼續查詢b 和 c,這點我們通過上面的存儲結構圖可以看明白。
當 where a =1 and c =“JJJ疾風劍豪” 這樣的數據來檢索時;B+ 樹可以用 a 來指定第一步搜索方向,但由于下一個字段 b 的缺失,所以只能把 a = 1 的數據主鍵ID都找到,通過查到的主鍵ID回表查詢相關行,再去匹配 c = ‘JJJ疾風劍豪' 的數據了,當然,這至少把 a = 1 的數據篩選出來了,總比直接全表掃描好多了。
這就是MySQL非常重要的原則,即索引的最左匹配原則。
當對索引中所有列通過"=" 或 “IN” 進行精確匹配時,索引都可以被用到。
理論上索引對順序是敏感的,但是由于 MySQL 的查詢優化器會自動調整 where 子句的條件順序以使用適合的索引,所以 MySQL 不存在 where 子句的順序問題而造成索引失效。當然了,SQL書寫的好習慣要保持,這也能讓其他同事更好地理解你的SQL。
select * from LOL where a = 2 and b > 1000 and c='JJJ疾風劍豪';
對于上面這種類型的sql語句;mysql會一直向右匹配直到遇到范圍查詢(>、<、between、like)就停止匹配(包括like '陳%'這種)。在a、b走完索引后,c已經是無序了,所以c就沒法走索引,優化器會認為還不如全表掃描c字段來的快。所以只使用了(a,b)兩個索引,影響了執行效率。
其實,這種場景可以通過修改索引順序為 abc_index:(a,c,b),就可以使三個索引字段都用到索引,建議小伙伴們不要有問題就想著新增索引哦,浪費資源還增加服務器壓力。
綜上,如果通過調整順序,就可以解決問題或少維護一個索引,那么這個順序往往就是我們DBA人員需要優先考慮采用的。
感謝你能夠認真閱讀完這篇文章,希望小編分享的“Java中關于數據庫的面試題有哪些”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





