溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關基于redis如何實現限流策略,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
在web開發中功能是基石,除了功能以外運維和防護就是重頭菜了。因為在網站運行期間可能會因為突然的訪問量導致業務異常、也有可能遭受別人惡意攻擊
所以我們的接口需要對流量進行限制。俗稱的QPS也是對流量的一種描述
針對限流現在大多應該是令牌桶算法,因為它能保證更多的吞吐量。除了令牌桶算法還有他的前身漏桶算法和簡單的計數算法
下面我們來看看這四種算法
固定時間窗口算法也可以叫做簡單計數算法。網上有很多都將計數算法單獨抽離出來。但是筆者認為計數算法是一種思想,而固定時間窗口算法是他的一種實現
包括下面滑動時間窗口算法也是計數算法的一種實現。因為計數如果不和時間進行綁定的話那么失去了限流的本質了。就變成了拒絕了
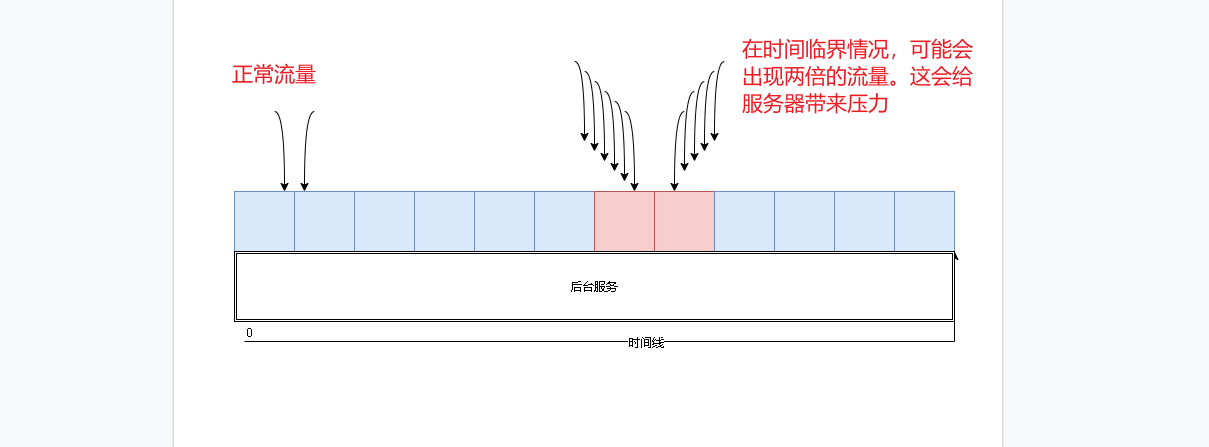
優點:
在固定的時間內出現流量溢出可以立即做出限流。每個時間窗口不會相互影響
在時間單元內保障系統的穩定。保障的時間單元內系統的吞吐量上限
缺點:
正如圖示一樣,他的最大問題就是臨界狀態。在臨界狀態最壞情況會受到兩倍流量請求
除了臨界的情況,還有一種是在一個單元時間窗內前期如果很快的消耗完請求閾值。那么剩下的時間將會無法請求。這樣就會因為一瞬間的流量導致一段時間內系統不可用。這在互聯網高可用的系統中是不能接受的。
實現:
好了,關于原理介紹及優缺點我們已經了解了。下面我們動手實現它
首先我們在實現這種計數時,采用redis是非常好的選擇。這里我們通過redis實現
controller
@RequestMapping(value = "/start",method = RequestMethod.GET)
public Map<string,object> start(@RequestParam Map<string, object=""> paramMap) {
return testService.startQps(paramMap);
}service
@Override
public Map<string, object=""> startQps(Map<string, object=""> paramMap) {
//根據前端傳遞的qps上線
Integer times = 100;
if (paramMap.containsKey("times")) {
times = Integer.valueOf(paramMap.get("times").toString());
}
String redisKey = "redisQps";
RedisAtomicInteger redisAtomicInteger = new RedisAtomicInteger(redisKey, redisTemplate.getConnectionFactory());
int no = redisAtomicInteger.getAndIncrement();
//設置時間固定時間窗口長度 1S
if (no == 0) {
redisAtomicInteger.expire(1, TimeUnit.SECONDS);
}
//判斷是否超限 time=2 表示qps=3
if (no > times) {
throw new RuntimeException("qps refuse request");
}
//返回成功告知
Map<string, object=""> map = new HashMap<>();
map.put("success", "success");
return map;
}結果測試:
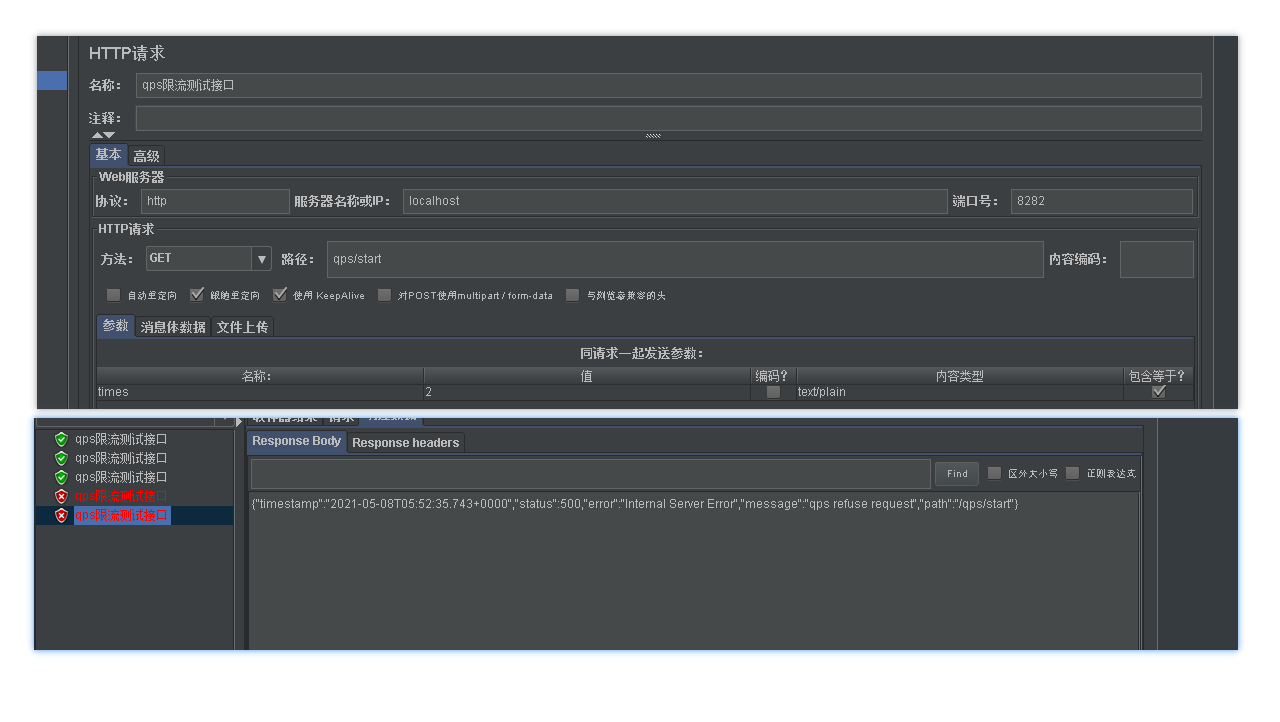
我們設置的qps=3 , 我們可以看到五個并發進來后前三個正常訪問,后面兩個就失敗了。稍等一段時間我們在并發訪問,前三個又可以正常訪問。說明到了下一個時間窗口
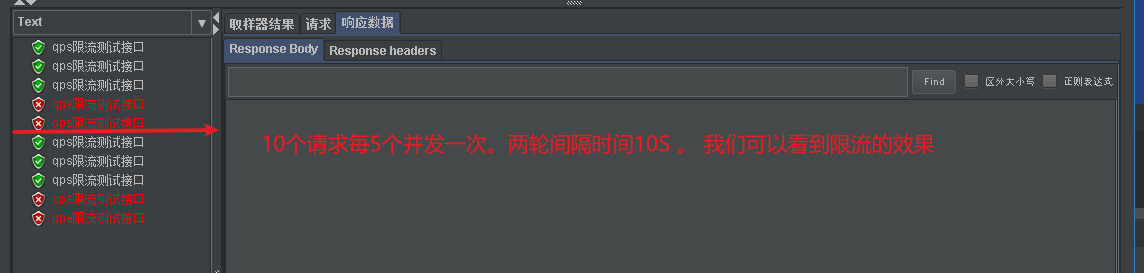
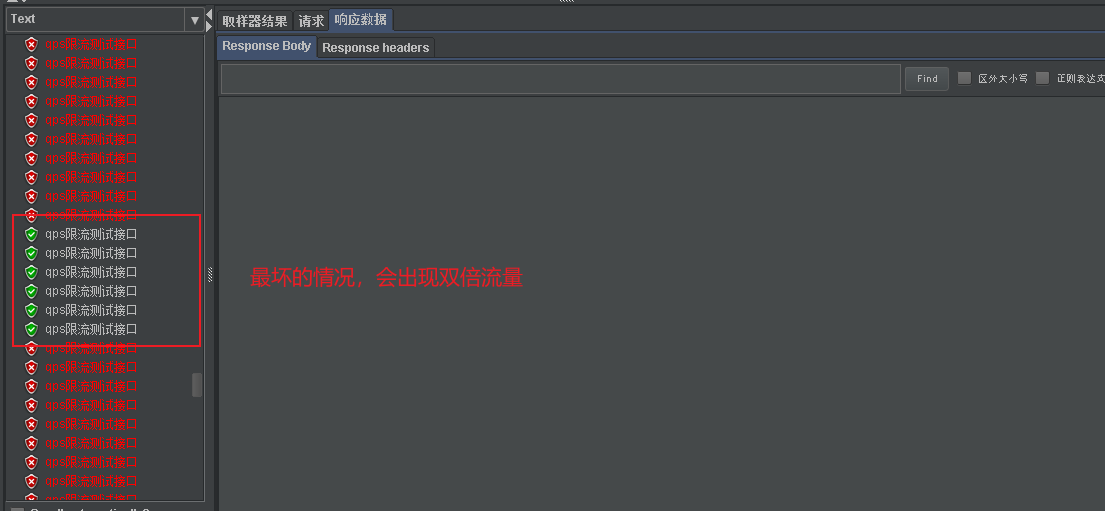
針對固定時間窗口的缺點--臨界值出現雙倍流量問題。 我們的滑動時間窗口就產生了。
其實很好理解,就是針對固定時間窗口,將時間窗口統計從原來的固定間隔變成更加細度化的單元了。
在上面我們固定時間窗口演示中我們設置的時間單元是1S 。 針對1S我們將1S拆成時間戳。
固定時間窗口是統計單元隨著時間的推移不斷向后進行。而滑動時間窗口是我們認為的想象出一個時間單元按照相對論的思想將時間固定,我們的抽象時間單元自己移動。抽象的時間單元比實際的時間單元更小。
讀者可以看下下面的動圖,就可以理解了。

優點:
實質上就是固定時間窗口算法的改進。所以固定時間窗口的缺點就是他的優點。
內部抽象一個滑動的時間窗,將時間更加小化。存在邊界的問題更加小。客戶感知更弱了。
缺點:
不管是固定時間窗口算法還是滑動時間窗口算法,他們都是基于計數器算法進行優化,但是他們對待限流的策略太粗暴了。
為什么說粗暴呢,未限流他們正常放行。一旦達到限流后就會直接拒絕。這樣我們會損失一部分請求。這對于一個產品來說不太友好
實現:
滑動時間窗口是將時間更加細化,上面我們是通過redis#setnx實現的。這里我們就無法通過他統一記錄了。我們應該加上更小的時間單元存儲到一個集合匯總。然后根據集合的總量計算限流。redis的zsett數據結構就和符合我們的需求。
為什么選擇zset呢,因為redis的zset中除了值以外還有一個權重。會根據這個權重進行排序。如果我們將我們的時間單元及時間戳作為我們的權重,那么我們獲取統計的時候只需要按照一個時間戳范圍就可以了。
因為zset內元素是唯一的,所以我們的值采用uuid或者雪花算法一類的id生成器
controller
@RequestMapping(value = "/startList",method = RequestMethod.GET)
public Map<string,object> startList(@RequestParam Map<string, object=""> paramMap) {
return testService.startList(paramMap);
}service
String redisKey = "qpsZset";
Integer times = 100;
if (paramMap.containsKey("times")) {
times = Integer.valueOf(paramMap.get("times").toString());
}
long currentTimeMillis = System.currentTimeMillis();
long interMills = inter * 1000L;
Long count = redisTemplate.opsForZSet().count(redisKey, currentTimeMillis - interMills, currentTimeMillis);
if (count > times) {
throw new RuntimeException("qps refuse request");
}
redisTemplate.opsForZSet().add(redisKey, UUID.randomUUID().toString(), currentTimeMillis);
Map<string, object=""> map = new HashMap<>();
map.put("success", "success");
return map;結果測試:
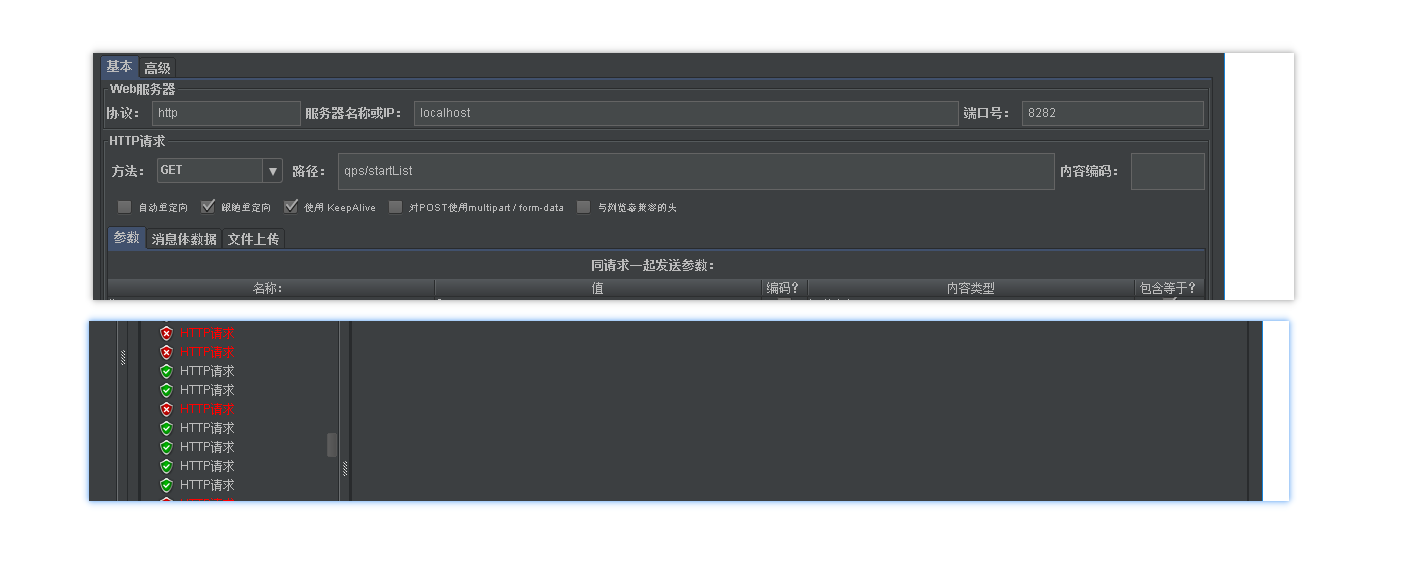
和固定時間窗口采用相同的并發。為什么上面也會出現臨界狀況呢。因為在代碼里時間單元間隔比固定時間間隔采用還要大 。 上面演示固定時間窗口時間單元是1S出現了最壞情況。而滑動時間窗口設計上就應該間隔更短。而我設置成10S 也沒有出現壞的情況
這里就說明滑動比固定的優處了。如果我們調更小應該更加不會出現臨界問題,不過說到底他還是避免不了臨界出現的問題
滑動時間窗口雖然可以極大程度的規避臨界值問題,但是始終還是避免不了
另外時間算法還有個致命的問題,他無法面對突如其來的大量流量,因為他在達到限流后直接就拒絕了其他額外流量
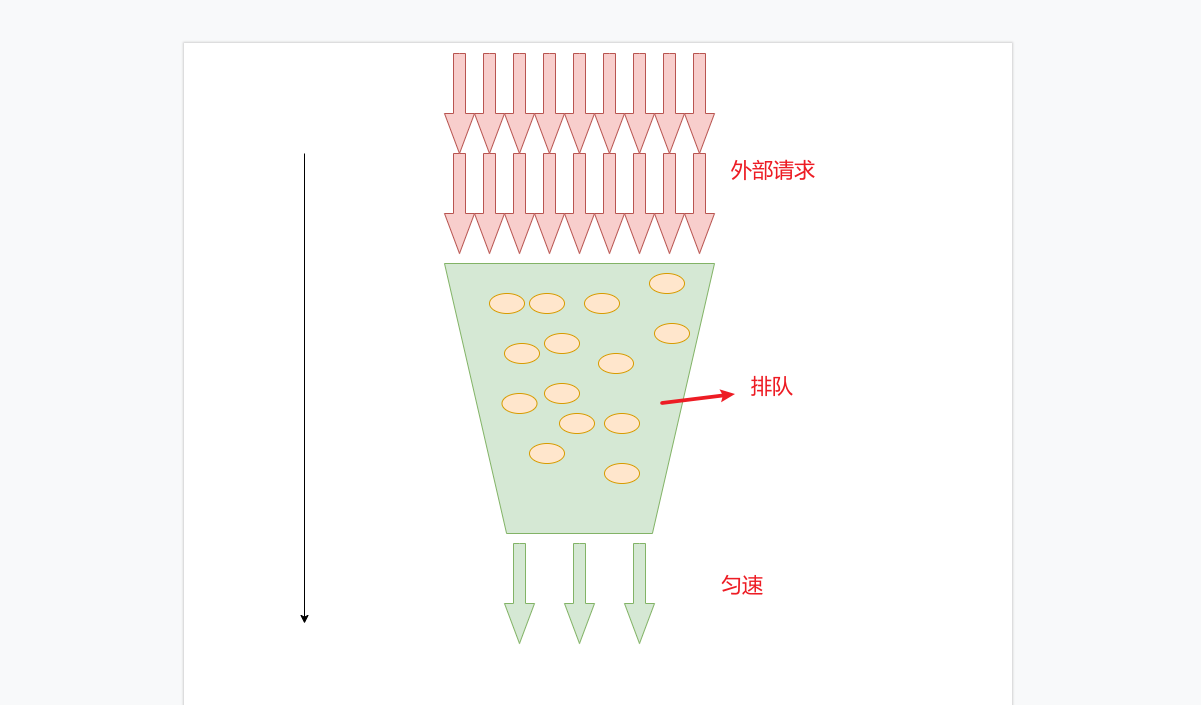
針對這個問題我們繼續優化我們的限流算法。 漏桶算法應運而生
優點:
面對限流更加的柔性,不在粗暴的拒絕。
增加了接口的接收性
保證下流服務接收的穩定性。均勻下發
缺點:
我覺得沒有缺點。非要雞蛋里挑骨頭那我只能說漏桶容量是個短板
實現:
controller
@RequestMapping(value = "/startLoutong",method = RequestMethod.GET)
public Map<string,object> startLoutong(@RequestParam Map<string, object=""> paramMap) {
return testService.startLoutong(paramMap);
}service在service中我們通過redis的list的功能模擬出桶的效果。這里代碼是實驗室性質的。在真實使用中我們還需要考慮并發的問題
@Override
public Map<string, object=""> startLoutong(Map<string, object=""> paramMap) {
String redisKey = "qpsList";
Integer times = 100;
if (paramMap.containsKey("times")) {
times = Integer.valueOf(paramMap.get("times").toString());
}
Long size = redisTemplate.opsForList().size(redisKey);
if (size >= times) {
throw new RuntimeException("qps refuse request");
}
Long aLong = redisTemplate.opsForList().rightPush(redisKey, paramMap);
if (aLong > times) {
//為了防止并發場景。這里添加完成之后也要驗證。 即使這樣本段代碼在高并發也有問題。此處演示作用
redisTemplate.opsForList().trim(redisKey, 0, times-1);
throw new RuntimeException("qps refuse request");
}
Map<string, object=""> map = new HashMap<>();
map.put("success", "success");
return map;
}下游消費
@Component
public class SchedulerTask {
@Autowired
RedisTemplate redisTemplate;
private String redisKey="qpsList";
@Scheduled(cron="*/1 * * * * ?")
private void process(){
//一次性消費兩個
System.out.println("正在消費。。。。。。");
redisTemplate.opsForList().trim(redisKey, 2, -1);
}
}測試:
我們還是通過50并發循環10次訪問。我們可以發現只有在一開始能達到比較高的吞吐量。在隨后桶的容量滿了之后。而下游水滴速率比上游請求速率慢的情況下。只能以下游恒定的速度接收訪問。
他的問題也暴露的很明顯。針對時間窗口的不足漏桶進行的不足,但是仍是不足。無法徹底避免請求溢出的問題。
請求溢出本身就是一種災難性的問題。所有的算法目前都沒有解決這個問題。只是在減緩他帶來的問題
令牌桶和漏桶法是一樣的。只不過將桶的作用方向改變了一下。
漏桶的出水速度是恒定的,如果流量突然增加的話我們就只能拒絕入池
但是令牌桶是將令牌放入桶中,我們知道正常情況下令牌就是一串字符當桶滿了就拒絕令牌的入池,但是面對高流量的時候正常加上我們的超時時間就留下足夠長的時間生產及消費令牌了。這樣就盡可能的不會造成請求的拒絕
最后,不論是對于令牌桶拿不到令牌被拒絕,還是漏桶的水滿了溢出,都是為了保證大部分流量的正常使用,而犧牲掉了少部分流量
public Map<string, object=""> startLingpaitong(Map<string, object=""> paramMap) {
String redisKey = "lingpaitong";
String token = redisTemplate.opsForList().leftPop(redisKey).toString();
//正常情況需要驗證是否合法,防止篡改
if (StringUtils.isEmpty(token)) {
throw new RuntimeException("令牌桶拒絕");
}
Map<string, object=""> map = new HashMap<>();
map.put("success", "success");
return map;
}@Scheduled(cron="*/1 * * * * ?")
private void process(){
//一次性生產兩個
System.out.println("正在消費。。。。。。");
for (int i = 0; i < 2; i++) {
redisTemplate.opsForList().rightPush(redisKey, i);
}
}關于“基于redis如何實現限流策略”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





