溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“Redis中緩存雪崩、緩存擊穿和緩存穿透的示例分析”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“Redis中緩存雪崩、緩存擊穿和緩存穿透的示例分析”這篇文章吧。

緩存雪崩
緩存擊穿
緩存穿透
相信這三個問題,網上已經有很多的伙伴講過了,但是今天我還是想說下,會多畫圖,讓大家加深印象,這三個問題也高頻的面試題,但是能把這幾個問題說清楚,也是需要技巧的。
再說這三個問題的時候,先說下正常的請求流程,看圖說話:
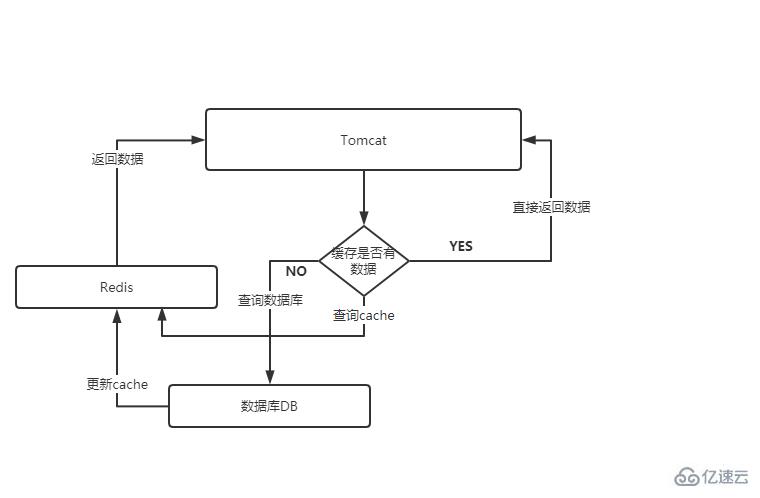
上圖的意思大致如下:
首先會在你的代碼中,可能是tomcat 也可以是你的rpc 服務中,先判斷緩存cache 中是否存在你想要的數據,如果存儲了,那么直接返回給調用端,如果不存在,那么就需要查詢數據庫,查詢出結果來,再繼續緩存到cache中,然后返回結果給調用方,下次再來的查詢的時候,也就命中緩存了。
定義
記得之前在做推薦系統的時候,有些數據是離線算法算出來的,需求是看了這個商品會推薦哪些相似的商品,這個算出來之后會存儲到hbase,同時存儲到redis,由于都是批量算法出來的,再存儲到redis 的時候,如果過期時間設置相同,那么就會造成大批量的key ,在同一時刻失效,那么就會有大批量的請求會被打到后臺的數據庫上,因為數據庫的吞吐量是有限的,很有可能會把數據庫打垮的,這種情況就是緩存雪崩,看圖說話:
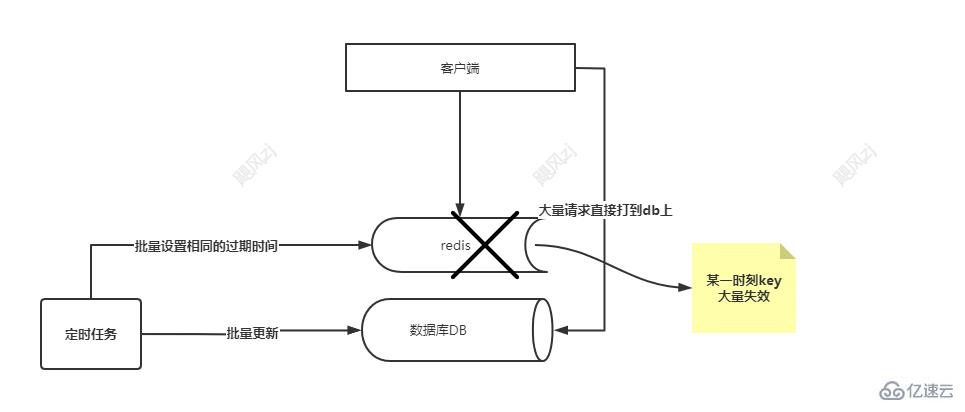
這個主要是說明一個緩存雪崩出現的場景,尤其是定時任務在批量設置cache的時候,一定要注意過期時間的設置。
如何預防雪崩
其實也很簡單,就是在你批量設置cache的緩存時間的時候,給設置的緩存時間,設置一個隨機數(如隨機數可以10分鐘內的數字,隨機數的生成可以用java的Random生成),這樣,就不會出現大量的key,再同一時刻集體失效了,看圖說話:
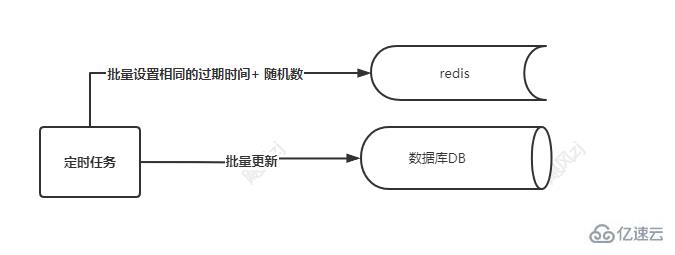
如果真的發生了雪崩怎么辦?
流量不是很大,數據庫能抗住,ok,恭喜你逃過一劫。
流量很大,超過了數據庫所能處理的請求數的極限,數據庫down機了,也恭喜你領了一個P0事故單。
流量很大,如果你的數據庫有限流方案,當達到了限流設置的參數,那么就會拒絕請求,從而保護了后臺db。這里對限流多說幾句。
可以通過設置每秒請求數,來限制大量的請求到達db端,注意這里的每秒請求數,或者說是并發數,并不是數據當前的每秒請求數,可以設置為查詢某個key 對應的每秒請求數量,這樣做的目的,是防止大量相同key的請求到達后端數據庫,這樣就能攔截了大部分請求了。
看圖說話:
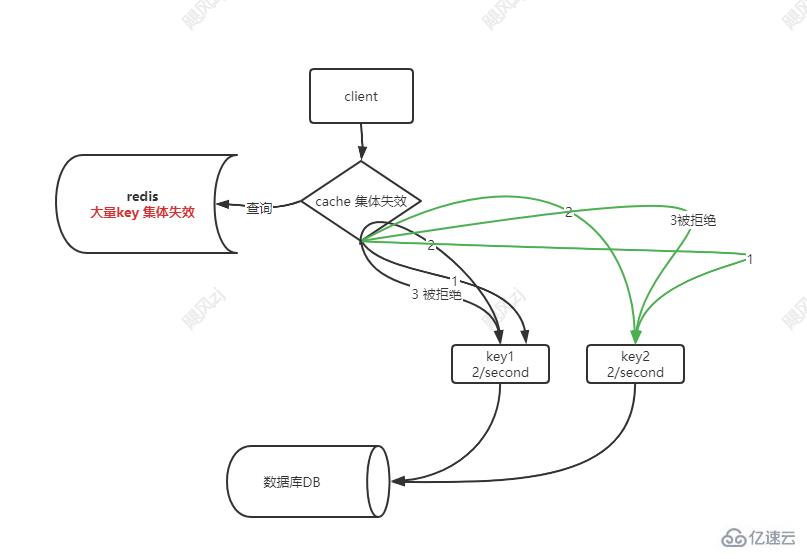
這樣相同的key,就會被限流了大部分請求,從而保護了數據庫db。
其實限流還分為本地限流和分布式限流兩種,后面的文章里,我會 介紹本地限流和redis 實現的分布式限流。
定義
比如在某網站在進行雙十一或者在搞秒殺等運營活動的時候,那么此時網站流量一般都會很大的,某個一個商品因為促銷會成為爆品,流量超級的大,如果這個商品,在這個時候,由于某種原因,在cache內失效了,那么就瞬間這個key的流量都會涌向數據庫了,那么db最終挺不住了,down了,后果可想而知啊,正常其他的數據也查詢不了。
看圖說話:
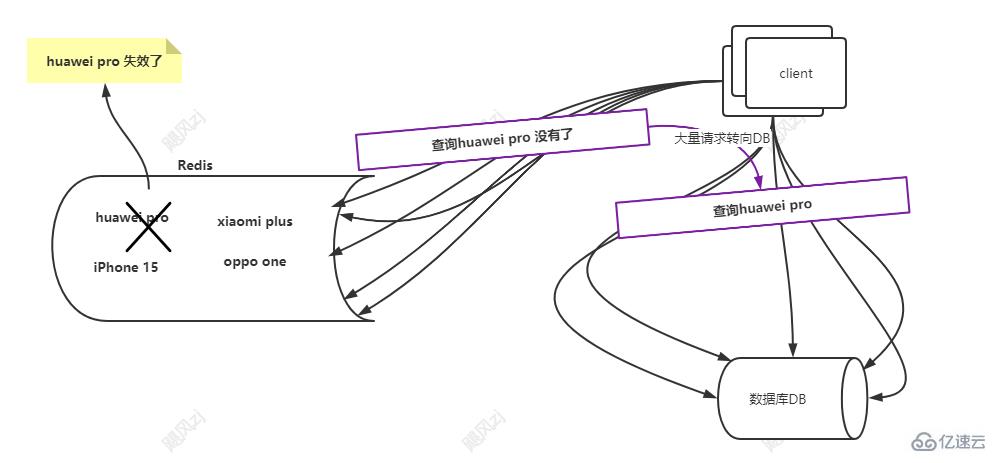
redis 中的huawei pro 這個key 突然失效了,可能是到期了,可能是內存不夠被淘汰了,那么就會有大流量的請求到達redis ,發現redis 沒有這個key,那么這些流量,就會轉到DB 上去,查詢對應的huawei pro,此時DB 挺不住了,down了。
如何解決
其實歸根到底還是不能讓更多的流量到達DB就行了,所以我們就是要限制到達db的流量就可以了。
1、限流
和上面說的類似,主要是限制某個key的流量,當這個key ,被擊穿后,限制只有一個流量進入到db,其他都被拒絕,或者等待重試查詢redis。
限流的圖可以參考緩存擊穿限流的圖。
這里也會分本地限流和分布式限流 。
何為本地限流,就是在本地單個實例范圍內,限制這個key的流量多少,只對當前實例有效。
何為分布式限流呢,就是在分布式的環境下,多個實例的范圍內,這個key的限制流量的累加是來自多個實例的流量,達到限制,所有的實例都會限制流量到達DB。
2、利用分布式鎖
這里簡單說下分布式鎖的定義,在并發場景下,需要使用鎖對共享資源互斥訪問來保證線程安全;同樣,在分布式場景下,也需要一種機制來保證對多節點共享資源的互斥訪問,實現機制就是分布式鎖。
在這里共享資源就是例子中的huawei pro,也就是在訪問db中的huawei pro 的時候,要保證只有一個線程或者一個流量去訪問,就達到了分布式鎖的效果。
看圖說話:
去搶鎖:
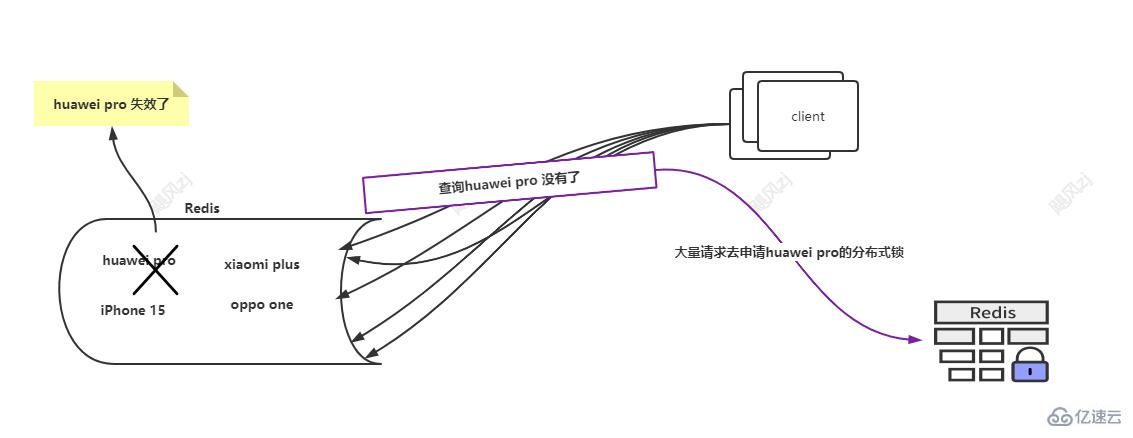
大量請求在沒有獲取到huawei pro 這個key的值后,準備去db獲取數據,此時獲取db的代碼加了分布式鎖,那么每個請求,也是每個線程都會去獲取huawei pro 的分布式鎖(圖中利用redis實現了分布式鎖,后面我會有單獨一篇文章來介紹分布式鎖的實現,不限于redis)。
獲取鎖之后:
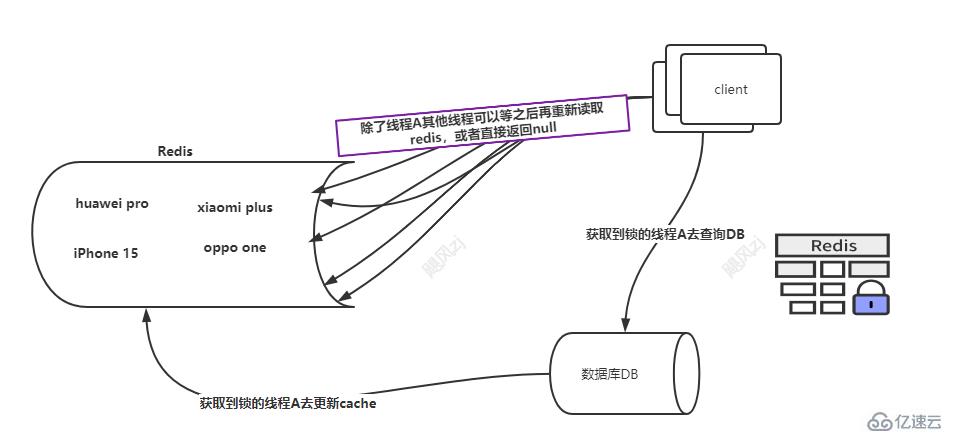
此時線程A獲取了huawei pro 的分布式鎖,那么線程A就會去DB加載數據,然后由線程A將huawei pro 再次設置到cache內,然后返回數據。
其他的線程就沒有獲取到,一種方式就是直接返回空值給客戶端,還有一種等待50-100ms ,因為查詢db和放入redis 會很快,此時等待,再次查詢的時候,結果可能就有了,如果沒有就直接返回null,當然也可以重試,當然在大并發的場景下,還是希望能夠快速的返回結果,不能發生太多次數的重試操作。
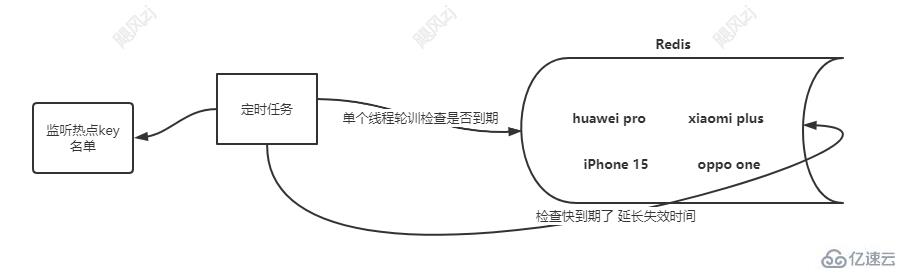
3、定時任務更新熱點key
這個就很好理解,說白了,就是一個定時任務定時的去監控某些熱點key的超時時間,是否到期,再進行快到期了的時候延長key在cache中的緩存時間就可以了。
單個線程輪詢的方式檢查和更新失效時間,看圖:
多線程的方式,注意熱點的key 不能太多,某個線程會開啟很多,如果熱點key很多,可以采用線程池的方式,看圖:
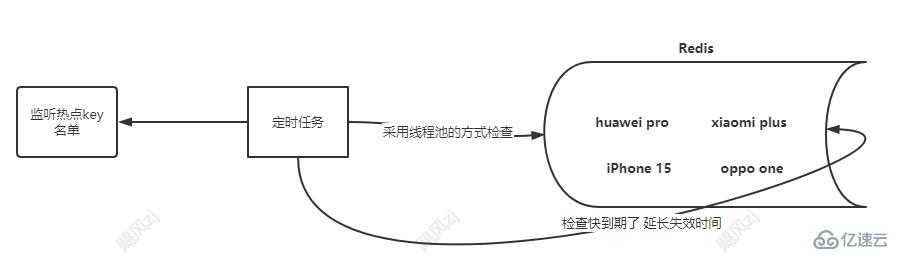
延遲隊列實現
上面的方式說白了,無論是單個線程還是多個線程,都是會采用輪詢的方式(每次白白浪費的cpu),來檢查是否key 快到期了,這種方式檢查會存在檢查時間不準確,可能會造成時間的延遲或者不準確,你在等待進行下次檢查的時候,這個key就沒了,那么此時就已經發了擊穿,這個情況的發生雖然概率低,但也是有的,那么我們怎么才能避免呢,其實咱們可以利用延遲隊列(環形隊列來實現,這里我不深入講這個隊列的原理了,大家可以自行百度或者google),所謂的延遲隊列就是你往這個隊列發送消息,希望按照你設置的時間來進行消費,時間沒到不會進行消費,時間到了就進行消費,好了,看圖說話吧:
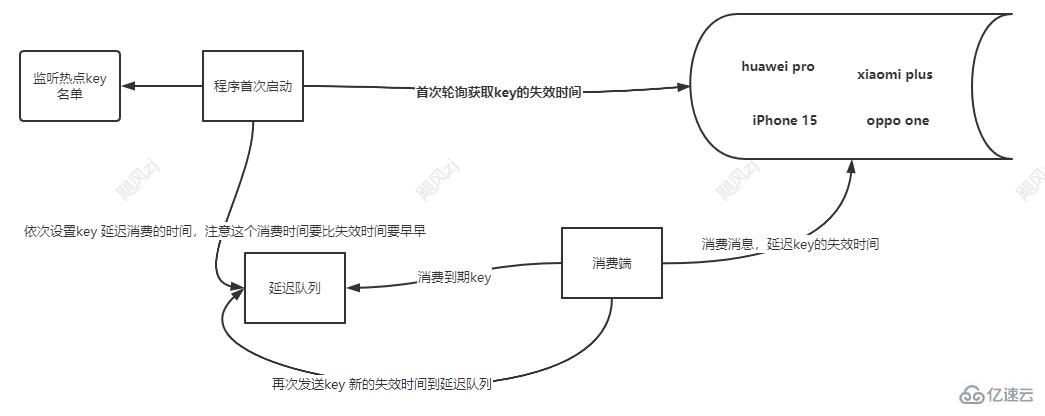
1、程序首次啟動 獲取名單內key的失效時間。
2、依次設置key 延遲消費的時間,注意這個消費時間要比失效時間要早。
3、延遲隊列到期,消費端進行消費key。
4、消費端消費消息,延遲key的失效時間到cache。
5、再次發送key 新的失效時間到延遲隊列,等待下次延遲cache的失效時間。
4、設置key 不失效
這種其實也可能會因為內存不足,key 被淘汰,大家可以想想什么情況下,key 會被淘汰。
定義
所謂穿透,就是訪問了一個cache不存在,數據庫里也不存在的key,那么此時相當于流量直接到達了DB 了,那么一些流氓就可以利用這個漏洞,瘋狂的刷你的接口,進而把你的DB打垮,你的業務也就不能正常運行了。
如何解決呢?
1、設置null 或者特殊值
我們可以通過設置null 或者特定的值到redis內,且不過期,那么下次再來的時候,直接從redis 獲取這個null 或者 特殊值就可以了。
這個方案不能解決根本性的問題,如果這個流量能仿造出大量的無用key,你設置再多的null或者特殊的值都是沒有用的,那么我們應該怎么解決呢?
2、布隆過濾器
布隆過濾器 英文為 bloomfiler,這里我們只是做簡單的介紹,介于篇幅的原因,后面會有單獨的文章做介紹。
舉個例子,如果我們數據庫里存儲著千萬級別的sku 數據,我們現在的需求是如果庫有這個sku,那么就查詢redis ,如果redis 沒有就查詢數據庫,然后更新redis,我們最先想到的就是把sku數據放入到一hashmap內,key 就是sku,因為sku 的數量很多,那么這個hashmap占用的內存空間會很大,有可能會撐爆內存,最后得不償失了,那么怎么來節省內存,我們可以利用一個bit的數組,來存儲這個sku是否存在狀態,0 代表不存在,1 代表存在,我們可以利用一個散列函數,算出sku的散列值,然后sku的散列值對bit數組進行取模,找到所在數組的位置,然后設置為1,當請求來的時候,我們會算出這個sku 散列值對應的數組位置是否為1 ,為1 說明就存在,為0 說明就不存在。這樣一個簡單的bloomfilter就實現了,bloomfiler 是有錯誤率,可以考慮增加數組長度和散列函數的數量來提供準確率,具體可以百度或者google,今天在這里就不講了。
下面看看利用bloomfiler 來防止緩存穿透的流程,看圖說話:
bloomfiler的初始化 可以通過一個定時任務來讀取 db,初始化bit數組的大小,默認值都是為0,表示不存在,然后每條都計算散列值對應的數組位置,然后插入到bit 數組中。

請求流程,看圖:
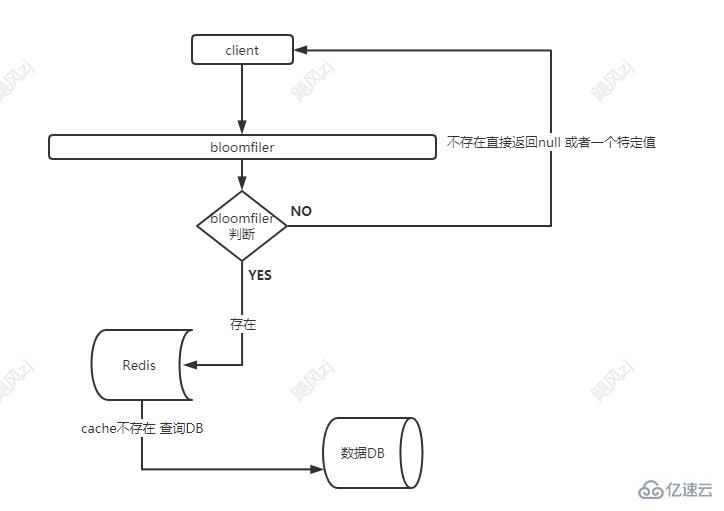
如果不利用bloomfiler 過濾器,對于一個數據庫里根本不存在的key,其實白白浪費了兩次IO,一次查詢redis,一次查詢DB,有了bloomfiler ,那么就節省了這兩次無用的IO,減少后端redis 和 DB 資源的浪費。
緩存雪崩
解決方案:
在設置失效時間段的時候,加上一個時間的隨機數,可以幾分鐘之內的都可以。
以及如果真的雪崩了怎么辦的問題,可以采用限流的方式。
緩存擊穿
解決方案:
限流
分布式鎖
定時更新熱點key ,這里重點看下延遲隊列。
設置時間不失效
緩存穿透
解決方案:
設置null 或者特定的值到redis
使用bloomfiler實現
以上是“Redis中緩存雪崩、緩存擊穿和緩存穿透的示例分析”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





