溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關JavaScript是怎么影響DOM樹構建的,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
文檔對象模型 (DOM) 會將 web 頁面與到腳本或編程語言連接起來。DOM模型表示具有邏輯樹的文檔。樹的每個分支的終點都是一個節點(node),每個節點都包含著對象(objects)。DOM的方法(methods)允許以編程方式進行訪問樹,從而改變文檔的結構,樣式和內容。節點可以關聯上事件處理器,一旦某一事件被觸發了,那些事件處理器就會被執行。
從網絡傳給渲染引擎的 HTML 文件字節流是無法直接被渲染引擎理解的,所以要將其轉化為渲染引擎能夠理解的內部結構,這個結構就是 DOM。DOM 提供了對 HTML 文檔結構化的表述。在渲染引擎中,DOM 有三個層面的作用
從頁面的視角來看,DOM 是生成頁面的基礎數據結構。
從 JavaScript 腳本視角來看,DOM 提供給 JavaScript 腳本操作的接口,通過這套接口,JavaScript 可以對 DOM 結構進行訪問,從而改變文檔的結構、樣式和內容。
從安全視角來看,DOM 是一道安全防護線,一些不安全的內容在 DOM 解析階段就被拒之門外了。
簡言之,DOM 是表述 HTML 的內部數據結構,它會將 Web 頁面和 JavaScript 腳本連接起來,并過濾一些不安全的內容
DOM 并不是一個編程語言,但如果沒有DOM, JavaScript 語言也不會有任何網頁,XML頁面以及涉及到的元素的概念或模型。在文檔中的每個元素— 包括整個文檔,文檔頭部, 文檔中的表格,表頭,表格中的文本 — 都是文檔所屬于的文檔對象模型(DOM)的一部分,因此它們可以使用DOM和一個腳本語言如 JavaScript,來訪問和處理。
起初,JavaScript和DOM是交織在一起的,但它們最終演變成了兩個獨立的實體。JavaScript可以訪問和操作存儲在DOM中的內容,因此我們可以寫成這個近似的等式:
API (web 或 XML 頁面) = DOM + JS (腳本語言)
DOM 和 JavaScript
在渲染引擎內部,有一個叫HTML 解析器(HTMLParser)的模塊,它的職責就是負責將 HTML 字節流轉換為 DOM 結構。
HTML 解析器并不是等整個文檔加載完成之后再解析的,而是隨著 HTML 文檔邊加載邊解析的,是網絡進程加載了多少數據,HTML 解析器便解析多少數據。
流程:網絡進程接收到響應頭之后,會根據響應頭中的 content-type 字段來判斷文件的類型,比如 content-type 的值是“text/html”,那么瀏覽器就會判斷這是一個 HTML 類型的文件,根據這個判斷選擇相應的解析引擎,然后為該請求選擇或者創建一個渲染進程。渲染進程準備好之后,網絡進程和渲染進程之間會建立一個共享數據的管道,網絡進程接收到數據后就往這個管道里面放,而渲染進程則從管道的另外一端不斷地讀取數據,并同時將讀取的數據傳送給 HTML 解析器。
可以把這個管道想象成一個“水管”,網絡進程接收到的字節流像水一樣倒進這個“水管”,而“水管”的另外一端是渲染進程的 HTML 解析器,它會動態接收字節流,并將其解析為 DOM。
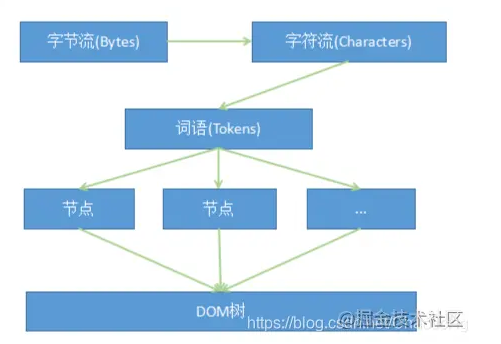
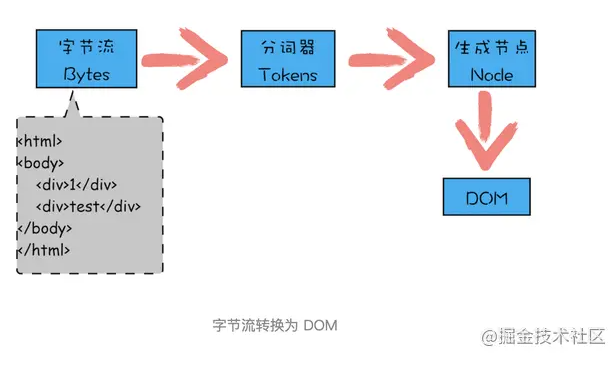
從圖中可以看出,字節流轉換為 DOM 需要三個階段。
第一個階段,通過分詞器將字節流轉換為 Token。
解析 HTML 也是一樣的,需要通過分詞器先將字節流轉換為一個個 Token,分為 Tag Token 和文本 Token。將 HTML 代碼通過詞法分析生成的 Token 如下圖所示:
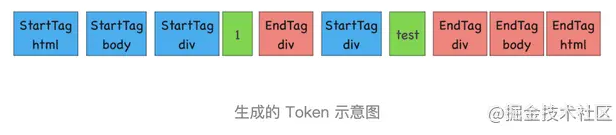
由圖可知,Tag Token 又分 StartTag 和 EndTag。
第二階段是將 Token 解析為 DOM 節點
HTML 解析器維護了一個Token 棧結構,該 Token 棧主要用來計算節點之間的父子關系,在第一個階段中生成的 Token 會被按照順序壓到這個棧中。具體的處理規則如下所示:
如果壓入到棧中的是StartTag Token,HTML 解析器會為該 Token 創建一個 DOM 節點,然后將該節點加入到 DOM 樹中,它的父節點就是棧中相鄰的那個元素生成的節點。
如果分詞器解析出來是文本 Token,那么會生成一個文本節點,然后將該節點加入到 DOM 樹中,文本 Token 是不需要壓入到棧中,它的父節點就是當前棧頂 Token 所對應的 DOM 節點。
如果分詞器解析出來的是EndTag 標簽,比如是 EndTag div,HTML 解析器會查看 Token 棧頂的元素是否是 StarTag div,如果是,就將 StartTag div 從棧中彈出,表示該 div 元素解析完成。
通過分詞器產生的新 Token 就這樣不停地壓棧和出棧,整個解析過程就這樣一直持續下去,直到分詞器將所有字節流分詞完成。
第三階段是將 DOM 節點添加到 DOM 樹中
將創建的 DOM 節點,添加到 document 上,形成 DOM 樹。
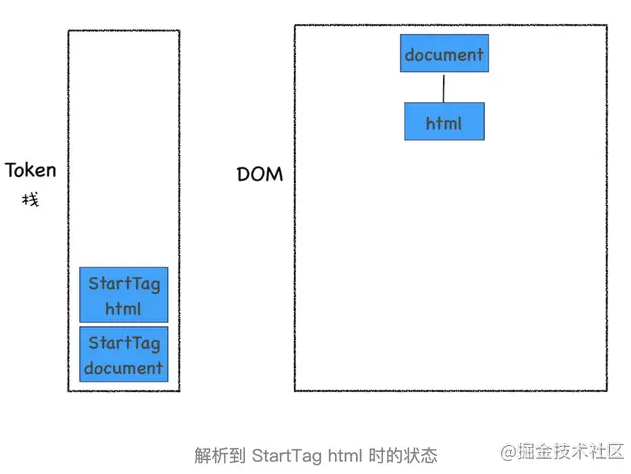
HTML 解析器開始工作時,會默認創建了一個根為 document 的空 DOM 結構,同時會將一個 StartTag document 的 Token 壓入棧底。然后經過分詞器解析出來的第一個 StartTag html Token 會被壓入到棧中,并創建一個 html 的 DOM 節點,添加到 document 上,如下圖所示
然后按照同樣的流程解析出來 StartTag body 和 StartTag div,其 Token 棧和 DOM 的狀態如下圖所示:
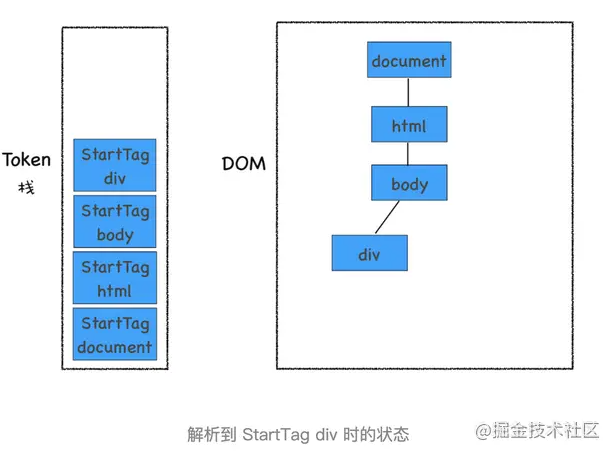
接下來解析出來的是第一個 div 的文本 Token,渲染引擎會為該 Token 創建一個文本節點,并將該 Token 添加到 DOM 中,它的父節點就是當前 Token 棧頂元素對應的節點,如下圖所示:
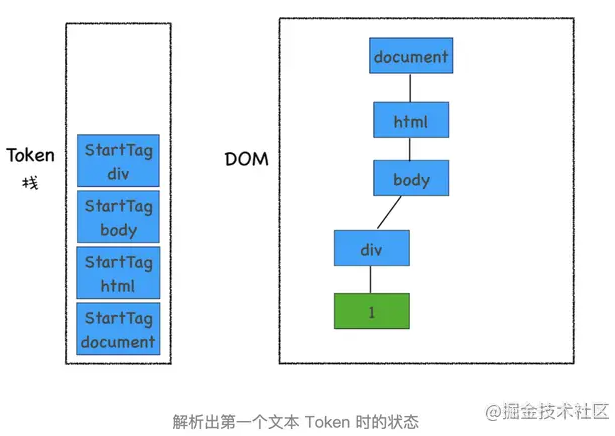
再接下來,分詞器解析出來第一個 EndTag div,這時候 HTML 解析器會去判斷當前棧頂的元素是否是 StartTag div,如果是則從棧頂彈出 StartTag div,如下圖所示

按照同樣的規則,一路解析,最終結果如下圖所示:
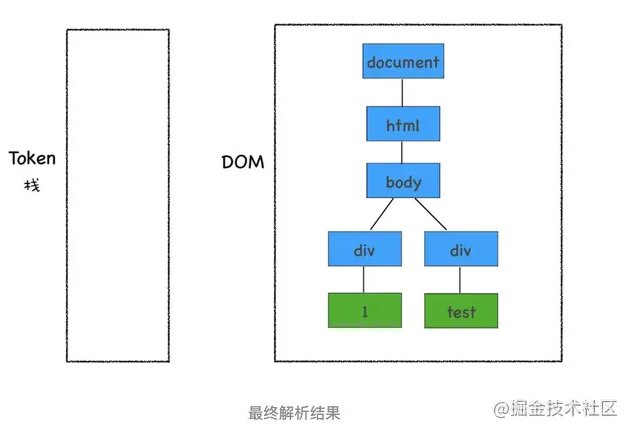
通過上面的介紹,相信你已經清楚 DOM 是怎么生成的了。不過在實際生產環境中,HTML 源文件中既包含 CSS 和 JavaScript,又包含圖片、音頻、視頻等文件,所以處理過程遠比上面這個 Demo 復雜。不過理解了這個簡單的 Demo 生成過程,我們就可以往下分析更加復雜的場景了。
如果頁面中含有一段 JavaScript 腳本,或者引入了腳本文件,則這段腳本的解析過程就與上面的過程有點不一樣了。
script標簽之前,所有的解析流程還是和之前介紹的一樣,但是解析到script標簽時,渲染引擎判斷這是一段腳本,此時 HTML 解析器就會暫停 DOM 的解析,JavaScript 引擎介入,因為 JavaScript 腳本可能要修改當前已經生成的 DOM 結構。
如果腳本是通過 JavaScript 文件加載的,則需要先下載這段 JavaScript 代碼。這里需要重點關注下載環境,因為JavaScript 文件的下載過程會阻塞 DOM 解析,而通常下載又是非常耗時的,會受到網絡環境、JavaScript 文件大小等因素的影響。
如果腳本是直接內嵌的 JavaScript 腳本,則直接執行。
如果 JavaScript 腳本修改了 DOM 中的 div 中的內容,所以執行這段腳本之后,已經解析過的 div 節點內容也會被修改。腳本執行完成之后,HTML 解析器恢復解析過程,繼續解析后續的內容,直至生成最終的 DOM。
還有一種情況則是,如果 JavaScript 代碼出現了,修改頁面 CSS 樣式的語句,用來操縱 CSSOM ,所以在執行 JavaScript 之前,需要先解析 JavaScript 語句之上所有的 CSS 樣式。所以如果代碼里引用了外部的 CSS 文件,那么在執行 JavaScript 之前,還需要等待外部的 CSS 文件下載完成,并解析生成 CSSOM 對象之后,才能執行 JavaScript 腳本。
而 JavaScript 引擎在解析 JavaScript 代碼之前,是不知道 JavaScript 是否操縱了 CSSOM 的,所以渲染引擎在遇到 JavaScript 腳本時,不管該腳本是否操縱了 CSSOM,都會執行 CSS 文件下載,解析操作,再執行 JavaScript 腳本。所以說 JavaScript 腳本是依賴樣式表的。
通過上面的分析,我們知道了 JavaScript 會阻塞 DOM 生成,而樣式文件又會阻塞 JavaScript 的執行,所以在實際的工程中需要重點關注 JavaScript 文件和樣式表文件,使用不當會影響到頁面性能的。
為防止頁面阻塞,Chrome 瀏覽器做了很多優化,其中一個主要的優化是預解析操作。當渲染引擎收到字節流之后,會開啟一個預解析線程,用來分析 HTML 文件中包含的 JavaScript、CSS 等相關文件,解析到相關文件之后,預解析線程會提前下載這些文件。
再回到 DOM 解析上,我們知道引入 JavaScript 線程會阻塞 DOM,不過也有一些相關的策略來規避,比如使用 CDN 來加速 JavaScript 文件的加載,壓縮 JavaScript 文件的體積。另外,如果 JavaScript 文件中沒有操作 DOM 相關代碼,就可以將該 JavaScript 腳本設置為異步加載,通過 async 或 defer 來標記代碼,使用方式如下所示:
<script async type="text/javascript" src='foo.js'></script>
<script defer type="text/javascript" src='foo.js'></script>
async 和 defer 雖然都是異步的,不過還有一些差異,使用 async 標志的腳本文件一旦加載完成,會立即執行;而使用了 defer 標記的腳本文件,需要在 DOMContentLoaded 事件之前執行。
首先我們介紹了 DOM 是如何生成的,然后又基于 DOM 的生成過程分析了 JavaScript 是如何影響到 DOM 生成的。也談到 CSS 和 JavaScript 都會影響到 DOM 的生成。
DOM生成的過程
解析 HTML 需要通過分詞器先將字節流轉換為 Token。
如果壓入到棧中的是StartTag Token,HTML 解析器會為該 Token 創建一個 DOM 節點,然后將該節點加入到 DOM 樹中。如果分詞器解析出來是文本 Token,那么會生成一個文本節點,然后將該節點加入到 DOM 樹中。如果分詞器解析出來的是EndTag 標簽,HTML 解析器會查看 Token 棧頂的元素是否是 StarTag div,如果是,就將 StartTag div 從棧中彈出,表示該 div 元素解析完成。
通過分詞器產生的新 Token 就這樣不停地壓棧和出棧,整個解析過程就這樣一直持續下去,直到分詞器將所有字節流分詞完成。
在解析過程中如果遇到 JavaScript 代碼,則停止 HTML 解析,如果js通過腳本加載的則先下載該腳本再執行,再執行之前 CSS 也會被解析生成 CSSOM。經此過程直至整個 DOM 構建完成。
關于“JavaScript是怎么影響DOM樹構建的”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





