溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Redis中怎么使用緩存替換策略,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
在操作系統的頁面管理中,內存會維護一部分數據以備進程使用,但是由于內存的大小必然是遠遠小于硬盤的,當某些進程訪問到內存中沒有的數據時,必然需要從硬盤中讀進內存,所以迫于內存容量的壓力下迫使操作系統將一些頁換出,或者說踢出,而決定將哪些(個)頁面踢出就是內存替換策略。
我們考慮內存中的頁實際上是整個系統頁的子集,所以內存可以當成系統中虛擬內存的緩存(Cache),所以頁面置換算法就是緩存替換的方法。
一般意義下,選取頁面置換算法即選取一個緩存命中率更高的或者說缺頁率更低的算法,但實際上有時候隨著算法緩存命中率提升,算法復雜度也在上升,所以帶來的系統開銷也是在上升的,所以我們不得不在系統開銷和算法復雜程度中間取一個折中,比如Redis中采取的類LRU緩存置換策略實際上在大多數情況下比起理想LRU緩存命中率是低的,但理想LRU實現起來會給系統帶來更大的開銷,得不償失。
下面介紹最常見的五種置換策略,其中最佳置換算法是理論上很難實現的,其余的FIFO、LRU、LFU,其算法復雜度、開銷是遞增的,但是缺頁率也是越來越低,或者說越來越接近最佳置換策略的。最后一種時鐘置換算法是一種近似的LRU算法,是保證了低系統開銷下同時較低的缺頁率的一種折中選擇。
最佳置換算法,其所選擇的被淘汰的頁面將是以后永不使用的,或是在最長(未來)時間內不再被訪問的頁面。聽名字定義很顯然頁面未來的使用情況它就不可預測,所以最佳置換算法只是理論上的最優方法,實際上在大多數情況下并沒法完成,所以更多的是作為衡量其他置換算法的標準。
許多早期的操作系統為了保證算法的簡單,避免高復雜度的算法,嘗試了最簡單的置換策略,即FIFO置換策略,顧名思義就是維護一個頁的隊列,最先進入內存的頁最先被淘汰,這樣的算法復雜度低,系統開銷也極低,但是顯然命中率會下降。
另外考慮一種情況,增大緩存時,一般意義下緩存的命中率必然會上升,但是FIFO算法則在有的時候則會下降,這種現象叫做Belady現象。原因是FIFO算法沒有考慮到程序的局部性原則,踢出的頁面很可能是程序經常性訪問的頁面。
Belady現象的實例分析可以參考belady
為了解決Belady現象,同時也是基于程序的局部性原則(Locality of reference,指的是在計算機科學計算機科學領域中應用程序在訪問內存的時候,傾向于訪問內存中較為靠近的值。)就有了LRU置換策略,從程序代碼的角度理解局部性原則就是,程序一般傾向于頻繁的訪問某些代碼(比如循環)或者數據結構(比如循環訪問的數組),因此我們應該使用歷史訪問數據來決定,哪些頁應該被踢出,哪些頁不應該被踢出,具體的就是,最近沒有被訪問的頁優先被踢出。這個其實不難理解,通過一個訪問順序的隊列,每次訪問某個頁,就將此頁移到隊首,當內存(緩存)滿了時優先從隊尾踢出相應的頁。(下面給出一個例子,表來自操作系統導論第22章)
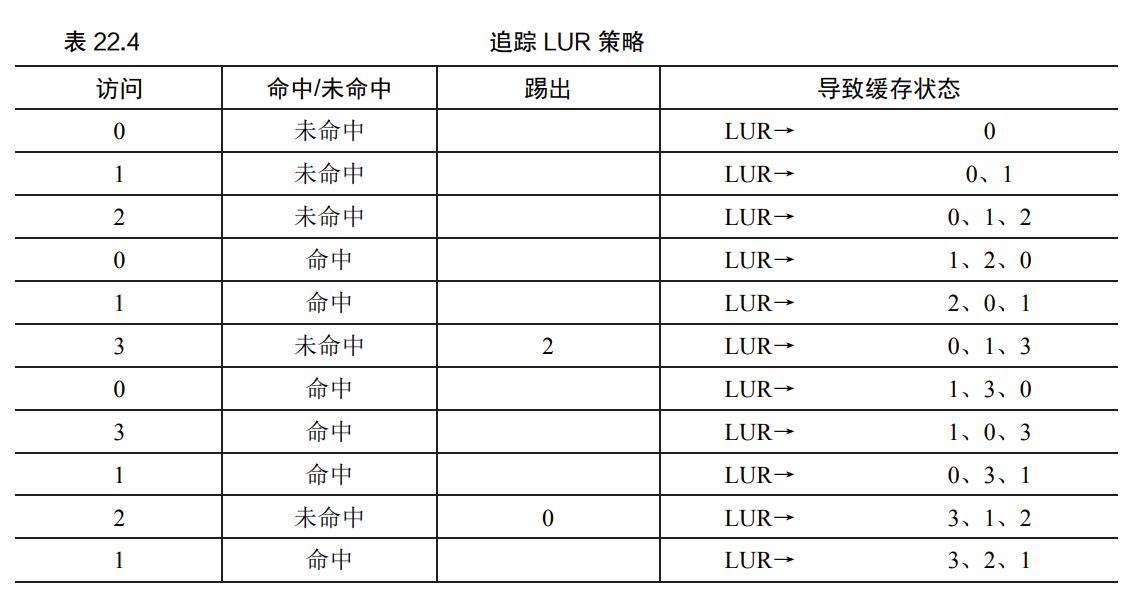
但是顯然的是,LRU會帶來更大的系統開銷,因為我們需要頻繁的將訪問過的頁置于訪問序列的首部,這就需要對訪問隊列的內容進行頻繁的增刪,而FIFO只需要簡單排列即可。
如果說LRU是通過所有頁面的最近使用情況或者說訪問時間來看,那么LFU即通過訪問頻率來決定哪些頁面需要被踢出,根據程序的局部性原則,顯然LFU會帶來更高的緩存命中率,但是考慮到需要記錄頻率并且頻繁的調整隊列,實際上帶來的系統開銷會比LRU更大。
下圖描述了一個LFU的執行過程,大寫字母為相應的頁,圓圈中的數字代表訪問頻率,訪問頻率最低的在隊列的最后,當需要踢出時,優先踢出隊列末尾的頁。
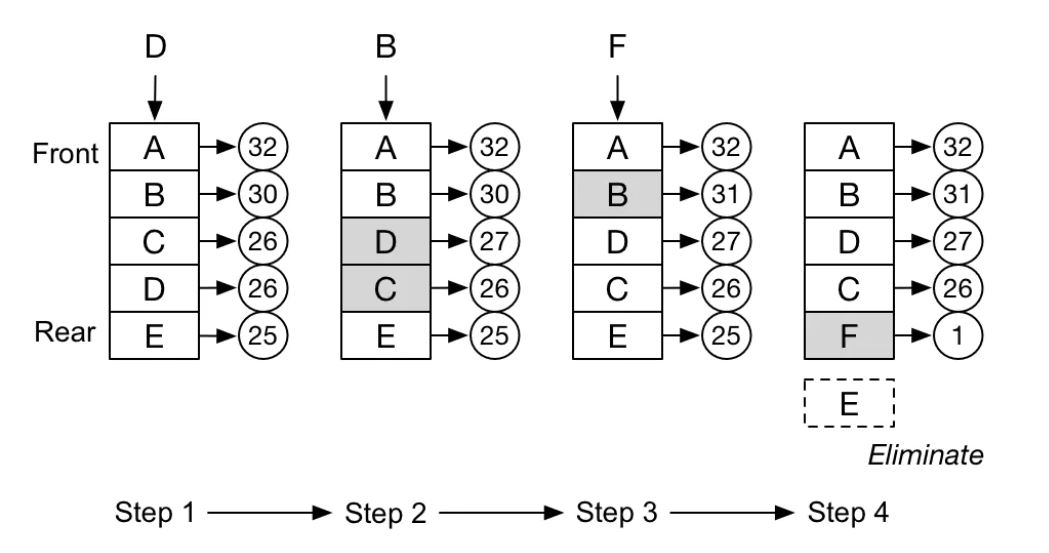
上文談到了LRU和LFU會帶來更高的緩存命中率,但是計算開銷顯然會更大,給系統帶來更高的時間開銷,而一些類LRU算法就出現了,比如時鐘算法。
系統中的所有頁都放在一個循環列表中。時鐘指針(clock hand)開始時指向某個特定的頁(哪個頁不重要)。當必須進行頁替換時,操作系統檢查當前指向的頁P的使用位是1還是0。如果是1,則意味著頁面P最近被使用, 因此不適合被替換。然后,P的使用位設置為0,時鐘指針遞增到下一頁(P+1)。該算法一直持續到找到一個使用位為 0 的頁,使用位為 0 意味著這個頁最近沒有被使用過(在最壞的情況下,所有的頁都已經被使用了,那么就將所有頁的使用位都設置為 0)。

以leetcode146. LRU 緩存機制為例,最直觀樸素的LRU緩存機制可以使用哈希表以及雙向鏈表實現,當然Java的集合LinkedHashMap即實現了一個哈希表+鏈表的組合,可以直接調用實現。
但為了更形象的理解LRU的機制,采用HashMap以及手寫一個雙向鏈表來實現。具體的結構如下圖所示
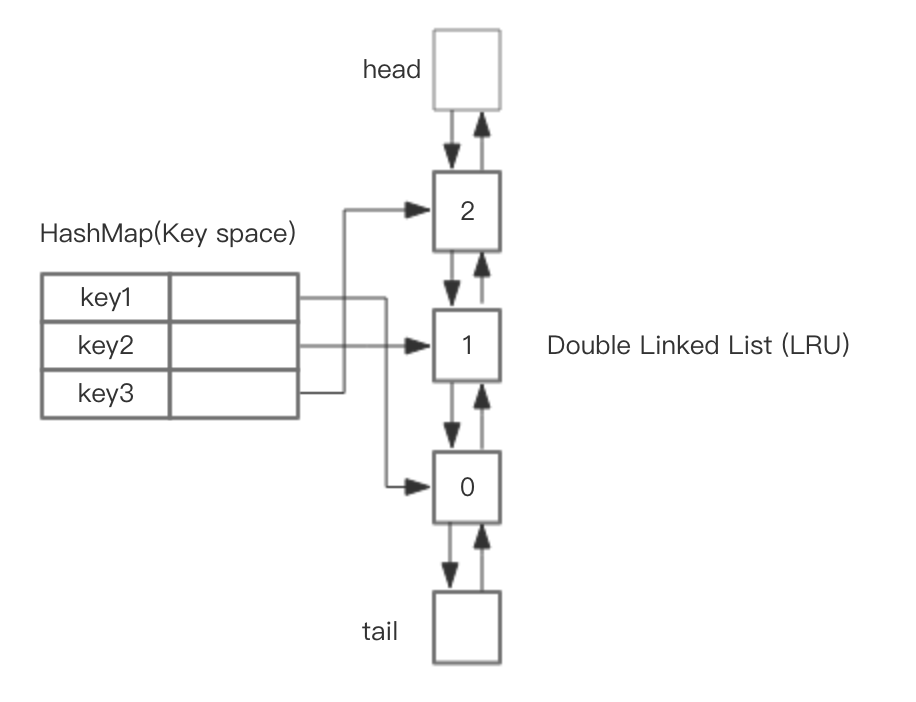
維護一個大小為緩存容量的map,key值為緩存數據的key,value存儲指向相應節點的引用,數據鏈表使用雙向鏈表便于增刪,當訪問到某條數據時,通過map以O(1)復雜度定位到數據的應用,然后
刪除訪問節點
添加訪問節點到隊首
當節點數量>緩存容量時,刪除隊尾元素,同時移除map中的數據,具體實現如下。
public class LRUCache {
class DLinkedNode {
int key, value;
DLinkedNode pre;
DLinkedNode next;
public DLinkedNode(){}
public DLinkedNode(int key, int value){this.key = key; this.value = value;}
}
private Map<Integer, DLinkedNode> cache = new HashMap<>();
private int size;
private int cal;
private DLinkedNode head, tail;
public LRUCache(int capacity) {
size = 0;
cal = capacity;
head = new DLinkedNode();
tail = new DLinkedNode();
head.next = tail;
tail.pre = head;
}
public int get(int key) {
DLinkedNode node = cache.get(key);
if (node == null) {
return -1;
}
moveToHead(node);
return node.value;
}
public void put(int key, int value) {
DLinkedNode node = cache.get(key);
if (node == null) {
DLinkedNode newNode = new DLinkedNode(key, value);
cache.put(key, newNode);
size++;
addToHead(newNode);
if (size > cal) {
DLinkedNode tail = removeTail();
cache.remove(tail.key);
size--;
}
} else {
node.value = value;
moveToHead(node);
}
}
private void moveToHead(DLinkedNode node) {
removeNode(node);
addToHead(node);
}
private void removeNode(DLinkedNode node) {
node.pre.next = node.next;
node.next.pre = node.pre;
}
private void addToHead(DLinkedNode node) {
node.pre = head;
node.next = head.next;
head.next.pre = node;
head.next = node;
}
private DLinkedNode removeTail() {
DLinkedNode realTail = tail.pre;
removeNode(realTail);
return realTail;
}
}上面談到要實現一個樸素的LRU算法,需要維護一個雙向鏈表,存儲前驅、后繼指針,必然會在寸金寸土的緩存(內存)中帶來不必要的開銷。上述提到的時鐘算法就是一種類LRU算法,用更少的系統開銷帶來了接近樸素LRU的命中率。而事實上,Redis中采取的LRU算法也是一種類LRU算法,它也帶來了時鐘算法類似的效果。具體的是Redis通過隨機選取幾個key值,淘汰時間戳最靠前的key,涉及到LRU的淘汰策略maxmemory_policy(這個字段可以選擇不同的緩存淘汰策略,Redis一種提供了8種,本文只分析其中與LRU有關的)的賦值兩種:
allkeys-lru: 對所有的鍵都采取LRU淘汰
volatile-lru: 僅對設置了過期時間的鍵采取LRU淘汰
可以根據實際情況選擇上述兩種LRU淘汰策略,在一般情況下,程序都存在局部性,或者說冪次分布(二八法則),即少數數據比其他大多數數據訪問的更多,所以通常使用allkeys-lru策略,而當有需求需要長期保留一部分數據在內存中時選取volatile-lru即只規定部分需要淘汰的數據。
下面看一下具體是如何設置的,Redis整體上是一個大的字典,key是一個string,而value都會保存為一個robj(Redis Object),對于robj的定義如下
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;其中LRU_BITS即Redis為每個鍵值對配備的一個記錄時間戳的bit位,Redis的LFU替換策略中也使用這個空間,創建對象時會寫入到lru_clock這個字段中,訪問對象時會對其進行更新,具體的空間的大小被定義為一個常量
#define REDIS_LRU_BITS 24
大小為24,即使用一個額外的24bit的空間記錄相對時間戳(即對unix time取模之后的結果),默認的時間戳分辨率是1秒,在這種情況下,24bits的空間如果溢出的話需要194天,而作為頻繁更新的緩存而言,這個空間夠用了。
上面提到了Redis會隨機采樣,比較其訪問時間哪個更靠前,當需要替換時優先踢出采樣結果最靠前的鍵值對,具體的采樣個數在最開始是選取3個key,但是效果并不好,后來增加到N個key,但是默認是5個,即默認隨機選取5個key,最先淘汰掉這5個中距離上次訪問時間最久的,Redis3.0中又改善了算法的性能,即提供了一個采樣池(pool),候選采樣池默認大小為16,能夠填充16個key,更新時從Redis鍵空間隨機選擇N個key,分別計算它們的空閑時間idle,key只會在pool不滿或者空閑時間大于pool里最小的時,才會進入pool,然后從pool中選擇空閑時間最大的key淘汰掉。
具體的這個候選集合結構體如下
struct evictionPoolEntry {
unsigned long long idle; // 用于淘汰排序,在不同算法中意義不同優先淘汰值大的,單位是ms
sds key; // 鍵的名字
// ...
};所以關鍵在pool中的idle字段的計算,實際上只需要使用當前的時間戳減去lru_clock即可,但是所記錄的時間戳都是取模之后的結果,所以還需要比較當前計算出來的時間戳是否大于lru_clock,如果不是,則需要將當前
時間戳+194天(模數)再減去lru_clock。具體的計算過程如下
// 以秒為精度計算對象距離上一次訪問的間隔時間,然后轉化成毫秒返回
unsigned long long estimateObjectIdleTime(robj *o) {
unsigned long long lruclock = LRU_CLOCK();
if (lruclock >= o->lru) {
return (lruclock - o->lru) * LRU_CLOCK_RESOLUTION;
} else {
return (lruclock + (LRU_CLOCK_MAX - o->lru)) *
LRU_CLOCK_RESOLUTION;
}
}另外Redis官方文檔里有對于候選數為5、10在redis2.8無侯選池,以及3.0加侯選池的對比。

四張圖依次是,理論LRU的使用情況、有pool采樣數為10的候選情況、無pool采樣數為5的情況、有pool采樣數為10的情況。其中
綠色部分是新添加的key
灰色部分是最近使用的key淺
灰色部分是替換的key
可以看出采取Redis3.0的采取維護一個候選淘汰池的方法已經能夠接近全局比較情況下也即樸素LRU的結果。
詳細的分析可以參考https://redis.io/topics/lru-cache
此處InnoDB的緩存概念不做過多贅述,只簡單介紹其中LRU的應用,InnoDB會把cpu頻繁使用的數據存儲在主存的緩沖池(Buffer Pool)中,鑒于MySQL在使用過程中存在著經常性的全表掃描,所以如果使用樸素LRU必然會頻繁的大面積替換,造成極低的緩存命中率。
所以InnoDB采取了一種冷熱分離的思路,即將整個緩沖池分為冷區和熱區或者說年輕區(New Sublist)和老區(Old Sublist)
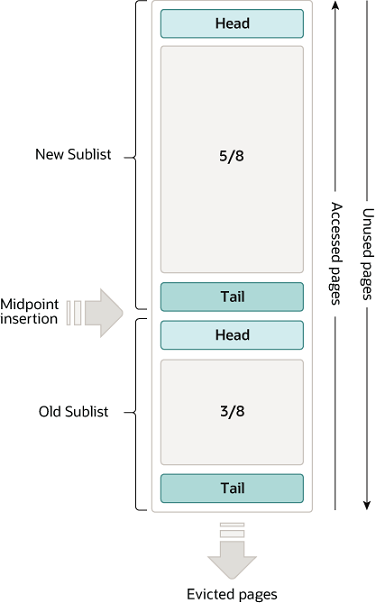
默認情況下距離鏈表尾3/8以上的位置稱為新子列表(熱點區域),以下的位置稱為舊子列表(冷區域),某個頁面初次加載到緩沖池時,放在old區域的頭部。在對某個處于old區域的緩沖頁進行第一次訪問時,就在它對應的控制塊中記錄下這個訪問時間,如果后續的訪問時間和第一次訪問的時間在某個時間間隔內(默認為1000ms),那么該頁面就不會從老的區域移動到年輕區域的頭部,否則將他移動到年輕區域的頭部。
而當緩沖池滿時需要淘汰數據就從old區域的尾部進行淘汰,這樣數據起碼需要兩次(一次為加載到內存,第二次為大于間隔時間的讀取)合理的操作才能移動到年輕區域,有效的預防了全表掃描帶來的命中率降低問題。
關于Redis中怎么使用緩存替換策略問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





